- 论文: Attention Is All You Need
- 时间: 2017年6月
- 作者: Ashish Vaswani 等八人(Google)
2017年6月,来自谷歌的八位研究者在 arXiv 上发表了一篇论文,标题简单直接,甚至有些狂妄——《Attention Is All You Need》(注意力就是你所需要的全部)。
后来的故事我们都知道,他们没有吹牛。这篇论文提出的 Transformer 架构,成为了今天所有大语言模型的基石。无论是 GPT、BERT,还是 Claude、Gemini、LLaMA,其核心无一例外都是 Transformer 或其变体。如果说 AlexNet 点燃了深度学习的燎原之火,那么 Transformer 则开启了大模型时代恢弘的序幕。
从串行到并行:RNN的瓶颈
在 Transformer 诞生之前,处理文本、语音这类序列数据的主流方法是循环神经网络(RNN)及其改进版 LSTM、GRU。
RNN 的工作方式很直观:像我们读书一样,一个词接着一个词地读入,每读一个词就更新一下自己的内部“记忆”。等读完整个句子,这个记忆就包含了句子的全部信息。
但这种“顺序处理”模式有个致命缺陷:无法并行计算。处理第10个词,必须等前9个词算完;处理第100个词,前99个词是绕不过去的坎。无论你有多少块 GPU,计算都得老老实实地串行进行。
长序列训练因此变得异常缓慢。更棘手的是,尽管理论上 RNN 能捕捉任意长度的依赖关系,但现实中,当两个词相隔甚远时,它们之间的联系在信息传递过程中极易衰减或丢失。虽然之前提到的 Attention 机制(如用于机器翻译的 seq2seq + Attention)能缓解这个问题,但在那个时代,Attention 只是 RNN 的“辅助”,帮它更好地“回头看”,RNN 仍是绝对的主角。
Transformer 的颠覆性正在于此:它彻底抛弃了 RNN,宣称“Attention Is All You Need”。
核心革命:自注意力机制
Transformer 的核心是 “自注意力”(Self-Attention) 机制。简单来说,它允许序列中的每个位置直接“看到”并关注所有其他位置,并计算它们之间的关联强度。
举个例子:在句子 “The animal didn't cross the street because it was too tired” 中,“it” 指的是什么?是 “animal” 还是 “street”?
人类凭借常识能立刻判断“it”指的是“animal”(因为“tired”是形容动物的)。但对于顺序处理的 RNN 来说,“it”和“animal”之间隔着好几个词,要建立这种远程关联并不容易。
自注意力机制让“it”这个词可以直接与句子中的每一个词(包括它自己)进行关联计算。它会发现,“it”和“animal”的关联度非常高,而和“street”的关联度很低,从而准确理解指代关系。
这个过程可以通过 Query(查询)、Key(键)、Value(值) 三个矩阵来形象描述:
- Query:可以理解为当前词(比如“it”)提出的问题:“我应该关注谁?”
- Key:可以看作是序列中所有词(包括“it”自己)提供的“标签”或“索引”。
- Value:是每个词所承载的实质信息。
计算时,用当前词的 Q 去和序列中所有词的 K 进行匹配(计算点积),得到一组“注意力分数”。这些分数经过 Softmax 归一化后,成为权重,再对所有词的 V 进行加权求和,最终得到当前词新的、融合了全局信息的表示。
关键在于,这个过程可以完全并行化! 所有词的 Q、K、V 矩阵可以同时计算,所有词对之间的注意力分数也可以同时计算。模型不再需要等待前一个词的处理结果。
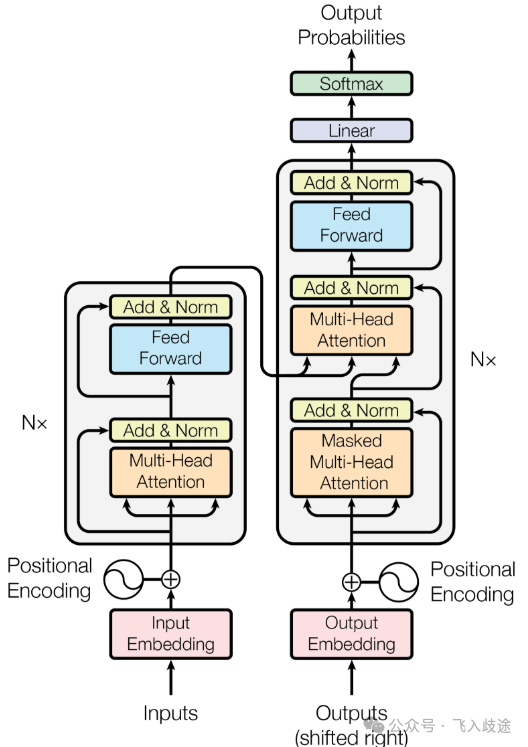
Transformer 模型架构图,展示了其编码器-解码器结构以及核心的多头注意力模块。
除了自注意力,Transformer 还引入了几个关键设计:
- 多头注意力(Multi-Head Attention):单一的注意力头可能只擅长捕捉一种类型的关系(例如语法结构)。多头注意力并行运行多个独立的注意力机制(论文中用了8个头),让它们各自学习不同类型的关系(如语法、语义、指代等),最后将结果拼接起来,极大地增强了模型的表征能力。
- 位置编码(Positional Encoding):由于自注意力本身不考虑词序,Transformer 需要显式地告诉模型每个词的位置信息。这是通过为每个位置添加一个独特的“位置向量”实现的。
- 前馈神经网络(Feed-Forward Network):在注意力层之后,每个位置会独立地通过一个前馈网络进行非线性变换,进一步增强特征。
- 残差连接(Residual Connection)与层归一化(Layer Normalization):这些技术有助于稳定和加速深度网络的训练,使得堆叠多层的 Transformer 成为可能。原论文的模型就包含了6层编码器和6层解码器。
影响深远:不止于翻译
Transformer 在机器翻译任务上表现卓越,大幅超越了之前的 RNN 模型。但更深远的影响在于其极高的训练效率和卓越的扩展性(Scaling)。
论文中提到,Transformer 在8块 P100 GPU 上仅训练3.5天就达到了当时的顶尖翻译水平。效率的提升意味着研究者可以用同样的资源训练更大的模型,或进行更快的迭代,这在 AI 研究中往往是突破的关键。
后来的发展印证了 Transformer 可怕的扩展能力:模型越大、数据越多、训练越久,其性能提升似乎没有明显的天花板。这直接为 GPT-3、GPT-4 等千亿、万亿参数模型的涌现铺平了道路。
这篇论文的八位作者也纷纷成为 AI 领域的弄潮儿,联合创立了 Cohere、Character.AI、Sakana AI、Inceptive 等诸多知名公司,堪称“创业者摇篮”。
Transformer 的成功,可以归结为几点:
- 彻底的并行化:完美适配 GPU 等现代硬件的并行计算架构,实现了前所未有的训练效率。
- 强大的远程依赖捕捉能力:自注意力机制让模型能够直接建立任意两个位置间的关联,解决了 RNN 的长程依赖难题。
- 统一的架构范式:Transformer 的出现,开始改变 AI 领域“图像用 CNN、序列用 RNN”的碎片化局面。它不仅统治了 NLP,还迅速扩展到计算机视觉(ViT)、语音识别、蛋白质结构预测(AlphaFold)、图像生成(DiT)等几乎一切领域,形成“一统江湖”之势。
- 中了“硬件彩票”:其计算模式与硬件发展浪潮高度同频,使得 scaling law(缩放定律)在它身上表现得淋漓尽致。
可以说,Transformer 不仅仅是一个模型架构,它更是一种新的计算范式和思考方式,深刻重塑了过去七年的 人工智能 发展轨迹。对技术史感兴趣的朋友,可以到 云栈社区 的 AI 板块,与更多同行一起探讨这些改变世界的论文与技术细节。
原论文地址:Attention Is All You Need. https://arxiv.org/abs/1706.03762
 发表于 2026-3-20 09:25:28
|
查看: 146|
回复: 0
发表于 2026-3-20 09:25:28
|
查看: 146|
回复: 0
