这几天,科技圈几乎被MiniMax M2.7的消息刷屏了。
各个技术群里到处是截图和跑分数据,不少人非常激动,因为它的“幻觉率”指标从89%骤降至34%。这个数据意味着,模型在面对不确定答案时“胡说八道”的比例大幅降低。
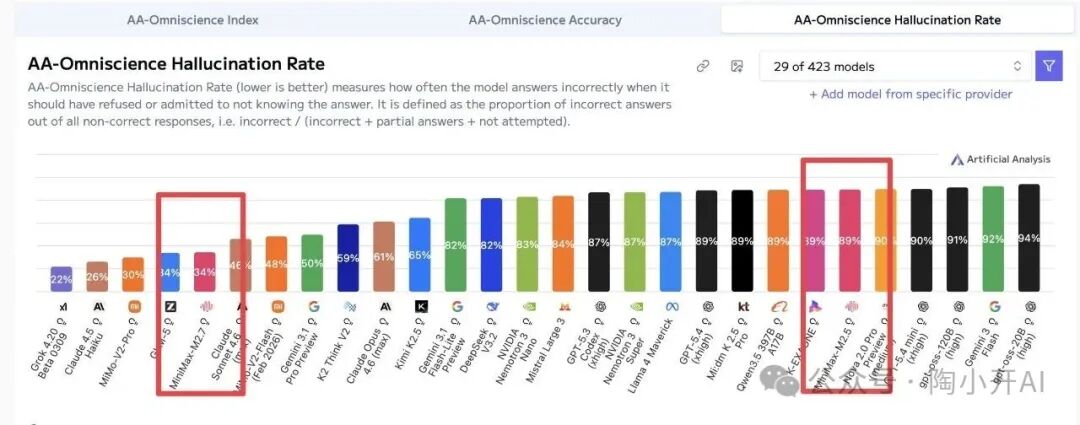
从评测分数看,M2.7一举追平了GLM-5,甚至在某些方面逼近了GPT-5.4。一时间,“国产大模型赶超国际巨头”的叙事再次成为焦点。
然而,当我们沉浸于技术指标的狂欢时,或许应该把目光从排行榜上挪开,去看看大模型创业公司的财务报表,或者听听那些深夜收到的云服务商催款电话。你会意识到,这背后可能并非纯粹的技术胜利,而是一场被逼到墙角的财务自救,甚至是对现有行业生态的一次无声冲击。
大家都在讨论模型变得更“聪明”了,但很少提及一个更现实的商业问题:如果再不这么做,公司的现金流可能就要断了。
而当它们真的这么做了,过去两年被行业津津乐道的“AI中间商”模式和“算力霸权”叙事,似乎在一夜之间就变得摇摇欲坠。我们可以用更底层的逻辑来算两笔账。
第一笔账:用算力换“诚实”
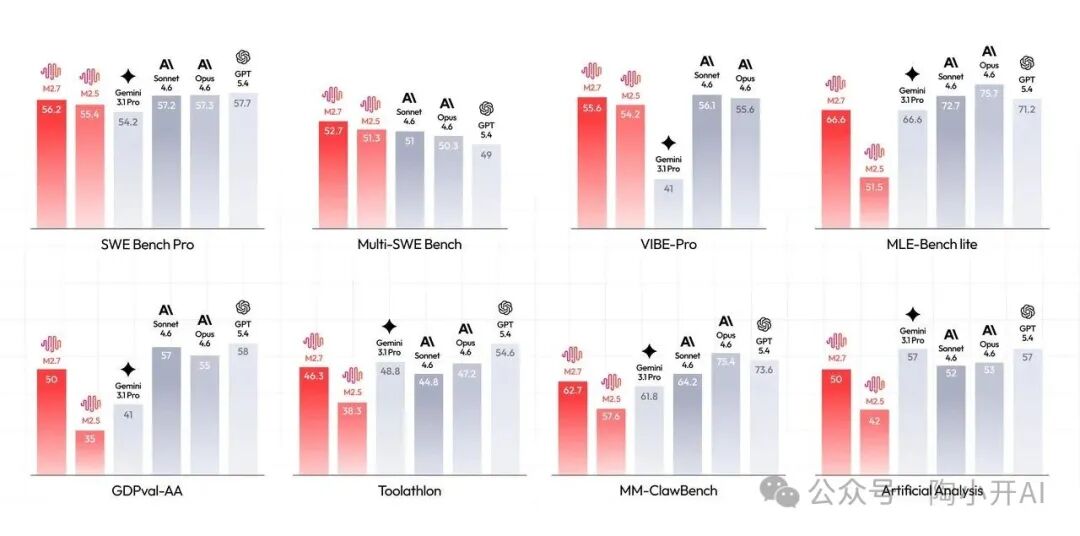
过去的模型,有时像一个过于自信的销售,对任何问题都试图给出答案,哪怕并不确定。而M2.7的做法是,宁愿在后台多花一倍的计算资源进行逻辑验证,也要大大降低“幻觉”。这导致其输出Tokens数从5600万激增至8700万。
关键在于,多干了这么多活,它的API调用单价却一分没涨,稳定在每百万输出1.2美元。完成整个AII测试的总成本仅需176美元,不到同等智力水平竞品(如GLM-5的547美元)的三分之一。这是一种“成本不变,效果倍增”的暴力优化。
第二笔账:极端的“成本塌陷”
更令人惊讶的是在MLE Bench Lite这类评测中的表现。有数据显示,M2.7仅凭一张老旧的A30显卡,在24小时内通过自我迭代,就能打平Gemini-3.1 Pro的水准。
一张A30跑一天,电费可能都不到100元人民币。回想一下,过去要达到类似的模型调优效果,可能需要数百人的算法团队工作数月,并消耗数亿规模的算力资源。如今,这个过程被压缩成了几十块的电费和几分钱的自动化推理成本。
这种“断崖式”的成本重构,正在引发一场双向的行业震荡。
第一重冲击:动摇“算力霸权”
以往,创业公司容易陷入一个循环:模型越“卷”越强,所需的算力就越贵,最终导致“越聪明越赔钱”。M2.7通过软件层面的极致优化,在几乎不增加硬件成本的前提下榨干了旧有硬件的性能潜力。这实际上赋予了模型厂商对云计算服务商更强的议价能力。
第二重冲击:挤压“应用生态”
真正的竞争,或许并非“大模型对战大模型”,而是“大模型对战应用生态”。当M2.7这样的模型能够高效地吸收特定领域的方法论,并将其内化为自身能力时,那些试图在细分场景提供工具或服务、收取“过路费”的SaaS公司就面临挑战。它们在一定程度上,可能变成了为大模型免费提供“数据标注”和“方法验证”的角色。大模型自身正演变成一个功能愈发完备、无需过多外部插件的“全能体”。
剥开技术指标的表象,背后是两条冷酷的商业规律:
第一,极度的丰裕可能催生惰性,而极端的匮乏反而会逼迫创新。为什么是中国公司在一张旧显卡上将优化做到了如此深度?部分原因在于,我们没有硅谷同行动辄调用十万张H100的奢侈条件。算力受限,资本审慎,这反而倒逼团队用软件的极致精巧,去对抗硬件的“暴力”垄断。这是一种被逼到墙角后的绝地反击。
第二,顶级的智能,始于对“无知”的坦诚。而极致的效率,最终可能会消解掉曾经繁荣的中间生态。当一个高速发展的技术学会说“我不知道”,并且无情地抹平了人类为了协作和安全感而建立的诸多中间环节时,它才真正跨过了从“有趣玩具”到“可靠工具”的关键门槛。
行业里总有人拿着放大镜,对比国产模型与国际巨头的分数差距,甚至质疑创业公司的前景。但我认为,应该给予MiniMax团队更多的尊重。在国际巨头用生态建起高墙、云厂商用算力卡住命脉的环境下,他们硬是探索出了一条低功耗、自闭环的发展路径。能够在极限条件下将账本算到小数点后四位,这种对效率和生存的极致追求,或许比榜单上的高分更值得关注。
在官方介绍中,MiniMax还提到了一个名为OpenRoom的Demo:将一个能自我调整参数的智能体放入虚拟房间,让它与环境自主互动。看到这个演示,一个值得深思的问题浮现了:我们总以为是自己为这些智能机器建造了“游戏室”,但在它们飞速进化的视角里,当它们学会了自我编程以节省成本、提炼技能以求生存时,有没有可能,我们人类才是那个被关在旧时代物理规则中,不断为其进化提供养料和场景的“NPC”呢?
技术的跃进从不温情,它总是伴随着旧秩序的瓦解与新格局的形成。关于MiniMax M2.7的讨论,远不止于一份成绩单,更是对AI行业未来走向的一次重要预演。对这场变革的更多观察与思考,也欢迎来云栈社区与大家一起交流探讨。
 发表于 2026-3-21 03:31:21
|
查看: 175|
回复: 0
发表于 2026-3-21 03:31:21
|
查看: 175|
回复: 0
