
放弃残差连接之后,底层架构该怎么写?本文将还原我们将 Attention 机制引入层间连接,并最终形成 Attention Residuals 这一新架构的全过程。
这篇文章介绍我们团队近期的工作 Attention Residuals(AttnRes)[1]。顾名思义,这是用 Attention 的思路去改进传统神经网络中的 Residuals 连接。
关于层间连接结构的讨论从未停止,Pre Norm 和 Post Norm 之争大家可能都听说过,但这说到底仍是残差结构内部的“内斗”,后来很多 Normalization 的变化也大抵如此。
一个比较有意思的变化是 HC [2],它开始走向扩大残差流的路线。不过,或许是由于效果不够稳定,它当时并未引起太多反响。后来的故事大家都知道了,去年底 DeepSeek 提出的 mHC [3] 改进了 HC,并在更大规模的实验中验证了其有效性。
相比于继续沿着扩大残差流的路线前进,我们选择了一条更为激进的路线:直接在层间引入 Attention 机制来替代简单的 Residuals 连接。
当然,要将这个想法贯穿整个模型训练与推理流程,并使之可行,这其中涉及大量细节和工作。这篇文章,我将以第一人称的视角,分享我们探索 Attention Residuals 的心路历程、关键推导与最终方案。
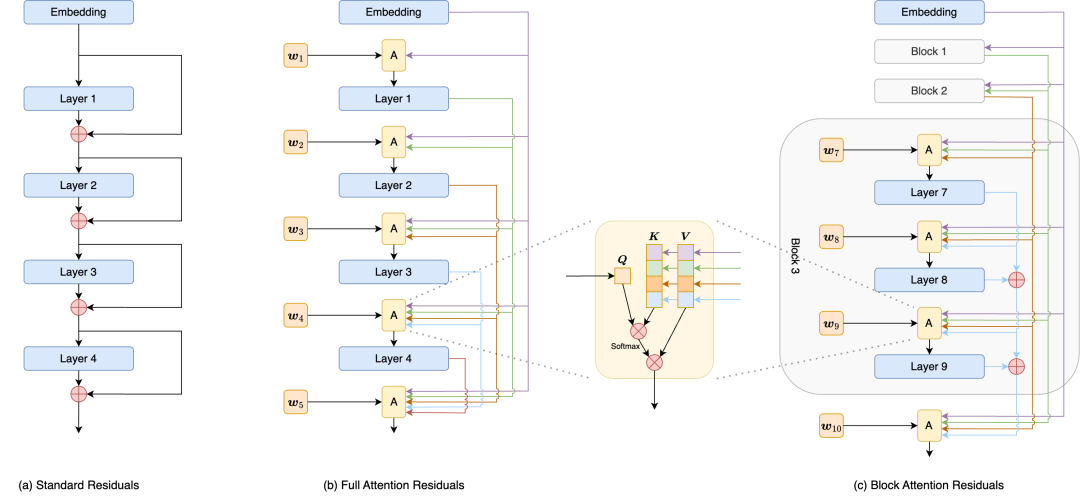
AttnRes 示意图
01. 层间注意力的思想萌芽
按照惯例,我们还是从经典的 Residuals [4] 说起。其形式大家早已耳熟能详:
x_t = x_{t-1} + f_t(x_{t-1}) \quad (1)
这里我们换一种写法,它能揭示出更深层次的含义。记 $y_t = f_t(x_{t-1})$,那么有 $x_t = x_{t-1} + y_t$。约定 $y_0 = x_0$,则易得 $x_t = x_0 + \sum_{s=1}^t y_s = \sum_{s=0}^t y_s$。于是,残差连接可以等价地写成:
y_{t+1} = f_{t+1}(y_0 + y_1 + \cdots + y_t) \quad (2)
即从 $y_t$ 的视角来看,Residuals 是将 $y_0$ 到 $y_t$ 进行等权求和,并将这个和作为 $f_{t+1}$ 的输入来计算 $y_{t+1}$。那么,一个非常自然的推广就是:将等权求和替换为加权求和:
y_{t+1} = f_{t+1}\left(\sum_{s=0}^{t} a_{t+1,s} y_s\right) \quad \text{where} \quad a_{t,s} \geq 0, \quad \sum_{s=0}^{t} a_{t+1,s} = 1 \quad (3)
这正是 AttnRes 思想的萌芽。上式对 $a_{t+1,s}$ 施加了两个约束,我们来讨论一下其必要性:
- 约束 $a_{t,s} \geq 0$ 保证了同一个 $y_s$ 对不同层的贡献始终是同向的,避免了某一层想要增大 $y_s$ 而另一层却想缩小 $y_s$ 的不一致情况,直觉上对模型的学习更为友好。
- 实践中,我们使用的 $f_t$ 通常包含 RMSNorm 层,而 RMSNorm 满足缩放不变性,即 $\text{RMSNorm}(cx)=\text{RMSNorm}(x)$ 对任意 $c>0$ 都成立。因此,在这种设定下,加权平均和加权求和完全等价,所以约束 $\sum_{s} a_{t+1,s}=1$ 并不会降低模型的表达能力。
02. 超级连接:层间注意力的另一种视角
在正式展开 AttnRes 之前,我们不妨简单回顾一下 HC,并证明它也可以被理解为一种层间注意力,这表明“层间注意力”是一条更为本质的技术路线。
HC(Hyper-Connections)将残差连接修改为:
X_t = H_t^{res} X_{t-1} + H_t^{post} f_t(H_t^{pre} X_{t-1}) \quad (4)
其中:
X \in \mathbb{R}^{k \times d}, \quad H^{res} \in \mathbb{R}^{k \times k}, \quad H^{pre} \in \mathbb{R}^{1 \times k}, \quad H^{post} \in \mathbb{R}^{k \times 1}
经典的设置是 $k=4$。简单来说,HC 将状态变量扩大 $k$ 倍,在输入到 $f_t$ 前,用一个 $H^{pre}$ 矩阵将其投影回1倍维度,输出后再用 $H^{post}$ 将其扩展回 $k$ 倍,最后与 $H^{res}$ 调制过的历史状态相加。
类似地,记 $Y_t = H_t^{post} f_t(H_t^{pre} X_{t-1})$,约定 $Y_0 = X_0$,我们可以将 HC 展开:
X_t = H^{res}_{t \leftarrow t-1} H^{post}_0 Y_0 + H^{res}_{t \leftarrow t-2} H^{post}_1 Y_1 + \cdots + H^{res}_{t \leftarrow t} H^{post}_{t-1} Y_{t-1} + H^{post}_t Y_t
其中 $H^{res}_{t \leftarrow s}$ 定义为 $H^{res}_{t} H^{res}_{t-1} \cdots H^{res}_{s+1}$。
进一步,令 $y_t = H_t^{pre} X_{t-1}$,我们可以写出:
y_{t+1} = f_{t+1}(H_{t+1}^{pre}x_t) = f_{t+1} \left(\sum_{s=0}^{t} H_{t+1}^{pre} H_{t-s+1}^{res} H_s^{post} y_s\right) \quad (5)
由于每个 $H_{t+1}^{pre} H_{t-s+1}^{res} H_s^{post}$ 都是一个标量,因此式 (5) 正是式 (3) 所示的层间注意力形式。熟悉 线性注意力 的读者应该能很快理解这个结果:HC 实质上可以看作“旋转了90度”的 DeltaNet。
在原始 HC 的实现中,三个 $H$ 矩阵由一个带 Sigmoid 激活的简单线性层计算得出。这导致连乘起来的 $a_{t+1,s}$ 存在爆炸或坍缩的风险,也无法保证其非负性。后来 mHC 对此进行了改进:它先将三个 $H$ 矩阵都改用 Sigmoid 激活来保证非负,然后通过交替归一化操作使其满足双随机性,利用双随机矩阵对乘法的封闭性来保证 $a_{t+1,s}$ 的稳定性,实验也验证了这些改进的有效性。
不过,也有一些新实验(如你的DeepSeek mHC可能根本不需要“m”约束)显示,将 $H^{res}$ 直接设置为单位矩阵也能取得很好的效果。
03. 众人拾柴:AttnRes的设计与演进
回到 AttnRes 本身。在确立了其可行性后,接下来的核心问题是:注意力权重 $a_{t+1,s}$ 应该采用什么形式呢?
一个很自然的想法是模仿标准的 Scaled Dot-Product Attention。但当时我们希望先快速尝试,因此选择了一个更简单的形式:
a_{t+1,s} \propto \exp(w_{t+1} \cdot y_s) \quad (6)
其中 $w_{t+1}$ 是一个可训练的向量参数。也就是说,直接用一个与数据无关的静态向量作为 Query,而以历史状态 $y_s$ 作为 Key 和 Value 来计算 Softmax Attention。这便是 AttnRes 的第一版设计。
令人惊喜的是,即便设计如此简单,相比原始残差连接的提升已经非常显著!当我在组内分享了初步实验结果后,@张宇 [6] 和@广宇 [7] 表现出极大的兴趣,并一同参与到后续工作中。我们开始在更大规模的模型上进行验证,发现结果同样令人欣喜。
在尝试了多种更复杂的设计后,我们发现它们大多不如这个简单的版本。唯一一个能带来稳定收益的改进是:为 Key 额外添加一个 RMSNorm 操作。这构成了 AttnRes 的最终形式:
a_{t+1,s} \propto \exp(w_{t+1} \cdot \text{RMSNorm}(y_s)) \quad (7)
然而,AttnRes 毕竟是一个密集型的层间连接方案,在 K2 甚至更大规模的模型上进行训练和推理,是否真的可行呢?
令人振奋的是,@V哥 [8] 经过精妙分析,首先从理论上肯定了推理阶段的可行性。其中的关键点,恰好是我们最初为了图方便而采用的静态 Q 设计!这使得在计算完所有 $y_s$ 后,我们可以提前计算好 $t > s$ 的注意力权重 $a_{t,s}$,为底层基础设施(Infra)的优化留出了足够的空间。
但另一方面,负责训练优化的同学(如@王哥 [9])经过仔细评估,认为在我们当时的训练环境下,这一“Full 版”的 AttnRes 开销仍然过大。需要一个能进一步降低通信和显存占用的方案。于是,“Block 版”的 AttnRes 应运而生。
04. 分块版本:效率与效果的折衷
从 Full AttnRes 到 Block AttnRes,本质上类似于将 $O(n^2)$ 复杂度的稠密 Attention 线性化的过程。各种已有的 Efficient Attention 思路都可以拿来尝试。
例如,我们第一个尝试的是滑动窗口注意力(SWA),但实际效果非常糟糕,甚至不如原始的残差连接。经过反思,我认为可以这样理解:残差连接本身已经是一个非常强的 Baseline,它对应于所有历史状态的等权求和。任何新设计想要超越它,其形式必须能够覆盖残差连接这一特例。
Full AttnRes 显然满足这个条件(只需令所有权重相等即可)。但加上 SWA 后,由于它“扔掉”了一部分历史状态,无法表示“所有状态等权求和”,因此可能破坏了模型本可以学习到的有效模式。
这让我们意识到,对于 AttnRes 而言,“压缩”可能比“稀疏”更有效,而且压缩也不需要太精细,简单的加权求和可能就足够了。
经过一番构思和打磨,@张宇和@广宇提出了论文中的 Block AttnRes 设计。它结合了分块处理和求和压缩的思想,取得了接近 Full 版的效果。
Block AttnRes 的核心思想是这样的:
- Embedding 层单独作为一个 Block:通过观察 Full 版的注意力矩阵(这也是引入注意力概念的一个好处——模式可解释、可可视化),我们发现模型倾向于给 Embedding 层分配可观的注意力,因此有必要将其独立出来。
- 其余层按每 $m$ 层划分为一个 Block:在每个 Block 内部,对层状态 $y_s$ 进行求和压缩,将这个求和结果作为整个 Block 的代表,然后再以 Block 为单位计算块间的注意力。
实验表明,只需固定划分为大约 8 个 Block,就能获得 AttnRes 所带来的大部分收益。
经过评估,训练和推理团队的同事一致认为,Block AttnRes 引入的额外开销很小,相比于其带来的效果提升是完全值得的。如果非要给一个数字,大致是 5% 以内的开销,换取 25% 的性能收益。于是,所有人全力推动其进入模型主线。
05. 矩阵视角:统一的理解框架
值得一提的是,我们还可以从注意力矩阵的视角,将 Residuals、HC/mHC、Full AttnRes 和 Block AttnRes 统一起来理解,这是一个非常有趣的视角。
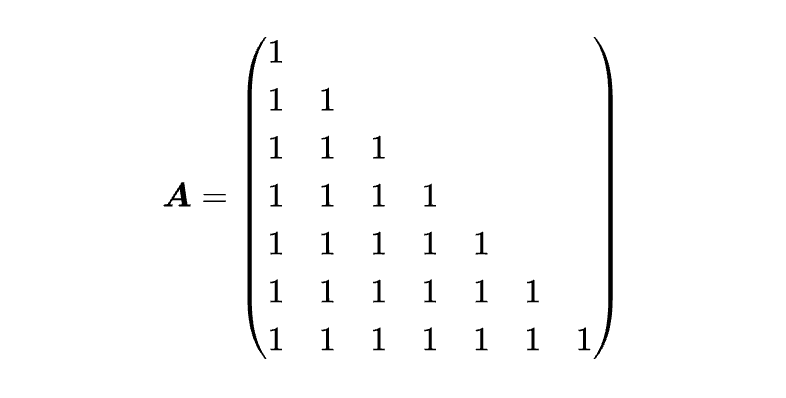
Residuals:对应一个所有元素为1的下三角矩阵,即等权求和。

HC/mHC:矩阵元素由 $H^{pre}$ 和 $H^{post}$ 的乘积组合构成,结构相对复杂。
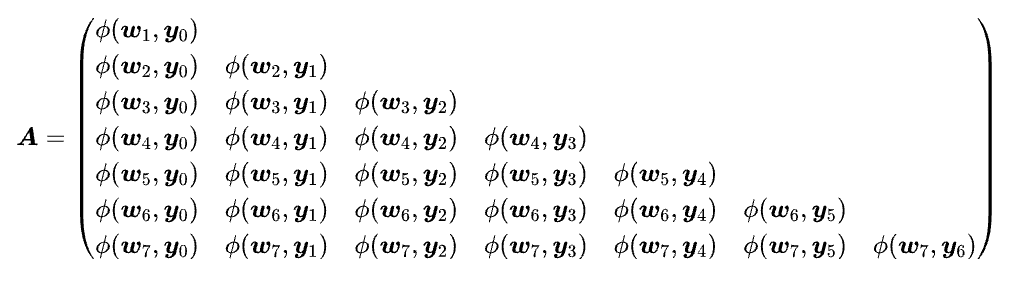
Full AttnRes:矩阵元素为 $\phi(w_i, y_j)$,是完全动态和密集的。
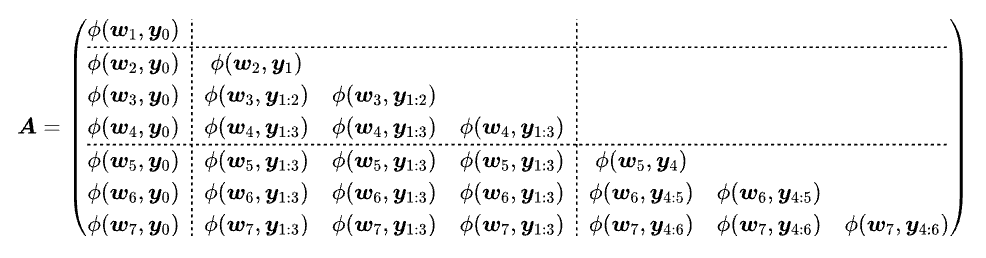
Block AttnRes:矩阵呈现出明显的分块结构,块内元素相同(代表求和压缩),块间动态计算。
在上图中,$A_{ij} = a_{i, j-1}$,Block 版中 $m=3$,且 $\varphi(w, y) = \exp(w \cdot \text{RMSNorm}(y))$。这个“$\varphi(w, y)$”的记号,我们在之前的文章《让炼丹更科学一些:新恒等式,新学习率》[10] 中也曾使用过。
06. 相关工作与我们的贡献
在计划推进 AttnRes 后,我和团队成员们就沉浸在了设计、验证与加速的循环中。我的研究习惯是,先尽最大努力独立推导和实验,直到遇到瓶颈或基本解决问题后,再去系统地调研相关文献。这一次,我们恰好也遇到了一群风格相似、充满热情的伙伴,使得 AttnRes 的探索整体上较为顺畅。
因此,直到所有核心测试基本通过、准备撰写技术报告时,我们才开始大规模查阅文献。结果是“不查不知道,一查吓一跳”,原来关于密集连接(Dense Connection)和深度注意力(Depth Attention)的工作已经非常多了。
除了经典的 DenseNet [11],我们还发现了 DenseFormer [12]、ANCRe [13]、MUDDFormer [14]、MRLA [15]、Dreamer [16] 等一系列工作。甚至早于 BERT 的 ELMo [17] 也部分应用了类似的设计。这些都被我们收录到了技术报告的参考文献中。
报告发布后,我们也收到了读者们指出的更多相关文献,如 SKNets [18]、LIMe [19]、DCA [20] 等。对于可能的遗漏,我们表示歉意和感谢,并会在后续修订中尽力补充。
然而,无论是读者还是我们作者自身,都需要对此保持一份理性。全面的文献综述实属不易,偶有疏漏在所难免。我们对所有相关的前沿工作都抱有崇高的敬意。
同时,我们也希望提醒大家关注 AttnRes 在“深度注意力”这个概念之外所付出的实质性工作。我们完全同意,在当今的深度学习领域,“深度注意力”或“层注意力”本身并不是一个全新的想法。但是,如何将其成功应用于足够大的模型,使其能够作为残差连接的有效替代,同时满足现代大规模模型训练和推理对效率的苛刻要求,这并非易事。
据我们所知,Attention Residuals 是首个在实践中系统性地解决了这些问题,并成功将其拓展到超大规模模型上的工作。 从数学推导到工程实践,从效率优化到最终部署,这其中的每一步都凝聚了整个团队的心血与智慧。
07. 文章小结
本文回顾了我们探索 Attention Residuals 的完整过程。这项工作的核心是用层间注意力机制替代朴素的残差连接,并通过一系列精巧的设计(如静态 Q、Key 归一化、分块压缩等),在保证强大表达能力的同时,满足了训练与推理的效率约束,最终成功地将这一新架构应用到了大规模模型中。
对于关注前沿模型架构、Transformer 改进以及开源实战项目的开发者而言,AttnRes 提供了一个既有理论深度又具备工程可行性的新思路。其探索过程本身,也体现了在深度学习领域从灵感到实现所需的技术思考与团队协作。我们期待这项关于层间连接的新探索,能为社区带来新的启发。
参考文献
[1] https://papers.cool/arxiv/2603.15031
[2] https://papers.cool/arxiv/2409.19606
[3] https://papers.cool/arxiv/2512.24880
[4] https://papers.cool/arxiv/1512.03385
[5] https://papers.cool/arxiv/1512.03385
[6] https://x.com/yzhang_cs
[7] https://x.com/nathancgy4
[8] https://zhuanlan.zhihu.com/p/2017528295286133070
[9] https://www.zhihu.com/question/2016993095078684011/answer/2017381145474508331
[10] https://kexue.fm/archives/11494
[11] https://papers.cool/arxiv/1608.06993
[12] https://papers.cool/arxiv/2402.02622
[13] https://papers.cool/arxiv/2602.09009
[14] https://papers.cool/arxiv/2502.12170
[15] https://papers.cool/arxiv/2302.03985
[16] https://papers.cool/arxiv/2601.21582
[17] https://papers.cool/arxiv/1802.05365
[18] https://papers.cool/arxiv/1903.06586
[19] https://papers.cool/arxiv/2502.09245
[20] https://papers.cool/arxiv/2502.06785
 发表于 2026-3-21 04:47:16
|
查看: 177|
回复: 0
发表于 2026-3-21 04:47:16
|
查看: 177|
回复: 0
