当数据库面临不断增长的读写压力时,读写分离作为一种有效的优化手段便显得尤为重要。通常有两种实现路径:在应用层编码实现路由,或者引入一个专门的数据库中间件。本文将重点探讨后者,解析其工作原理、常用工具及选型建议。
读写分离的基本概念
首先,我们需要明确读写分离的两个核心角色:
- 主库(Primary):负责处理所有写操作,例如
INSERT、UPDATE、DELETE。
- 从库(Replica):负责处理读操作(主要是
SELECT),其数据通过复制机制从主库同步而来。
那么,为什么要采用这种架构呢?
- 绝大多数应用场景都遵循“读多写少”的规律,通常读操作占比可达80%甚至更高。
- 从库可以轻松地进行水平扩展,通过增加实例数量来大幅提升系统的读吞吐能力。
- 将读写分离后,主库可以更专注于写操作,有效减少因并发读取导致的锁竞争,提升写性能。
实现方式对比
方式一:应用层路由
这种方式要求开发者在业务代码中显式地判断SQL类型,并选择相应的数据源。
if (isWriteOperation(sql)) {
connection = primaryDataSource.getConnection();
} else {
connection = replicaDataSource.getConnection();
}
缺点显而易见:
- 代码侵入性强:读写分离的逻辑与业务代码耦合在一起。
- 重复劳动:每个需要访问数据库的应用都必须自行实现这套逻辑。
- 维护困难:一旦数据库的拓扑结构发生变化(例如增加从库),就需要修改所有相关应用的代码并重新部署。
方式二:数据库中间件(推荐)
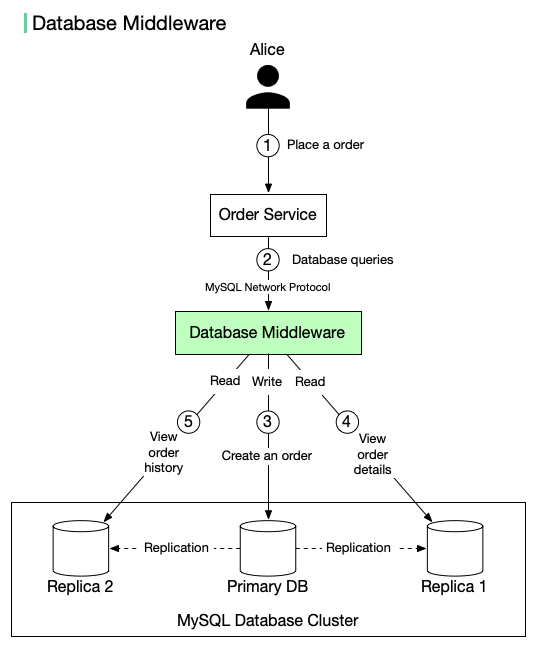
这是更为优雅和通用的解决方案。中间件作为一个独立的代理层,部署在应用程序与真实数据库集群之间,对应用程序透明地处理所有路由逻辑。
其工作流程清晰明了:
- 应用程序像连接单个普通MySQL一样,连接中间件。
- 中间件接收并解析应用程序发送的SQL语句。
- 识别为写操作(
INSERT/UPDATE/DELETE等),则将其路由至主库。
- 识别为读操作(
SELECT),则根据策略路由至某个从库。
一个典型的电商场景示例:
- 用户下单(写操作):中间件将“创建订单”的请求路由到主库。
- 查看订单详情(读操作):中间件可能将这次查询路由到从库A。
- 查看历史订单(读操作):中间件可能将这次查询路由到负载更轻的从库B。
常用数据库中间件
市面上有多种成熟的数据库中间件可供选择:
ProxySQL(MySQL生态明星)
- 高性能,内置连接池管理。
- 提供非常灵活和强大的SQL路由规则配置。
- 支持查询结果缓存,进一步提升读性能。
MyCat(国内流行)
- 功能全面,不仅支持读写分离,还支持分库分表。
- 兼容多种数据库后端。
- 社区活跃,中文资料丰富。
ShardingSphere(Apache顶级项目)
- 提供两种模式:对应用透明的JDBC驱动侧部署,或独立的Proxy服务。
- 功能集强大,包括数据分片、读写分离、数据加密等。
- 拥有非常活跃的开源社区和持续的版本迭代。
AWS RDS Proxy(云托管服务)
- 完全托管的服务,无需自行维护中间件服务器。
- 自动处理数据库实例的故障转移,提升应用可用性。
- 与AWS Lambda等无服务器服务集成良好。
中间件的优点
- 极大简化应用代码:应用开发者无需关心后端是主库还是从库,就像使用单点数据库一样简单。数据库集群的扩缩容、主从切换对应用几乎无感。
- 提供更好的兼容性:中间件通常使用标准的MySQL网络协议,这意味着任何兼容MySQL的客户端或ORM框架(如JDBC、PHP的mysqli)都能直接连接,降低了数据库迁移和切换的成本。
- 支持灵活的路由策略:策略可以非常精细,例如:根据SQL语句类型路由、根据表名路由、在事务内部强制走主库以保证读一致性,甚至可以结合业务实现按用户ID哈希路由到特定从库。
中间件的缺点
引入任何新组件都会带来权衡,数据库中间件也不例外:
- 增加了系统复杂度:中间件本身成为了系统架构中的关键节点,必须保证其高可用性,通常需要以集群方式部署,这无疑增加了运维的复杂度和成本。
- 引入额外的网络延迟:请求路径从“应用 -> 数据库”变成了“应用 -> 中间件 -> 数据库”,多了一次网络跳转。因此,中间件本身的性能必须极高,这也是许多中间件采用C/C++开发的原因。
- 可能存在SQL兼容性问题:中间件需要对SQL进行解析和转发,对于极其复杂或非标准的SQL语句(如某些数据库特有的函数或语法),可能无法完美支持,导致功能受限。
选型建议
在以下场景中,使用数据库中间件通常是更优选择:
- 多个微服务或应用需要共享同一套数据库集群。
- 需要配置复杂、灵活的路由规则(如分库分表结合读写分离)。
- 面对遗留系统,希望实现读写分离但不想或不能大规模修改其源代码。
而在这些场景下,应用层路由或许更合适:
- 全新开发的应用,且团队对架构有完全掌控力。
- 读写分离规则非常简单固定。
- 希望保持技术栈简洁,极力避免引入新的外部组件。
部署架构
一个典型的高可用中间件部署架构如下所示:
[应用服务器] × N
↓
[中间件集群] × 2(主备或负载均衡)
↓
[MySQL主库] ←──同步──→ [MySQL从库] × 2
总结
数据库中间件通过提供一个抽象层,为应用程序带来了透明的读写分离能力,极大地简化了开发并提升了架构的灵活性。当然,其代价是增加了系统的复杂性和微小的网络延迟。
对于正在成长或已经复杂化的中大型系统而言,中间件所带来的开发效率提升、运维便捷性以及架构扩展潜力,其价值往往远超它引入的复杂度。在实际选型时,需要根据团队技术栈、运维能力和业务的具体需求进行综合判断。关于更多数据库与架构设计的深度讨论,欢迎在云栈社区交流分享。 |  发表于 2026-3-20 23:34:47
|
查看: 114|
回复: 0
发表于 2026-3-20 23:34:47
|
查看: 114|
回复: 0
