本文将详细介绍如何使用 OpenCV 及其他 Python 库来检测道路上的车道线。整个过程遵循一个经典的计算机视觉处理流程:从图像预处理开始,逐步到边缘检测、感兴趣区域提取,最终通过霍夫变换识别直线,并优化结果。我们首先在单张图片上实现整个流程,然后将其扩展应用到视频流中,为自动驾驶等场景提供基础的视觉感知能力。
第一步:加载并查看原始图像
我们首先使用 OpenCV 加载一张道路图像。这是所有后续处理的起点。
# Loading the image using OpenCV
import cv2
image= cv2.imread("test_image.jpg")
cv2.imshow("Input Image",image)
cv2.waitKey(0)
cv2.destroyAllWindows()

第二步:图像预处理 — 转为灰度图
彩色图像包含大量的颜色信息,但对于车道线检测这种基于形状和边缘的任务,我们通常先将其转换为灰度图,以减少计算量并突出结构信息。
# Converting Image to Grayscale
import numpy as np
lanelines_image=np.copy(image)
gray_conversion = cv2.cvtColor(lanelines_image,cv2.COLOR_BGR2GRAY)
cv2.imshow("Input Image",gray_conversion)
cv2.waitKey(0)
cv2.destroyAllWindows()

第三步:图像平滑 — 应用高斯滤波
原始图像中可能存在噪声,这些噪声会在后续的边缘检测中产生伪边缘。使用高斯滤波器对图像进行平滑处理,可以有效抑制噪声。
# Smoothing the image
blur_conversion=cv2.GaussianBlur(gray_conversion,(5,5),0)
cv2.imshow("Input Image",blur_conversion)
cv2.waitKey(0)
cv2.destroyAllWindows()

第四步:边缘检测 — Canny算子
Canny 边缘检测算法是计算机视觉中的经典方法,它能有效地找出图像中灰度变化剧烈的区域,即物体的边缘。我们将其应用于平滑后的图像。
# Canny Edge Detection
canny_conversion = cv2.Canny(blur_conversion,50,155)
cv2.imshow("Input Image",canny_conversion)
cv2.waitKey(0)
cv2.destroyAllWindows()

第五步:定义感兴趣区域 (ROI)
在一张道路图像中,我们通常只关心车辆前方的路面区域,即车道线可能出现的三角区域。通过定义一个多边形掩码,我们可以屏蔽掉天空、树木等无关区域的边缘,只保留 ROI。
首先,创建一个掩码图像。
# Masking the Region of Interest
import matplotlib.pyplot as plt
def reg_of_interest(image):
image_height=image.shape[0]
polygons=np.array([[(200,image_height),(1100,image_height),(550,250)]])
image_mask=np.zeros_like(image)
cv2.fillPoly(image_mask,polygons,255)
return image_mask
cv2.imshow("Result",reg_of_interest(canny_conversion))
cv2.waitKey(0)
cv2.destroyAllWindows()

然后,使用按位与操作将边缘检测结果与掩码结合,得到只包含 ROI 内边缘的图像。
# Applying Bitwise_and
def reg_of_interest(image):
image_height=image.shape[0]
polygons=np.array([[(200,image_height),(1100,image_height),(550,250)]])
image_mask=np.zeros_like(image)
cv2.fillPoly(image_mask,polygons,255)
masking_image=cv2.bitwise_and(image,image_mask)
return masking_image
cropped_image=reg_of_interest(canny_conversion)
cv2.imshow("Result",cropped_image)
cv2.waitKey(0)
cv2.destroyAllWindows()

第六步:直线检测 — 霍夫变换
现在,图像中只剩下 ROI 内的边缘点。我们使用概率霍夫变换 (cv2.HoughLinesP) 来检测这些点构成的直线段,这些线段很可能就是车道线。
# Applying the Hough Transform
def show_lines(image,lines):
lines_image=np.zeros_like(image)
if lines is not None:
for line in lines:
X1,Y1,X2,Y2=line.reshape(4)
cv2.line(lines_image,(X1,Y1),(X2,Y2),(255,0,0),10)
return lines_image
lanelines=np.copy(image)
lane_lines=cv2.HoughLinesP(cropped_image,2,np.pi/180,100,np.array([]),minLineLength=40,maxLineGap=5)
line_image=show_lines(lanelines_image,lane_lines)
cv2.imshow("Result",line_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
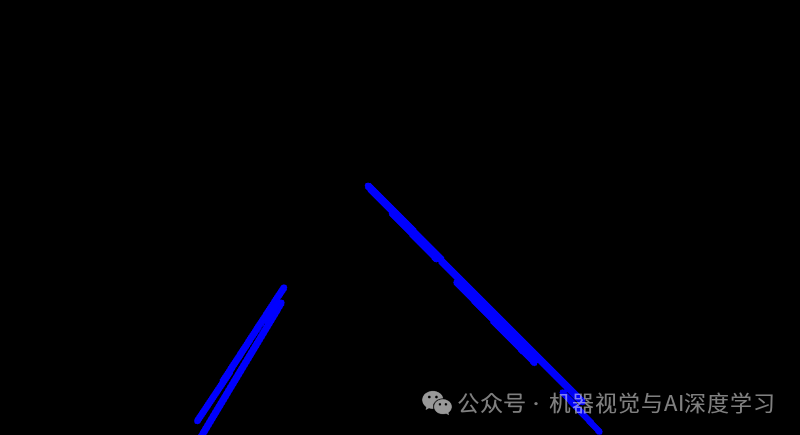
第七步:可视化与叠加
将检测到的线段叠加回原始图像,直观地查看检测效果。
# Show the results in original image
combine_image=cv2.addWeighted(lanelines,0.8,line_image,1,1)
cv2.imshow("Result",combine_image)
cv2.waitKey(0)
cv2.destroyAllWindows()

第八步:优化车道线输出
上一步的结果是许多短线段。为了得到两条清晰、连贯的左右车道线,我们需要对这些线段进行聚合和平均。
首先,定义一个函数,根据直线的斜率和截距计算出图像底部和某个高度的两个端点坐标。
def make_coordinates(image, line_parameters):
slope, intercept = line_parameters
y1 = image.shape[0]
y2 = int(y1*(3/5))
x1 = int((y1- intercept)/slope)
x2 = int((y2 - intercept)/slope)
return np.array([x1, y1, x2, y2])
接着,定义核心的优化函数。它将所有检测到的线段按斜率正负(代表左、右车道线)分组,分别计算平均斜率和截距,最后利用上面的函数得到两条代表车道线的长线段。
def average_slope_intercept(image, lines):
left_fit = []
right_fit = []
for line in lines:
x1,y1, x2, y2 = line.reshape(4)
parameter = np.polyfit((x1, x2), (y1, y2), 1)
slope = parameter[0]
intercept = parameter[1]
if slope < 0:
left_fit.append((slope,intercept))
else:
right_fit.append((slope,intercept))
left_fit_average =np.average(left_fit, axis=0)
right_fit_average = np.average(right_fit, axis =0)
left_line =make_coordinates(image, left_fit_average)
right_line = make_coordinates(image, right_fit_average)
return np.array([left_line, right_line])
现在,我们将前面分散的步骤整合成几个清晰的函数,并应用优化算法。
def canny_edge(image):
gray_coversion= cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
blur_conversion = cv2.GaussianBlur(gray_conversion, (5,5),0)
canny_conversion = cv2.Canny(blur_conversion, 50,150)
return canny_conversion
def show_lines(image, lines):
lanelines_image = np.zeros_like(image)
if lines is not None:
for line in lines:
X1, Y1, X2, Y2 = line.reshape(4)
cv2.line(lanelines_image, (X1, Y1), (X2, Y2), (255,0,0), 10)
return lanelines_image
def reg_of_interest(image):
image_height = image.shape[0]
polygons = np.array([[(200, image_height), (1100, image_height), (551, 250)]])
image_mask = np.zeros_like(image)
cv2.fillPoly(image_mask,polygons, 255)
masking_image = cv2.bitwise_and(image,image_mask)
return masking_image
# 主流程
image = cv2.imread('test_image.jpg')
lanelines_image = np.copy(image)
canny_image = canny_edge(lanelines_image)
cropped_image = reg_of_interest(canny_image)
lines = cv2.HoughLinesP(cropped_image, 2, np.pi/180, 100, np.array([]), minLineLength= 40, maxLineGap=5)
averaged_lines = average_slope_intercept(lanelines_image, lines)
line_image = show_lines(lanelines_image, averaged_lines)
combine_image = cv2.addWeighted(lanelines_image, 0.8, line_image, 1, 1)
cv2.imshow('result', combine_image)
cv2.waitKey(0)
cv2.destroyAllWindows()

可以看到,优化后的结果从一堆短线段变成了两条清晰、连贯的车道线,这更符合实际应用中对人工智能感知输出的要求。
第九步:扩展到视频处理
静态图像的检测是基础,而真正的应用场景如自动驾驶需要处理连续的动态画面。我们将上述流程封装,并应用于视频的每一帧。
首先,需要增强 make_coordinates 函数的鲁棒性,以处理视频中某些帧可能检测不到车道线的情况。
import cv2
import numpy as np
import matplotlib.pyplot as plt
def make_coordinates(image, line_parameters):
try:
slope, intercept = line_parameters
except TypeError:
slope, intercept = 0.001,0
#slope, intercept = line_parameters
y1 = image.shape[0]
y2 = int(y1*(3/5))
x1 = int((y1- intercept)/slope)
x2 = int((y2 - intercept)/slope)
return np.array([x1, y1, x2, y2])
average_slope_intercept 函数与图片处理版本一致。
def average_slope_intercept(image, lines):
left_fit = []
right_fit = []
for line in lines:
x1, y1, x2, y2 = line.reshape(4)
parameter = np.polyfit((x1, x2), (y1, y2), 1)
slope = parameter[0]
intercept = parameter[1]
if slope < 0:
left_fit.append((slope, intercept))
else:
right_fit.append((slope, intercept))
left_fit_average =np.average(left_fit, axis=0)
right_fit_average = np.average(right_fit, axis =0)
left_line =make_coordinates(image, left_fit_average)
right_line = make_coordinates(image, right_fit_average)
return np.array([left_line, right_line])
主视频处理循环:读取视频的每一帧,应用相同的检测流程,并将结果实时显示并保存为新视频。
cap = cv2.VideoCapture("test2.mp4")
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = int(cap.get(cv2.CAP_PROP_FPS))
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
out = cv2.VideoWriter('output.mp4', fourcc, fps, (width, height))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
canny_image = canny_edge(frame)
cropped_canny = reg_of_interest(canny_image)
lines = cv2.HoughLinesP(cropped_canny, 2, np.pi/180, 100, np.array([]), minLineLength=40, maxLineGap=5)
averaged_lines = average_slope_intercept(frame, lines)
line_image = show_lines(frame, averaged_lines)
combo_image = cv2.addWeighted(frame, 0.8, line_image, 1, 1)
out.write(combo_image)
cv2.imshow("result", combo_image)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
out.release()
cv2.destroyAllWindows()

源码与总结
本文涉及的完整代码和测试素材可在以下地址获取:
https://github.com/muhammeddincmdx/Sdcs-Part5
通过这个完整的项目,我们从零开始实现了一个基于传统计算机视觉和Python的车道线检测系统。整个过程涵盖了图像读取、灰度转换、滤波降噪、边缘提取、区域聚焦、直线检测以及结果优化等关键步骤,并成功从图片处理扩展到了视频实时处理。虽然现代方案更多采用深度学习,但这种基于传统算法的实现方式仍然是理解底层原理和入门计算机视觉的绝佳路径。你可以在云栈社区找到更多类似的实战项目与深入讨论。
 发表于 2026-3-21 03:34:42
|
查看: 188|
回复: 0
发表于 2026-3-21 03:34:42
|
查看: 188|
回复: 0
