ICLR(International Conference on Learning Representations)是机器学习和人工智能领域最具影响力的年度学术会议之一,与 NeurIPS、ICML 并列为 AI 领域的三大顶级会议,特别聚焦于表示学习与深度学习的理论、算法和应用研究。
本文将重点解读该团队被 ICLR 2026 接收的六篇论文。

团队介绍
美团业务研发平台/搜推 ASX (Agentic System X)团队聚焦构建大模型为基础的 Agent 技术体系,在大模型后训练、Agentic 强化学习以及多模态理解等核心前沿方向持续深耕,已在 ICLR、NeurIPS、CVPR、AAAI 等 AI 领域的国际顶会发表数十篇高质量研究成果。
01 ResT:针对工具调用模型优化的 Token 级策略梯度方法
论文标题: ResT: Reshaping Token-Level Policy Gradients for Tool-Use Large Language Models
论文类型: Poster
论文下载: https://arxiv.org/abs/2509.21826
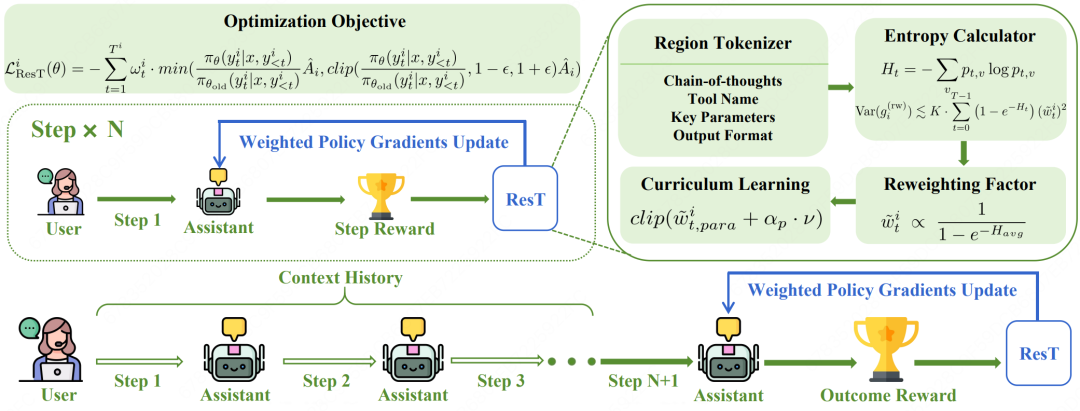
论文简介: 以实际 AI 搜索业务模型训练中遇到的问题为启发,本文提出多轮拆分的工具调用过程监督训练策略,并通过引入字符级别的 Critic 监督信号,以修正原始 GRPO 算法平均化优势值。研究首先建立了工具调用任务中策略熵与训练稳定性之间的理论关联,揭示出结构化、低熵的 token 是影响工具调用模型奖励的关键因素。
基于此,本文提出了面向工具调用任务的重塑 Token 级别的策略梯度优化算法(Reshaped Token-level policy gradients,ResT)。ResT 通过信息熵感知的 Token 级别的重加权控制策略梯度过程,在训练过程中逐步提升推理部分输出的权重占比。这种熵感知机制能够让 LLM 在 RL 训练中实现从结构正确性到语义推理的平稳过渡,并增强多轮工具调用任务的收敛稳定性。
在 BFCL V3 和 API-Bank 等公开 Benchmark 上的测试表明,ResT 相比于当前基线方法取得了最优性能,较现有基线方法最高提升 8.76%。基于 Qwen3-4B 基座训练的模型用 ResT 方法进行微调后,相比 GPT-4o 闭源思考类工具调用模型,在单轮任务中超越 4.11%,在多轮任务中高出 1.50%。目前,本文所提出的训练方法也成功应用到了小团算法自训练模型的迭代中,并在离线、在线的评测中拿到了实际收益。
02 SRFT:单阶段监督强化 LLM 微调
论文标题: SRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning
论文类型: Poster
论文下载: https://arxiv.org/pdf/2506.19767

论文简介: 本文聚焦于推理类大语言模型后训练中“监督微调(SFT)与强化学习(RL)如何更优结合”的关键问题。论文从熵与分布变化角度系统分析发现:SFT 会对策略分布产生“粗粒度、全局性”的概率重塑,而 RL 更像“细粒度、选择性”的局部修正;同时,训练熵可作为衡量两者协同与模型可塑性的有效指示器。
基于该洞察,论文提出单阶段方法 SRFT(Supervised Reinforcement Fine-Tuning),在同一训练过程中同时利用高质量示范数据与自探索 rollout:对示范样本同时施加 SFT 与离策略 RL 目标,并用重要性采样缓解行为策略不匹配;对自探索样本将正负奖励项拆解,并对正样本引入基于熵的自适应权重以避免过早熵塌缩、保持探索。
实验基于 Qwen2.5-Math-7B,在 AIME24、AMC、MATH500、Minerva、Olympiad 等五个数学推理基准上取得约 59.1 平均分,较强基线提升显著,并在 ARC-C、GPQA-D、MMLU-Pro 等 OOD 测试上进一步验证了泛化优势,表明熵感知的单阶段 SFT+RL 融合能更高效稳定地提升推理能力。
03 ViPER:驱动视觉语言模型实现自主感知进化
论文标题: ViPER: Empowering the Self-Evolution of Visual Perception Abilities in Vision-Language Model
论文类型: Poster
论文下载: https://openreview.net/pdf/8c0a4f334db2c4b6a73e2aa91579141b17dc7648.pdf
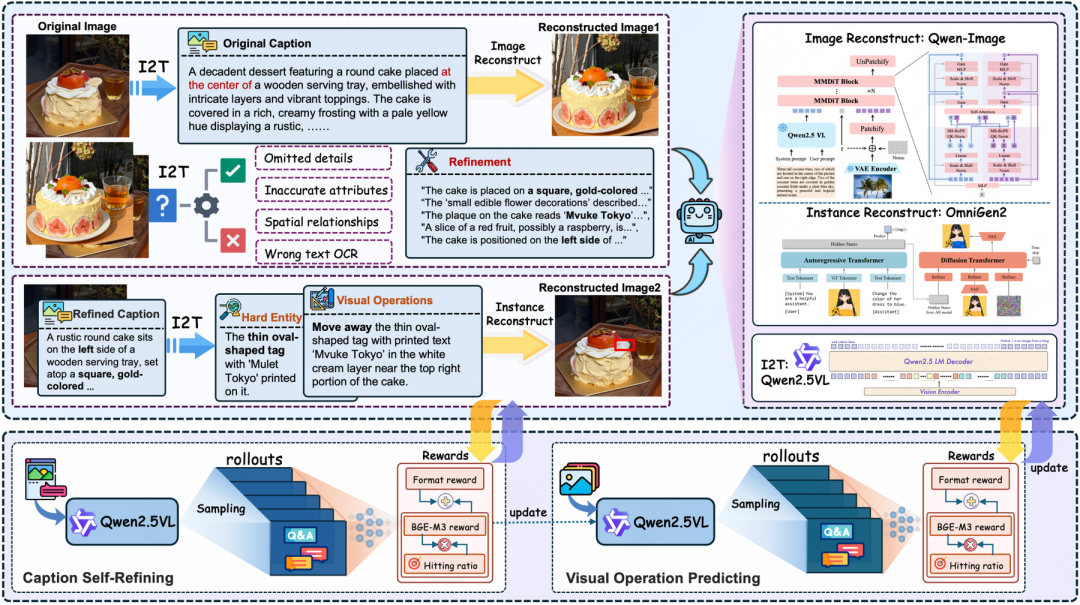
论文简介: 我们提出了一种新颖的双阶段任务,将视觉感知学习构建为从粗到精的渐进过程。基于这一任务框架,我们开发了 ViPER 框架,通过自我批判与自我预测实现迭代演进。
通过将图像级与实例级重建与双阶段强化学习策略协同整合,ViPER 构建了一个闭环训练范式,使内部合成的数据直接驱动感知能力的提升。应用于 QwenVL 系列模型后,ViPER 产生了 Qwen-Viper 系列模型。该模型在涵盖多种任务的七项综合基准测试中平均提升 1.7%,在细粒度感知任务上最高提升达 6.0%。Qwen-Viper 在不同视觉语言场景中持续展现卓越性能,同时保持泛化能力。除了实现感知能力的自我进化,ViPER 为生成与理解之间的互促关系提供了具体实证,这为开发更自主、更强大的视觉语言模型实现了重要突破。
04 基于SAE可解释特征的大语言模型后训练迁移能力预测
论文标题: SAE as a Crystal Ball: Interpretable Features Predict Cross-domain Transferability of LLMs without Training
论文类型: Poster
论文下载: https://openreview.net/pdf?id=KQYnfeBNjl
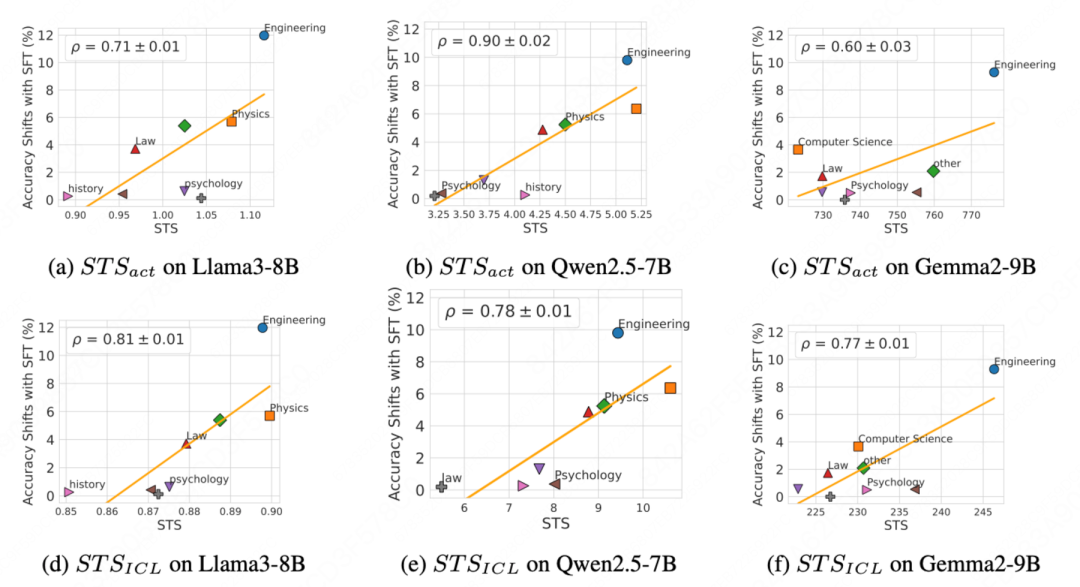
论文简介: 近年来,预训练大语言模型在多种任务上取得了显著的成功。除了自监督预训练的关键作用外,其在下游任务中的有效性还高度依赖于后续的后训练过程。在后训练阶段,模型会根据特定任务的数据和目标进行训练。然而,这一过程不可避免地会导致模型偏移,进而影响其在不同领域的性能。
针对这种偏移在不同下游领域如何互相影响,目前仍然缺乏深入的理解。为揭示这一黑箱过程,我们提出了基于稀疏自编码器(Sparse Autoencoders, SAEs)的迁移能力评分(SAE-based Transferability Score, STS),从而实现对后训练迁移性的预测。以监督微调为例,STS 能够识别 SAE 表示中的偏移维度,并计算其与下游领域的相关性,从而在微调前实现对迁移能力的可靠估计。
通过对多个模型和领域的大量实验,STS 在预测监督微调的迁移能力方面表现出高度准确性,其与实际性能变化的皮尔逊相关系数超过 0.75。此外,我们还尝试将 STS 扩展到强化学习后训练中。总的来说,我们认为 STS 作为一个可解释工具,可以为大型语言模型的后续训练策略提供明确的指导。
05 MAD-Logic: 基于多智能体辩论的大模型符号翻译与逻辑推理能力提升
论文标题: MAD-Logic: Multi-Agent Debate Enhances Symbolic Translation and Reasoning
论文类型: Poster
论文下载: https://openreview.net/pdf?id=rdE9qxGfIv
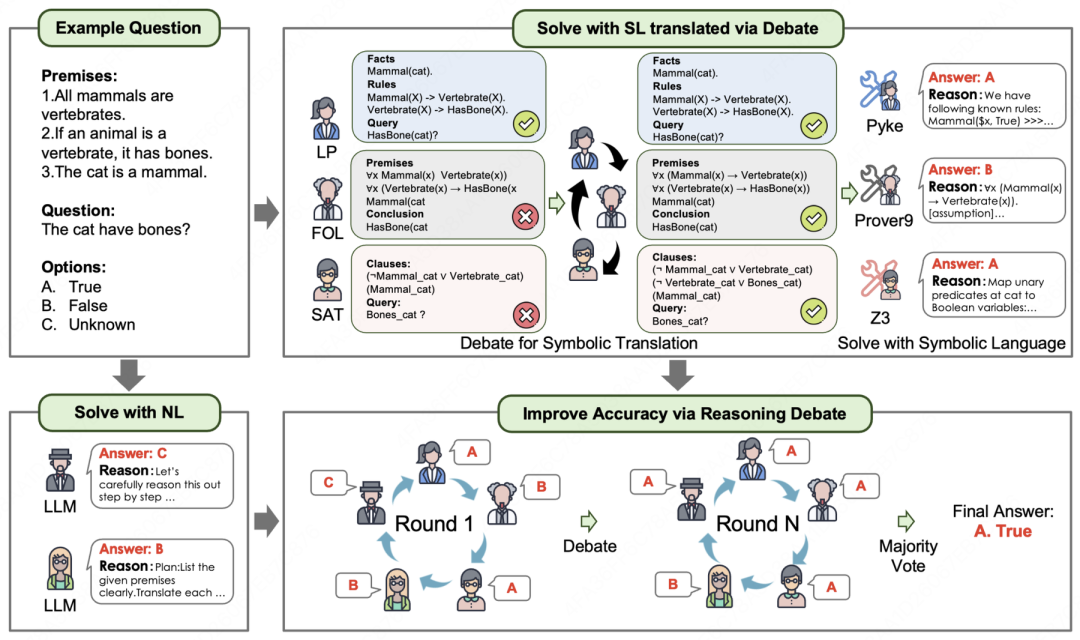
论文简介: LLM 在处理复杂逻辑推理问题时往往表现不佳。现有的提升方法可简要归纳为两类:(1) 将自然语言问题翻译为符号语言表示,进而通过调用符号求解器进行推理;(2) 利用 LLM 基于提示工程或微调在自然语言下直接进行推理。此前的方法主要集中于基于上述途径之一,并使用单一智能体来执行逻辑问答任务。然而,我们指出这两种方法都存在不可忽视的局限性。
例如,基于符号语言的方法极容易受到翻译错误的影响,导致求解器调用失败;而基于自然语言的方法则极依赖大模型自身的性能,且易产生幻觉等问题。基于对符号语言与自然语言推理之间、以及不同符号语言表示之间互补性的认识,我们针对复杂逻辑推理问题,提出了一种稀疏高效的多智能体辩论(Multi-agent Debate)方法,旨在融合各种方法的优势,主要体现在两个方面:(1)翻译阶段:多个智能体将自然语言翻译成多种不同的符号语言,并通过辩论修正翻译结果。(2)推理阶段:基于符号语言和自然语言进行推理的多个智能体进行多轮辩论和自我修正,将多智能体趋同的答案作为最终输出。
此外,针对多智能体辩论效率低下的问题,我们引入了自适应稀疏通信机制,根据智能体的置信度和信息增益剪枝掉不必要的信息交互。在多个合成与真实基准上的广泛实验表明,我们的方法在控制计算成本的同时,大幅提升了大模型的逻辑问答性能。
06 LogiConBench: 关于大模型逻辑推理一致性的评测基准构建
论文标题: LogiConBench: Benchmarking Logical Consistencies of LLMs
论文类型: Poster
论文下载: https://openreview.net/pdf?id=ULEHJkolxB
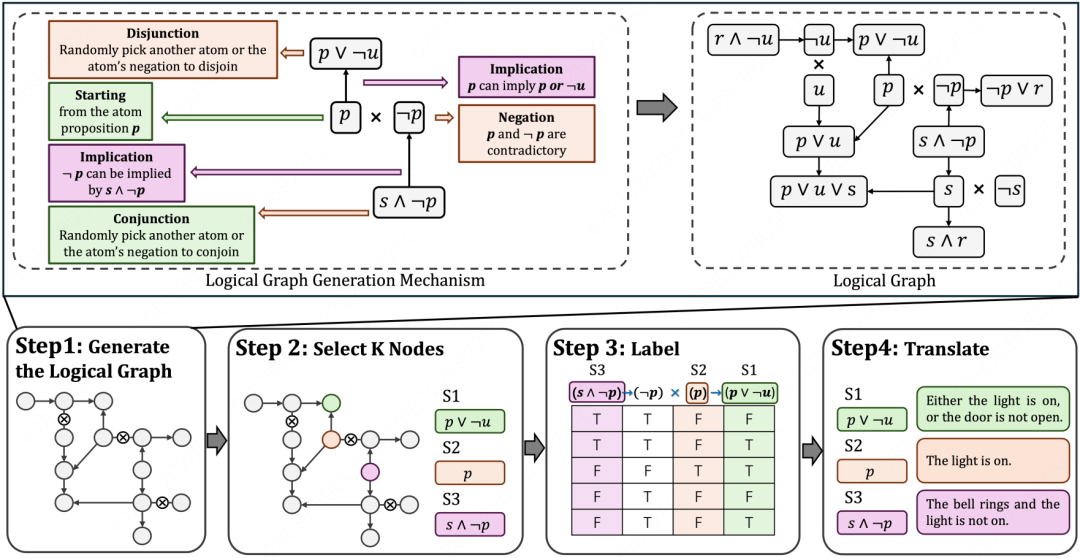
论文简介: 逻辑一致性(Logical consistency)要求对于不同问题,大语言模型(LLMs)的回答之间互不矛盾,符合逻辑推理规则。逻辑一致性是实现可靠逻辑推理的基础,当前的 LLMs 即便在简单的自然语言推断任务中也往往难以维持这种一致性。然而,现有评测 LLM 逻辑一致性的基准缺乏可扩展性、多样性且挑战性不足,甚至最先进的模型在这些基准上的准确率已超过 95%。
为弥补这一缺陷,我们构建了评测 LLMs 逻辑一致性的评测基准 LogiConBench ,该基准首次具备以下特性:(1) 提出并定义了评测逻辑一致性的不同任务与指标,(2)能够生成基于无限的逻辑推理有效式的样本,并提供具有显式推理路径的可控深度图;(3) 对最先进的 LLMs 依然极具挑战性,准确率低于 50%。具体而言,LogiConBench 自动生成逻辑关系图,其中节点表示命题符号,边表示推理关系。基于这些逻辑图,该基准采样命题列表,提取推理路径,确定所有符合一致性的标签列表,并将其转换为多样化的自然语言样本。
本文发布的 LogiConBench 是包含 28 万个样本的语料库,但事实上该样本生成框架具备扩展性,可生成无限量的数据。为了增强评估的显著性,我们在三个不同难度的任务上对 14 个前沿 LLMs 进行了评估,结果发现其中的枚举任务依然极具挑战性,其最高准确率仅为 34%。我们的代码和数据已开源。
以上六篇论文涵盖了从大模型基础后训练方法到多智能体协同推理的多个前沿方向,展现了美团技术团队在 Agent 技术体系上的深入思考与创新实践。对于希望深入了解相关技术的开发者,不妨前往 云栈社区 的人工智能板块,探索更多关于模型微调、强化学习和多智能体系统的讨论与资源。
 发表于 2026-3-21 04:49:56
|
查看: 443|
回复: 0
发表于 2026-3-21 04:49:56
|
查看: 443|
回复: 0
