昨天还在看英伟达凭借显卡业务一骑绝尘,今天,身着标志性黑色皮衣的黄仁勋就在 GTC 2026 大会上,向处理器市场投下了一颗重磅炸弹。
这次大会照例干货满满,展示了一系列令人眼花缭乱的新硬件。

然而,最引人注目的或许不是那些算力暴涨的GPU,而是一颗名为 NVIDIA Vera 的下一代数据中心CPU。更关键的是,黄仁勋宣布,这款CPU将打破以往的捆绑模式,首次公开对外独立销售。

这并非英伟达首次涉足CPU领域。早在2022年,其首款数据中心CPU Grace 就已问世,但初期策略更像是“买GPU送CPU”,主要服务于自家的加速计算方案,充当协同角色。

而此次Vera CPU的独立上市,无疑标志着英伟达正式将枪口对准了传统数据中心CPU市场的两位霸主——Intel与AMD。一场新的竞赛已经开始。
我们先来看看这款新处理器的硬核参数。
Vera 的核心架构代号为 “Olympus” ,基于 Armv9.2-A 指令集打造。它集成了多达 88个 英伟达完全自研的定制核心,并通过“空间多线程技术”,实现了 88核176线程 的夸张规格。相比之下,上代Grace为72核144线程,规模提升显著。
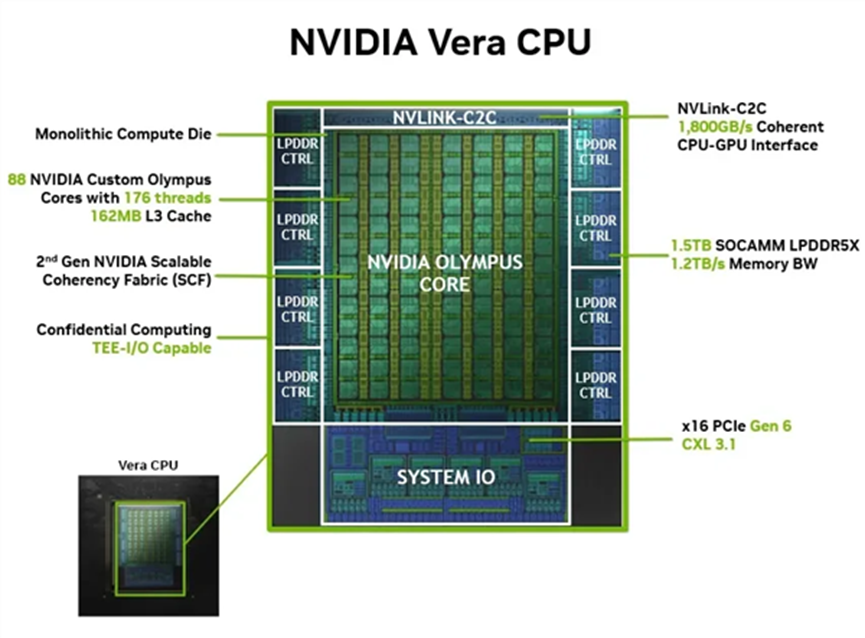
在当前的AI计算中,瓶颈往往不是算力本身,而是数据在处理器与内存之间“堵车”。Vera 直接采用了第二代低功耗内存子系统,将内存带宽推至惊人的 1.2 TB/s。

再叠加上英伟达自家的 NVLink-C2C 互连技术,Vera 与 GPU 之间的高速一致性带宽进一步提升至 1.8 TB/s,这已经是PCIe 6.0标准带宽的7倍之多。
在这些硬件优势的加持下,黄仁勋在台上自信地宣称,相比传统的通用架构CPU,Vera 在处理大规模数据和AI负载时,其IPC性能比上代Grace高出1.5倍。

整体性能比标准x86架构CPU快50%,在实现效率翻倍的同时,功耗还能大幅降低。
如果说单颗Vera CPU的规格已令人侧目,那么基于MGX架构的整机柜方案则堪称“性能怪兽”。单个机柜可集成256颗Vera CPU,总计22528个核心,45056线程,最高支持400TB LPDDR5X内存,总带宽高达300TB/s,并采用纯液冷散热。

这一设计思路非常明确:将硬件堆料到极致,以榨干每一分算力。

可能有人会问:英伟达在GPU领域已然是独孤求败,为何还要踏入竞争激烈的CPU市场?
根本原因在于,AI的玩法正在发生深刻变革。过去的AI大模型训练,核心是“大力出奇迹”,依赖海量GPU并行计算,CPU主要负责任务调度和数据协调,角色相对边缘。

但在GTC 2026上,黄仁勋反复强调了一个新趋势:智能体AI(Agentic AI)。未来的AI不仅需要强大的“计算”能力,更需要具备“思考、规划、自我纠错、调用工具”等复杂的逻辑控制与多任务并发能力。而这恰恰是CPU的强项。换言之,如果CPU性能成为短板,GPU再强也难以发挥全部威力。

黄仁勋的思路很清晰:既然合作伙伴的CPU可能成为自家GPU系统的瓶颈,那就亲自下场,打造一套最优解。Vera的出现,旨在补齐英伟达在AI数据中心版图中的最后一块拼图。其目标不仅是赚钱,更是要牢牢掌握从芯片到系统的整个基础设施话语权。
面对这波攻势,最感压力的无疑是Intel和AMD这对x86阵营的“宿敌”。当两者仍在传统赛道激烈缠斗时,一个来自GPU领域的巨无霸携带着针对性优化的产品,以近乎降维打击的姿态闯入了战场。
Vera最令人震撼的一点在于,它标志着Arm架构在高端数据中心市场已彻底站稳脚跟。过去,Arm常被视为移动设备或轻量云服务的专属,如今Vera凭借其极致的能效比和恐怖的内存带宽证明:在AI大模型时代,Arm架构完全有能力与传统的x86架构正面交锋,尤其是在为AI负载量身定制的计算场景中。

更重要的是,这并非纸上谈兵。根据披露的信息,NVIDIA Vera CPU目前已进入全面量产阶段,计划于今年下半年开始交付。包括Meta、甲骨文、字节跳动、阿里巴巴等在内的头部科技公司,均已出现在其首批合作客户名单中。

当这些追求极致性能与效率的大型客户发现,采用英伟达的CPU不仅能更好地释放其GPU的潜力,还能在功耗和空间上带来显著优势时,市场的天平很可能会发生倾斜。留给传统x86 CPU的市场空间,或许将面临前所未有的挤压。
对这类重塑市场格局的技术动态,像云栈社区这样的专业开发者社区总是保持高度关注。从GPU到CPU,再到整个AI计算栈的垂直整合,英伟达的每一步都深刻影响着全球算力产业的走向。未来数据中心处理器的竞争格局,或许真的要被改写了。
 发表于 2026-3-21 01:12:00
|
查看: 139|
回复: 0
发表于 2026-3-21 01:12:00
|
查看: 139|
回复: 0
