跟随前辈的学习分析,对某 sec.so 进行了反调试机制的剖析。其反调试手段主要集中在对 /proc 文件系统信息的检查以及更深层的 linker 私有结构遍历上。
具体检测面包括:
- 使用
/proc/<pid>/status 检查 TracerPid
- 使用
/proc/<pid>/task/<tid>/status/stat 检查线程状态和线程名
- 使用
/proc/self/maps、/proc/self/fd 检查 Frida 注入痕迹
- 辅以
linker 私有结构遍历,进行更底层的模块探测
已有分析可以确认,这个 so 在初始化阶段会拉起多条保护链,其中与 Frida 直接相关的一条会扫描线程列表,检查线程状态,并匹配 Frida 的常见线程名。
典型的目标线程名包括:
一旦命中,样本要么直接触发退出,要么进入更激进的异常路径,最终导致进程崩溃。
本文的重点在于探讨一种内核层的绕过方案:
- 在内核中拦截
/proc 相关输出
- 在目标进程读取
/proc/<pid>/task/<tid>/status 时,临时篡改 task_struct->comm
- 从源头隐藏 Frida 线程名,使其无法被用户态检测逻辑发现
可以先通过一张总览图了解本文涉及的所有检测与绕过面:
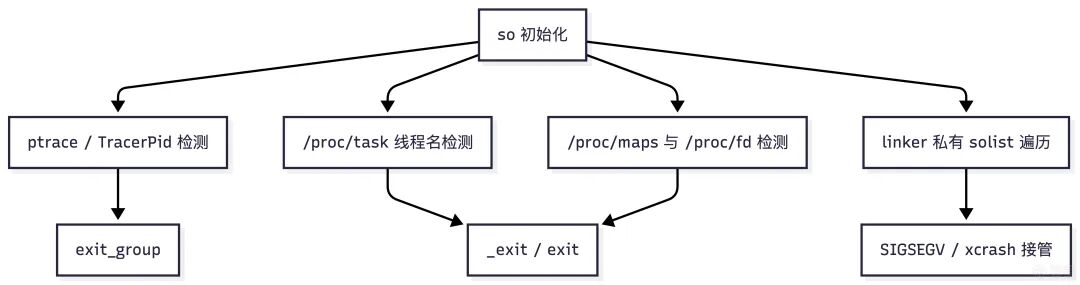
反调试机制分析
详细的静态分析借助了 Agent 工具 Codex 与 Tenrec(IDA 的 MCP)进行,不得不感叹 AI 正在彻底改变 逆向工程 的分析方式。
完整的反调试机制可用下图概括:
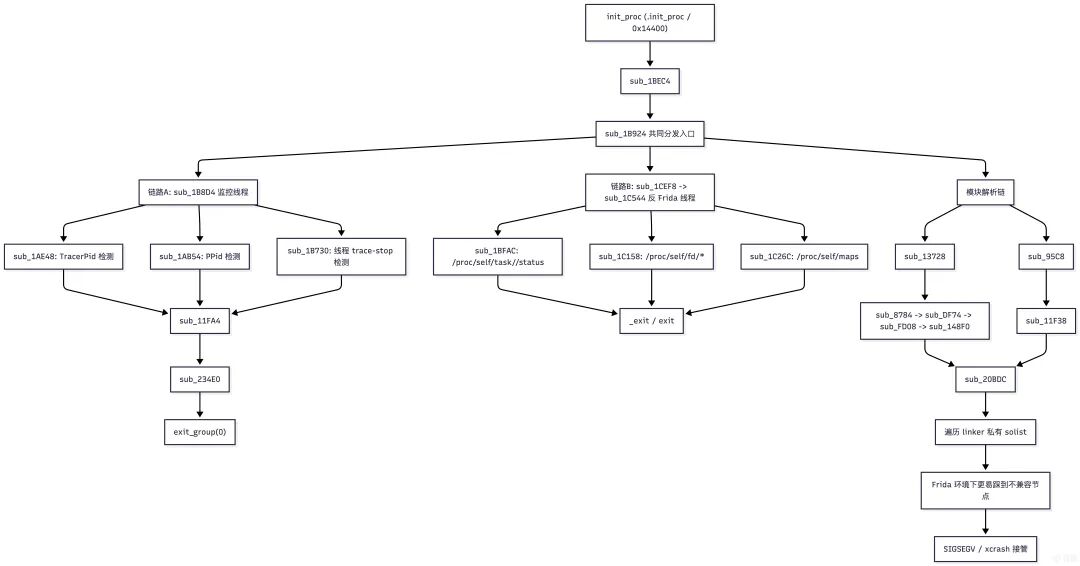
两条主检测链
目前最准确的整理方式是:
init_proc -> sub_1BEC4 -> sub_1B924 是共同的初始化/分发入口。- 真正进入持续检测并最终触发退出的,是
sub_1B8D4 和 sub_1C544。
其中:
sub_1B8D4
- 负责
TracerPid、PPid、线程 trace-stop 状态检测。
- 命中后走
sub_11FA4 -> sub_234E0 -> exit_group 路径退出。
sub_1C544
- 负责反 Frida 扫描。
- 会周期性扫描:
/proc/self/task、/proc/self/fd、/proc/self/maps。
- 命中后触发
_exit/exit。
与 Frida 线程名直接相关的检测点
sub_1C544 的主循环里至少包含三个检测点:
sub_1BFAC
- 遍历
/proc/self/task/<tid>/status
- 匹配线程名
gum-js-loop、gmain
sub_1C158
- 遍历
/proc/self/fd/*
readlink 后匹配注入痕迹字符串
sub_1C26C
- 遍历
/proc/self/maps
- 匹配
/data/local/tmp、frida-agent、_AGENT_1.0
其中和本文最直接相关的是 sub_1BFAC。可以把它还原成以下可读性更高的伪代码:
void scan_task_status_for_frida_threads(void) {
DIR *dir = opendir("/proc/self/task");
if (!dir)
return;
while ((de = readdir(dir)) != NULL) {
if (!is_digits(de->d_name))
continue;
char path[0x100];
snprintf(path, sizeof(path), "/proc/self/task/%s/status", de->d_name);
char buf[0x400] = {0};
if (!read_text_file(path, buf, sizeof(buf)))
continue;
if (strstr(buf, "gum-js-loop") || strstr(buf, "gmain")) {
_exit(0); // 或 exit(0)
}
}
closedir(dir);
}
其用户态检测流程可概括为:
- 枚举
/proc/self/task
- 拿到每个线程的
tid
- 读取
/proc/self/task/<tid>/status
- 在文本中查找 Frida 特征线程名
这意味着,只要用户态看到的 status 内容被篡改,检测就会失效。
对应的用户态线程名检测流程如下:
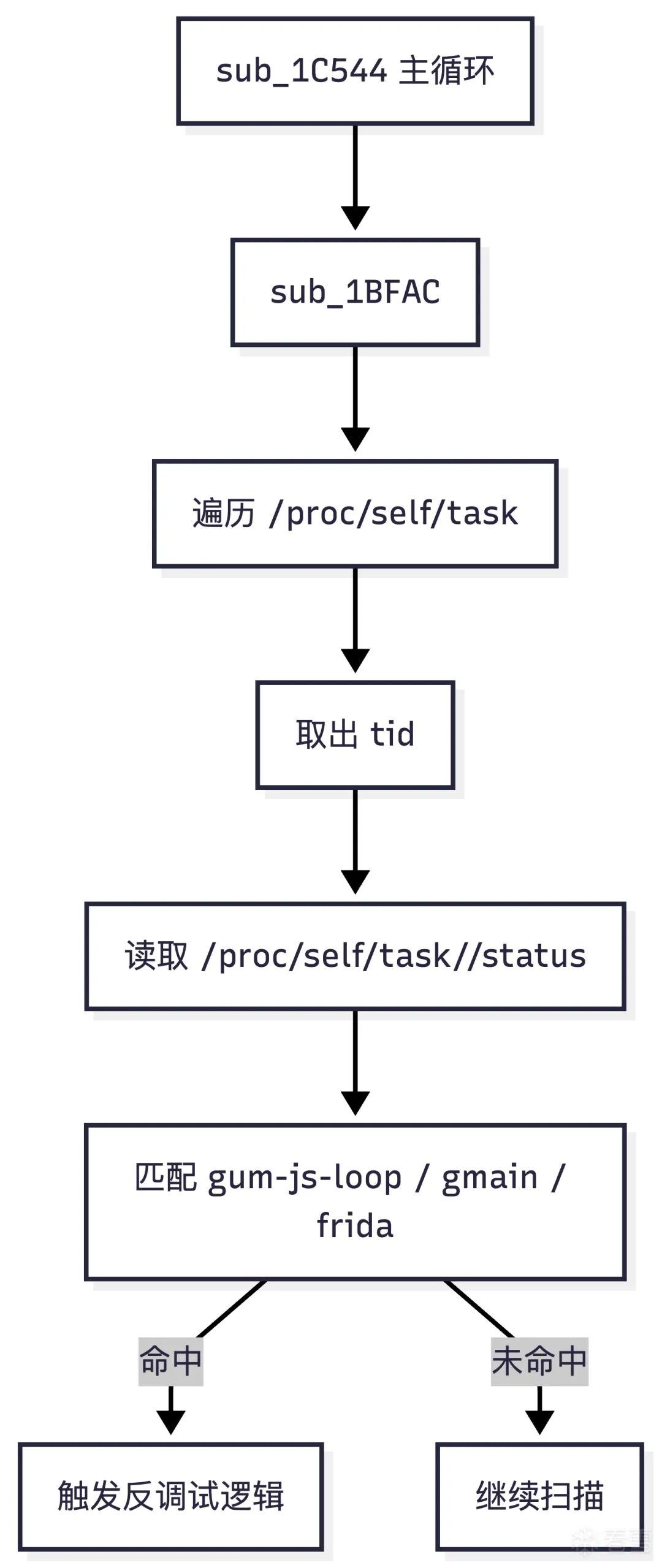
Frida 特征产生原因
很多人在第一次分析这类检测时,会误以为 gum-js-loop、gmain 是“样本自己创建的线程”。其实不然,这些线程名直接来自 Frida 运行时自身。
gum-js-loop
Frida 的脚本执行、消息循环、调度逻辑依赖 Gum 框架。在目标进程里注入 agent 后,Gum 会创建自己的事件循环线程,典型的线程名就是 gum-js-loop。这个线程基本可以视作“Frida JavaScript runtime 正在进程内运行”的直接信号。
gmain
Frida 底层依赖 GLib/GIO 事件循环。一旦使用消息通信、异步 IO 或内部调度,GLib 相关线程也会出现,典型名称就是 gmain。
为什么样本喜欢扫描线程名?
原因很简单:
- 成本低:不需要复杂的反汇编或解析
linker 私有结构。
- 命中率高:在 Frida 默认行为下,这几个线程名非常稳定。
- 输出简单:
/proc/<pid>/task/<tid>/status 本身就是纯文本,一个 strstr 就能完成判定。
换句话说,线程名检测是最典型、也最容易落地的 Frida 识别手段之一。
利用内核模块绕过检测
既然样本依赖的是 /proc 的输出,那最直接的对抗思路就是:不在用户态和它拼输出,而是直接在内核里修改它能看到的 /proc 内容。
本文使用的模块来自:https://github.com/nuoen/kernel_modules
总体思路
hookmodule 主要做了三类事:
- hook
proc_pid_status
- 在生成
/proc/<pid>/task/<tid>/status 文本前,临时修改 task_struct
- hook
proc_task_name
- 在某些
/proc 名称输出路径上,直接改写线程名显示
- hook
show_map_vma
- 隐藏
/proc/<pid>/maps 里的目标库路径
这三类 hook 对应三条不同的检测面:
| 检测面 |
目标路径 |
模块对应处理 |
| 线程名 |
/proc/<pid>/task/<tid>/status |
proc_pid_status kretprobe |
| 任务名显示 |
/proc/.../task/... 相关 seq 输出 |
proc_task_name ftrace |
| 映射路径 |
/proc/<pid>/maps |
show_map_vma ftrace |
从实现层面看,hookmodule 的核心思路是把“用户态读取 /proc 的结果”前移到内核里处理:

关键参数
模块支持的关键参数有:
static int target_pid = 0;
static int target_uid = -1;
static char *hide_so[MAX_NAMES];
static int hide_so_cnt;
示例加载方式:
insmod hookmodule.ko hide_so="frida,gum,gmain,AGENT" debug=true
这里的 hide_so 并不只是“隐藏 so 名字”,更准确地说是:作为一组统一关键字,同时用于线程名、maps 路径、状态输出中的字符串过滤。
针对每一类检测的绕过实现
绕过 /proc/self/task/<tid>/status 线程名检测
这是本文最核心的部分。用户态样本读取的 status 文本最终来自内核的 proc_pid_status()。因此最稳妥的方式不是去改用户态的 fopen/read/fgets,而是直接在内核里拦截 proc_pid_status。
核心 hook 点
模块里使用了 kretprobe:
static struct kretprobe_wrap my_kretprobes[] = {
KRETPROBEHOOK(
kretprobe_ret_handler_porc_pid_status,
kretprobe_entry_handler_proc_pid_status,
sizeof(struct kretprobe_data),
"proc_pid_status",
true),
};
进入 proc_pid_status 时,保存原始值:
task = (struct task_struct *)regs->regs[3];
get_task_struct(task);
task_lock(task);
data->task = task;
data->original_ptrace = task->ptrace;
strscpy(data->original_comm, task->comm, TASK_COMM_LEN);
data->original_state = READ_ONCE(task->__state);
如果线程名命中隐藏关键字,就临时改写:
for (int i = 0; i < hide_so_cnt; i++) {
if (strstr(data->original_comm, hide_so[i])) {
strscpy(task->comm, REPLAE_COMM, TASK_COMM_LEN);
}
}
task->ptrace = 0;
返回 proc_pid_status 后再恢复原值:
task_lock(task);
task->ptrace = data->original_ptrace;
if (strcmp(task->comm, REPLAE_COMM) == 0) {
memcpy(task->comm, data->original_comm, TASK_COMM_LEN);
}
task_unlock(task);
put_task_struct(task);
为什么这能绕过?
因为用户态样本最终看到的是 /proc/self/task/<tid>/status,而 status 文件中的线程名字段,本质上就是内核按 task_struct->comm 生成的文本。
我们在文本生成前把 task->comm 临时改成替身值(如 replace_comm),样本读到的就不再是 gum-js-loop、gmain 或 frida。等到文本生成完成,再恢复原值。这样既能骗过检测,又不会永久破坏线程本身。
这条关键绕过链的时序如下:
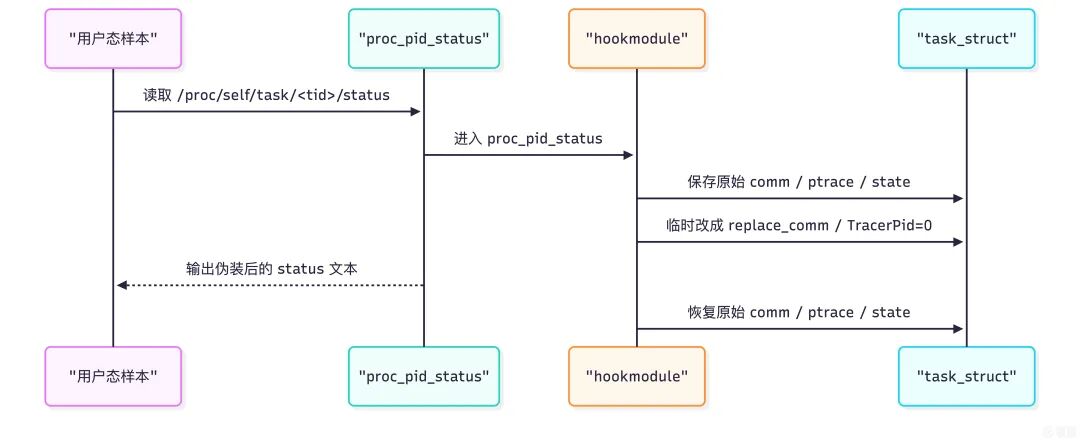
这和用户态 hook 的差别
用户态 hook 的问题在于:
- 容易被对方先发现。
- 需要拦截多个 libc 调用点。
- 很容易和目标样本陷入互相对抗的境地。
而内核里拦截 proc_pid_status 的优点是:
- 只改最终输出源头。
- 对上层
fopen/fgets/read 等调用完全透明。
- 对样本来说,它看到的就是“正常的
/proc 结果”。
绕过 proc_task_name 路径上的线程名显示
除了 status,模块还用 ftrace hook 了 proc_task_name:
static struct ftrace_hook my_hooks[] = {
FTRACEHOOK("proc_task_name", fh_proc_task_name, &real_proc_task_name, true)
};
关键实现:
static asmlinkage void fh_proc_task_name(struct seq_file *m,
struct task_struct *p,
bool escape) {
if (!escape) {
char tcomm[64];
__get_task_comm(tcomm, sizeof(tcomm), p);
for (int i = 0; i < hide_so_cnt; i++) {
if (strstr(tcomm, hide_so[i])) {
const char *hide_str = "hidding";
strscpy(tcomm, hide_str, 64);
seq_printf(m, "%.64s", tcomm);
return;
}
}
}
real_proc_task_name(m, p, escape);
}
作用
这个 hook 并不替代 proc_pid_status,而是起补充作用。因为某些 /proc 输出路径不会直接走 status,但仍会走基于 seq_file 的任务名格式化逻辑。对这些路径,fh_proc_task_name 可以直接把线程名输出改成 hidding。
为什么需要这一层?
因为有些样本并不只读 status,还会枚举 task 目录、走其他 proc 文本生成路径、直接读取任务名相关输出。这时只拦截 proc_pid_status 不一定够,proc_task_name 相当于多了一层兜底。
它与 proc_pid_status 的分工关系如下:
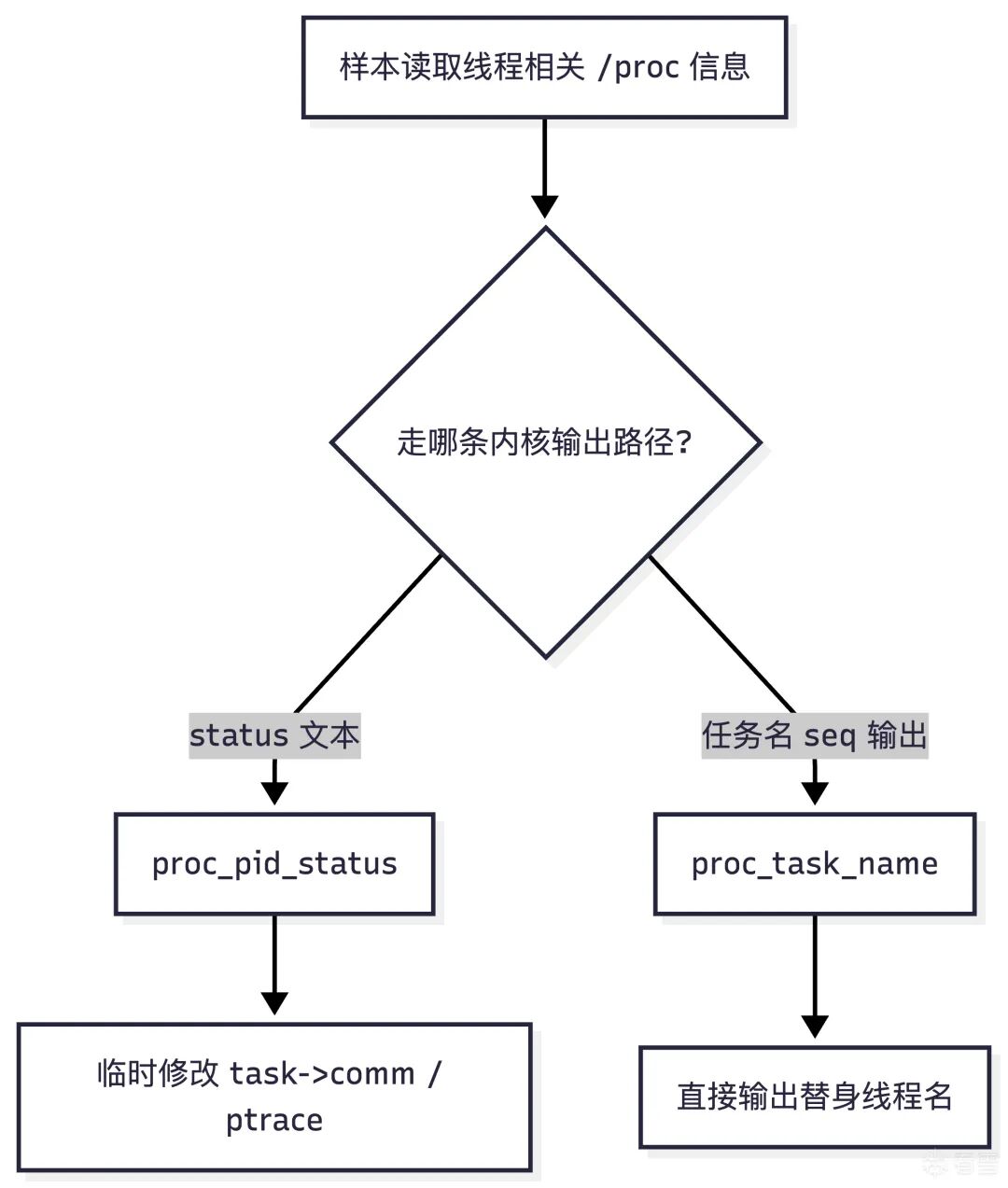
绕过 /proc/self/maps 中的 Frida 模块痕迹
sub_1C26C 这类检测会扫描 /proc/self/maps。模块里对应的处理是 hook show_map_vma:
static struct ftrace_hook my_hooks[] = {
FTRACEHOOK("show_map_vma", fh_show_map_vma, &real_show_map_vma, true)
};
关键逻辑:
pathname = d_path(&vma->vm_file->f_path, path_buf, sizeof(path_buf));
for (int i = 0; i < hide_so_cnt; i++) {
if (strstr(pathname, hide_so[i])) {
return; // 不输出这个 maps 条目
}
}
real_show_map_vma(m, vma);
为什么能绕过?
因为 /proc/<pid>/maps 的每一行最终都是内核把 vma 格式化成文本。我们在输出层直接跳过匹配项,用户态样本看到的 maps 就不会包含 frida、gum、AGENT 等关键字。
但这不是万能的
这点需要说清楚。show_map_vma 只能隐藏 /proc/maps 的文本视图。它不能隐藏已经实际加载进进程的 linker 私有 solist 或 soinfo 结构。
所以它能绕过 sub_1C26C 这类 /proc/maps 检测,但无法直接解决 sub_20BDC 那种基于 linker 私有结构的遍历检测。
对 TracerPid 与 TASK_TRACED 的处理
模块还在 proc_pid_status kretprobe 里顺手做了两件事:
if (data->original_state == TASK_TRACED) {
WRITE_ONCE(task->__state, TASK_RUNNING);
}
task->ptrace = 0;
作用
这可以绕过另一类典型的用户态反调试:读取 TracerPid 或检查线程是否处于 T/t(trace stop)状态。这正对应 so 另一条检测链里的 sub_1AE48 和 sub_1B730。
实验结果
加载内核模块后,可以从内核日志中观察到拦截与修改操作生效:
[ 7621.344945] hookmodule: Modified TracerPid for process 2055 to 0
[ 7621.345031] hookmodule: [SEQ:358] KRETPROBE HANDLER :proc_pid_status return (entry was SEQ:357)
[ 7621.345050] hookmodule: [SEQ:358] Restored TracerPid for process 2055 to 0
[ 7624.342313] hookmodule: Hiding target library frida form PID 13646 maps
...
sub_20BDC linker 私有结构遍历崩溃链的原理分析
sub_20BDC 的作用
sub_20BDC 本质上不是 /proc 检测函数,而是:
- 从
linker 私有结构中拿到 solist 头指针
- 遍历已加载模块链表
- 按名字查找目标模块
可以把它理解成一个私有版的查找函数:void *find_loaded_module_by_name_via_solist(const char *name);
sub_20BDC 的伪代码
根据分析结果,其逻辑可整理为(关键部分):
void *find_loaded_module_by_name_via_solist(const char *name) {
if (!guard_initialized)
solist_head = get_linker_solist_head(); // sub_2082C()
cur = solist_head;
// ... 根据不同 Android SDK 版本调整偏移量进行遍历 ...
do {
// 获取 soname 并比较
if (soname && strstr(soname, name))
found = cur;
cur = *(void **)(cur + next_offset); // 关键:继续遍历下一个节点
} while (cur);
return found;
}
检测逻辑使用 Frida 后,sub_20BDC 易崩溃的原因
sub_20BDC 的危险点有两个:
- 它依赖
linker 私有结构偏移,这些偏移可能因版本或环境变化而不准确。
- 它命中目标模块后不会立即返回,而是继续遍历整个
solist 链表。
这意味着,即使它已经找到了目标模块,只要后续链表节点里存在一个它用错偏移、无法正确处理的节点,它仍然会在继续遍历时访问非法内存,导致崩溃(SIGSEGV)。
这也解释了现象:不挂 Frida 时通常不崩,挂 Frida 后更容易崩。根因并非“Frida 改坏了 linker 偏移”,而是 Frida 注入后,solist 中节点更多、更复杂,sub_20BDC 在遍历时更容易遇到不兼容的节点结构。
这种差异可用下图概括:
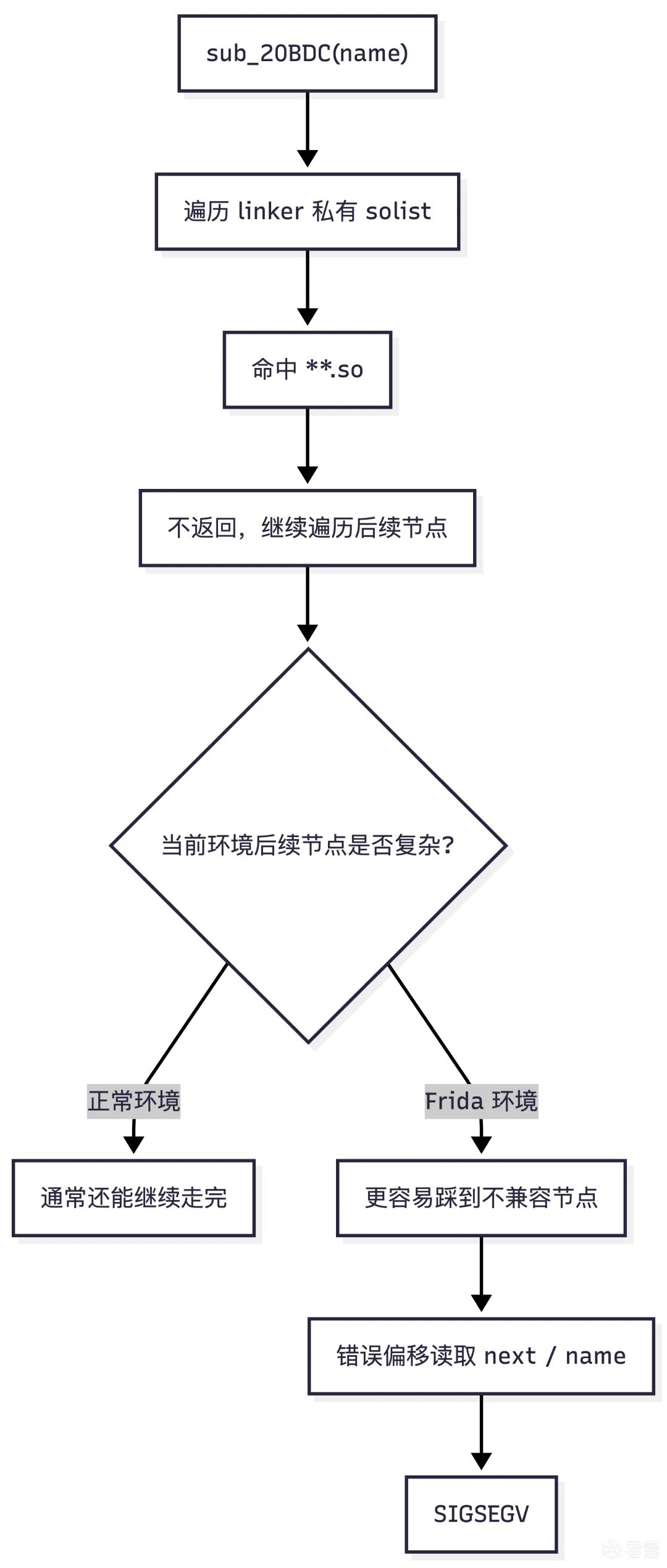
调用流程与绕过策略
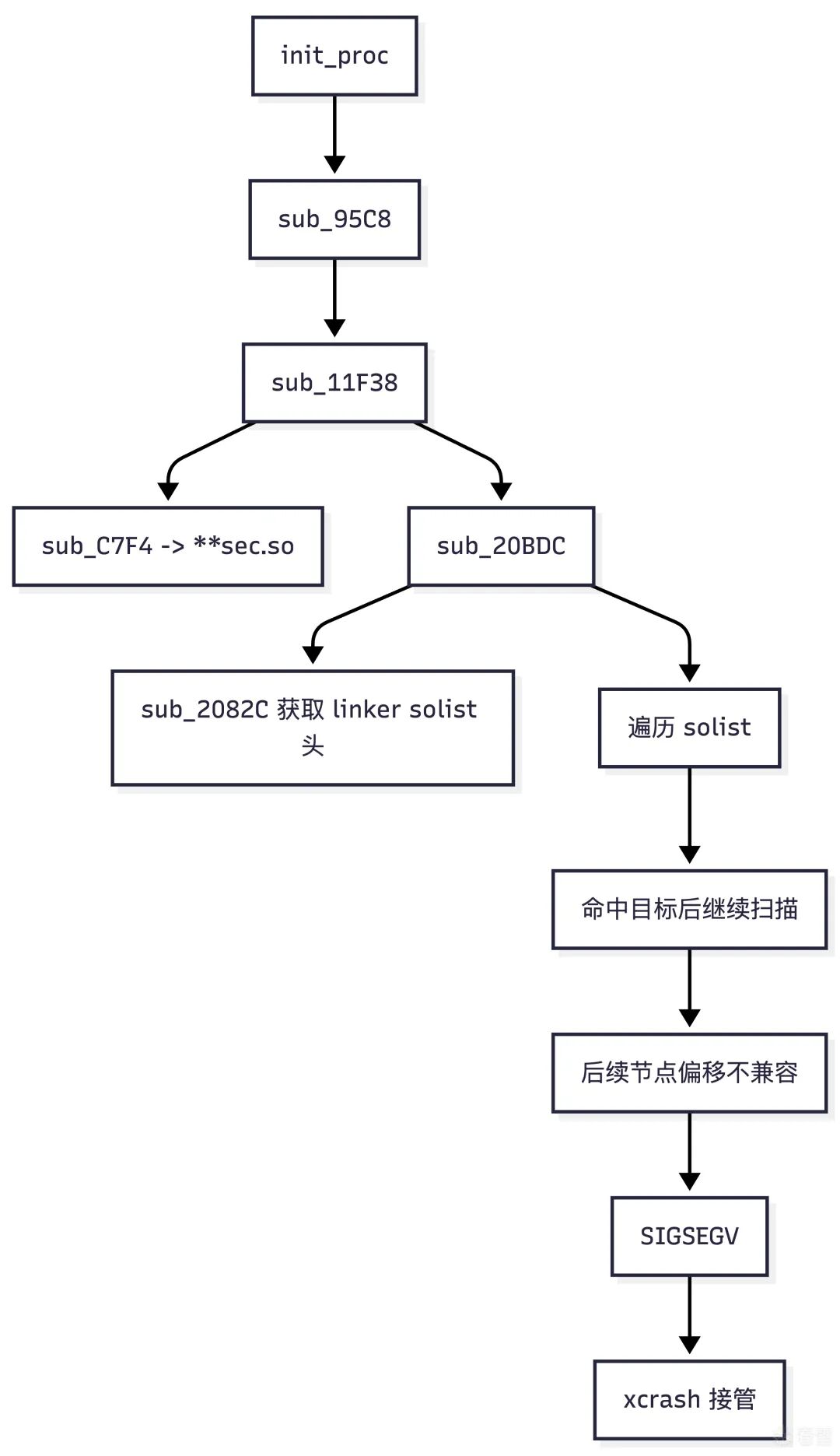
从分析看,sub_20BDC 至少有两条调用路径。一条较短的、更直接的崩溃调用链是:
sub_95C8 -> sub_11F38 -> sub_C7F4 (查找 "**sec.so") -> sub_20BDC -> SIGSEGV
可以将此崩溃链可视化:
为什么这条链路我采用 Frida 脚本绕过而不是内核模块?
原因很简单:
sub_1BFAC / sub_1C158 / sub_1C26C 依赖的是 /proc 文件系统的输出。sub_20BDC 依赖的是 linker 进程内存里的私有 solist 链表。
内核模块能骗过 /proc,但无法直接修改另一个进程用户态内存中的 linker 数据结构。因此,对抗 sub_20BDC 这类检测,仍需在用户态进行修补,例如使用 Frida 拦截该函数并直接返回 NULL:
function patch_sub_20BDC(secmodule) {
const addr = secmodule.base.add(0x20BDC);
Interceptor.replace(addr, new NativeCallback(function (namePtr) {
let name = '<null>';
try {
if (!namePtr.isNull()) {
name = namePtr.readCString();
}
} catch (_) {}
console.log('[+] patch sub_20BDC @ ' + addr + ' =====> return NULL for name=' + name);
return ptr(0);
}, 'pointer', ['pointer']));
console.log('[+] semantic patch installed sub_20BDC @ ' + addr);
}
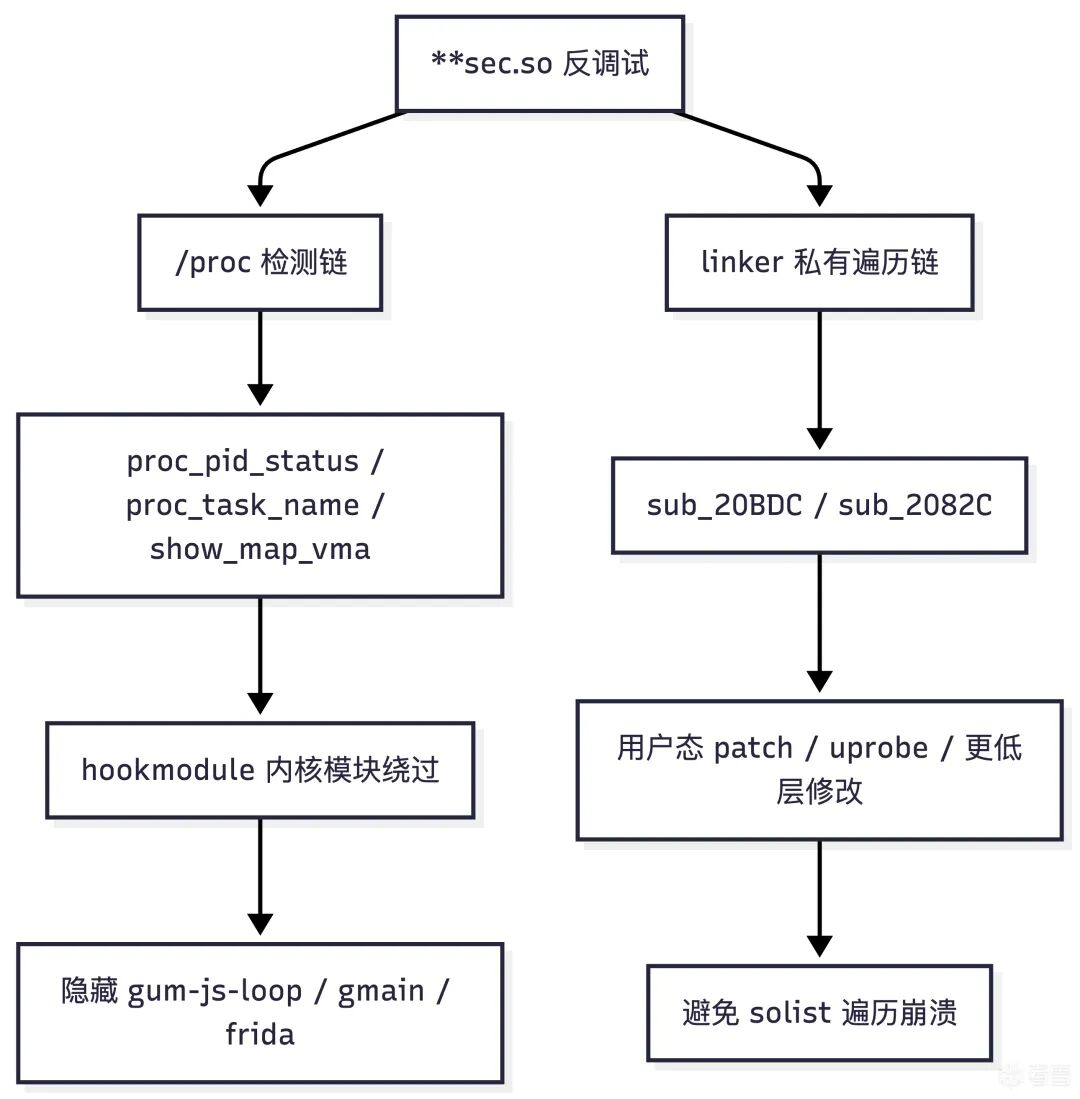
总结
**sec.so 的反调试不是单点检测,而是一组层次化的保护:
/proc/status、TracerPid、线程 trace-stop 状态检测。/proc/task/<tid>/status 里的线程名检测。/proc/self/maps 与 /proc/self/fd 的路径检测。linker 私有 solist 遍历检测。
本文给出的内核模块方案,核心价值在于:
- 不与用户态 libc/stdio 函数对抗,对抗性更低。
- 直接改写
/proc 文件系统的最终输出源头,更为彻底。
- 对
gum-js-loop、gmain、frida 这类线程名检测非常有效。
这使得:
sub_1BFAC 这类基于 /proc/task/.../status 的反 Frida 检测可被稳定绕过。TracerPid/TASK_TRACED 相关检测也能被顺手处理。/proc/maps 里的显式 Frida 痕迹也能被隐藏。
但同样需要明确其边界:内核模块能骗过 /proc,但不能直接骗过 linker 的私有内存结构。
因此,在实战对抗此类综合型反调试时,更合理的策略是分层处理:
- 用内核模块压制
/proc 检测链,从源头切断基于文件系统的特征泄露。
- 用用户态 patch (如 Frida)、uprobe 或更低层的修改,来处理
sub_20BDC 这类 linker 私有遍历链。
这才是对抗 **sec.so 这类综合型反调试模块的更系统、更稳妥的方案。
最后用一张总图来收敛本文的核心结论:
欢迎在 云栈社区 的技术板块,与更多开发者深入探讨系统安全与逆向工程相关话题。
 发表于 2026-3-20 10:10:12
|
查看: 176|
回复: 0
发表于 2026-3-20 10:10:12
|
查看: 176|
回复: 0
