强化学习的下一站:从监督到无监督
强化学习正在重塑大模型的能力边界。从 OpenAI o3、DeepSeek-R1 到 Gemini 3,顶尖模型都在用大规模 RLVR(可验证奖励强化学习)不断刷新推理任务的天花板。
但所有人都清楚一个现实:纯监督式训练是不可持续的。人工标注的成本呈指数级增长,在专业领域获取可靠标注越来越困难。当模型的能力逼近甚至超越人类专家时,谁来给它打分?
于是,无监督 RLVR(Unsupervised RLVR)应运而生,其核心目标是让模型在没有人工标注的情况下持续进化。这不仅是降本增效的需求,更被视为通往更高级智能的必经之路。就像预训练用海量无标注数据训练出了 GPT 系列,无监督 RLVR 能否在强化学习领域延续这一奇迹?

清华大学团队的一项最新研究,为这个看似美好的图景勾勒出了第一条清晰的边界。研究者系统性地剖析了无监督 RLVR 的内在机制,发现所有基于模型自身信号的内在奖励方法——无论是多数投票、熵奖励还是其他变体——都遵循着一条相似的轨迹:训练初期性能快速攀升,但到达某个临界点后,便开始不可逆地滑落。
这不是某个特定方法的缺陷,而是其内在机制的必然宿命:这些方法本质上都在“锐化”模型已有的偏好,就像一个回声室,让模型不断重复并强化自己最初相信的东西。如果初始的自信恰好与正确性对齐,效果可能惊人;但如果两者错配,模型的“坍塌”就只是时间问题。
但这并不意味着内在奖励毫无价值。在特定的小规模场景(如 Test-Time Training)中,它依然能稳定提升性能。更重要的是,研究者找到了一个“预言指标”,可以在投入大规模训练资源之前,预判模型的“可训练性”,避免无效的试错。
当内在奖励受限于模型自身的“回声”时,基于外部奖励的方法开始展现出不同的潜力,例如利用“生成”与“验证”之间的不对称性来锚定奖励信号。这类方法正在试图突破内在奖励的天花板,让无监督强化学习真正走向可扩展。
通往更强大智能的道路上,我们需要的或许不是盲目相信模型可以自我进化,而是清楚地知道:什么时候该让它倾听自己的回声,什么时候该把它推向真实世界的客观验证。
内在奖励方法:繁荣表象下的深层问题
过去一年,各种“内在奖励”方法密集涌现。从多数投票到基于模型自信度或熵的各种变体,它们都试图利用模型自身的内在信号来构造代理奖励(proxy reward)。在训练前期,这些方法往往能带来性能的飙升,甚至一度超过有监督的方法。
研究者将这些方法根据奖励信号的来源归纳为两类:
- 基于确定性(Certainty-Based):直接取模型在推理轨迹上的置信度指标(如概率、熵)作为奖励。
- 基于集成(Ensemble-Based):通过多次采样生成(rollout)后,用集成结果(如多数投票)来判断答案的正确性,并以此作为奖励。

然而,免费的奖励信号背后,往往隐藏着昂贵的代价。在早期性能飙升之后,继续训练通常会触发典型的“奖励黑客”(reward hacking)现象:
- 代理奖励(proxy reward)的数值可能还在持续上涨,但模型在真实任务上的性能(performance)却已经开始崩溃。
- 模型对自身生成的答案越来越“自信”,但这些答案却可能越来越离谱。
- 不同的内在奖励方法,在不同的大语言模型上表现差异巨大,缺乏一致性。
更关键的问题是,没人能说清楚这些方法为什么有效,又为什么最终会失效。这种不确定性,严重阻碍了无监督 RLVR 的可扩展性。
核心工作:拆开黑箱,划清边界
研究者没有止步于提出另一个“刷点”的新方法,而是致力于回答那个根本性问题:无监督 RLVR 的扩展上限究竟在哪里?如果存在上限,它的边界又由什么决定?
为此,他们从五个维度展开了系统性研究:
- 建立统一理论框架:将五花八门的内在奖励方法归结到同一个机制之下,揭示其“殊途同归”的本质——锐化模型的初始分布,并给出了理论上的收敛边界。
- 进行大规模实证分析:在11个不同模型、5种内在奖励方法上进行广泛的超参数扫描,用数据证实“先升后降”并非偶然,而是一个普遍规律。
- 界定“安全区”:研究发现,并非所有场景都会崩溃。在小规模的测试时训练(Test-Time Training)中,内在奖励可以安全使用,即使初始答案全错,模型也能稳定进化。
- 化“陷阱”为“路标”:“上升-下降”曲线本身蕴含着信息。研究者据此提炼出一个轻量级的模型先验指示器,无需跑完昂贵的完整RL训练曲线,就能预判一个基座模型是否适合进行强化学习。
- 探索替代方案:既然内在奖励存在天花板,研究者将目光投向外部奖励方法。他们初步探索了基于“生成-验证不对称性”的外部奖励,检验其能否真正突破内在奖励的扩展极限。
四个关键发现
🔍 发现一:成败取决于“置信度-正确性”的对齐程度
研究者建立的理论框架揭示,所有内在奖励方法的本质是 “锐化分布”,即放大模型已有的偏好,而非创造新的知识。这一机制导致了一个关键特性:
- 如果模型初始的倾向是正确的 -> 锐化有效,性能提升。
- 如果模型初始的倾向是错误的 -> 锐化有害,加速崩溃。
他们定义模型的这种初始倾向为 “置信度-正确性”对齐程度。一个先验较强的模型,本身已经掌握了解决问题的大部分知识,只是不够“自信”以至于无法稳定输出正确答案。
在对11个模型、5种方法进行大规模测试后,结论似乎有些残酷:崩溃几乎不可避免,只是个时间问题。即使是最稳定的配置也撑不过几个训练周期(epoch)。这表明问题可能并非工程上的瑕疵,而是数学上的必然。
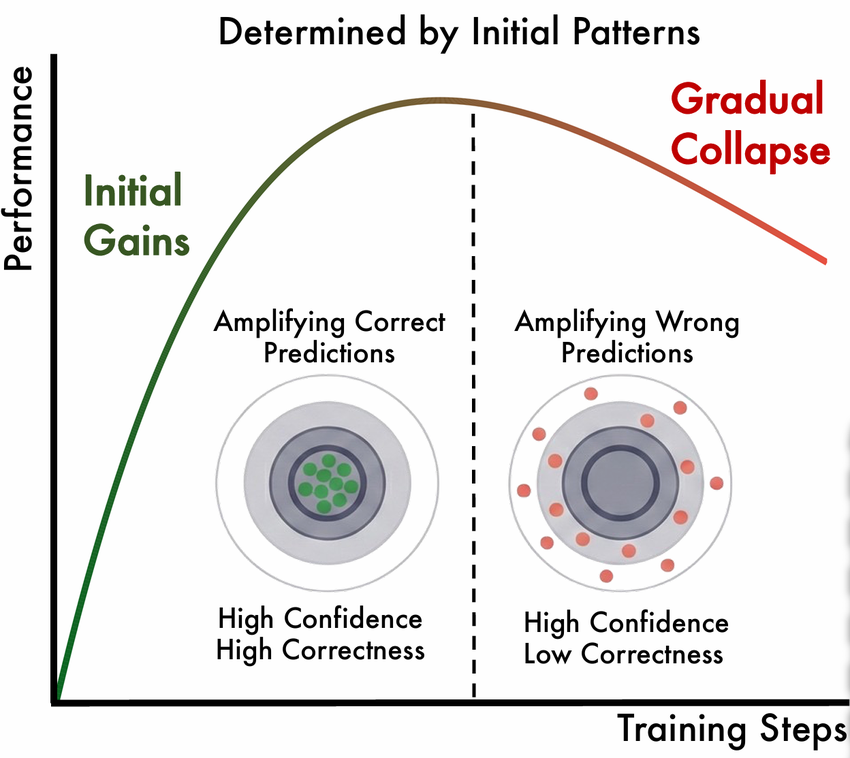
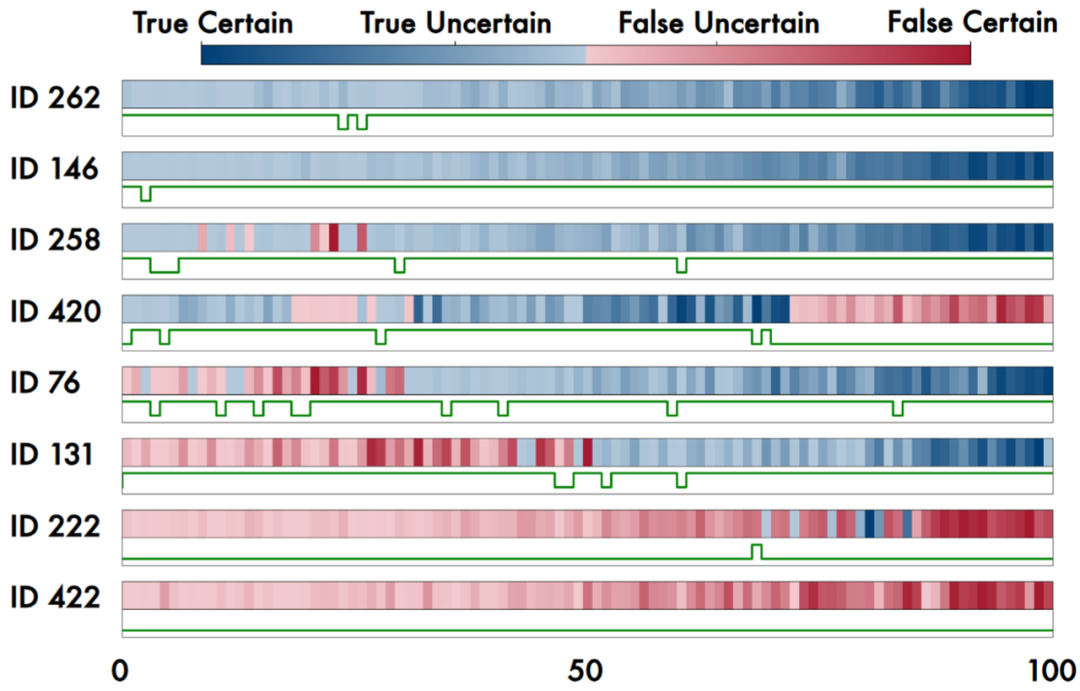
左图:模型训练的成败取决于初始置信度与正确性的对齐程度;右图:单条数据上置信度与正确性随训练过程的演化。
✅ 发现二:小规模场景下反而安全
“先升后降”虽是普遍宿命,但有其适用范围。当训练数据量足够少时,比如在特定领域的测试时训练(Test-Time Training)场景中,内在奖励方法反而展现出难得的稳定性。
原因很直观:只在少量样本上优化模型的“自信度”,模型的优化很快就会达到局部饱和。即便它在这些少数样本上变得“超级自信”,也难以引发全局性的策略偏移,因此在分布外(OOD)任务上的准确率依然能保持稳定。
一个更极端的实验是:研究者刻意选取了32条模型初始回答全部错误的样本作为训练集。也就是说,内在奖励给出的代理奖励从一开始就是错的。结果如何?在OOD测试集上,模型的性能依然得到了稳定提升。
这说明,内在奖励主要是在教模型“更相信自己”,而不是在教它“什么是对的”。即使“信错了”,这种自我强化也被牢牢限制在局部数据上,难以泛化造成全局性灾难。
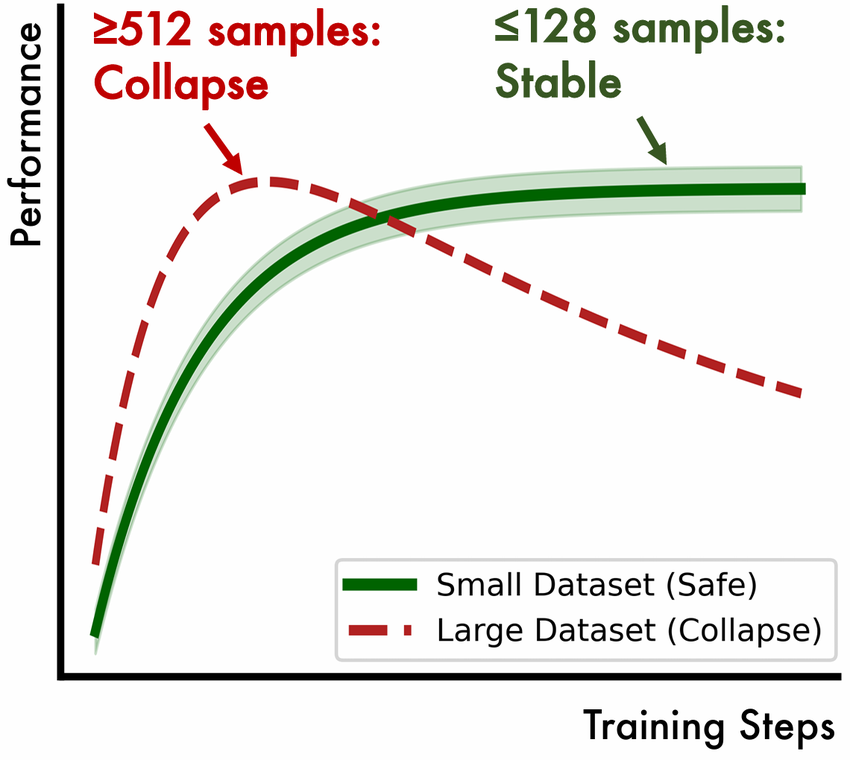
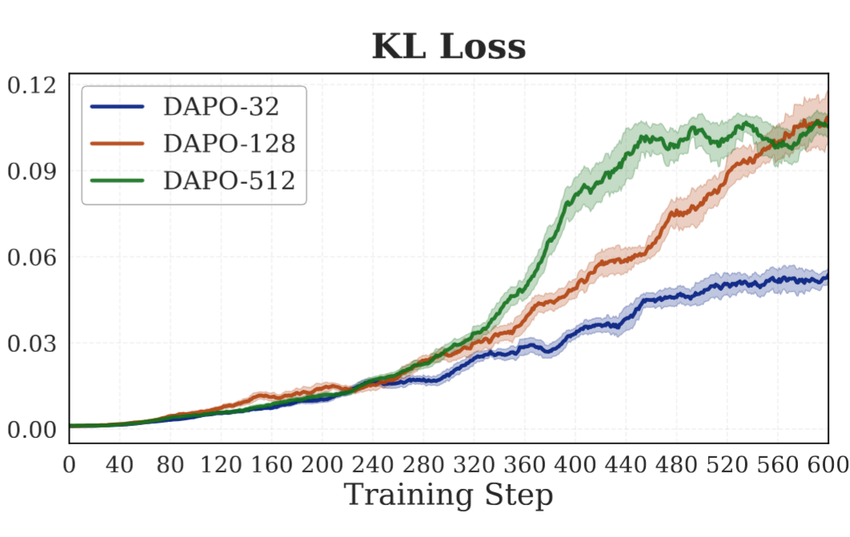
左图:小规模测试时训练(TTT)下性能稳定提升,未发生崩溃;右图:不同训练集规模下,策略相对于初始策略的KL散度偏移。
🎯 发现三:如何判断一个模型是否“适合做RL”
“上升-下降”曲线不仅是风险信号,其本身也承载着有价值的信息。既然内在奖励的成败取决于模型初始的“置信度-正确性”对齐度,那么能否利用这个对齐度,提前判断一个基座模型是否适合进行强化学习呢?毕竟,跑一次大规模RL训练的成本非常高昂。
研究者找到了一把“尺子”:模型坍塌步数,即测量一个模型在内在奖励训练下,能坚持多少步才发生完全崩溃。逻辑很简单:崩溃得越晚,说明模型的初始先验越好,它本身就掌握了更多正确的知识,只是不够自信。而这种良好的先验,恰恰是标准有监督RL能够进一步放大的东西。
实验结果印证了这一点。像 Qwen 系列这种业界公认“适合做RL”的模型,在内在奖励训练下坚持的步数也更长。更有趣的是,这个 “模型坍塌步数”指标无需任何人工标注(ground truth),但其在预测模型经有监督RLVR后能获得多大性能提升方面,准确率甚至超过了传统的 pass@k 指标。
这实现了从“昂贵试错”到“轻量预判”的转变,把内在奖励的失败点,变成了评估模型RL潜力的“路标”。
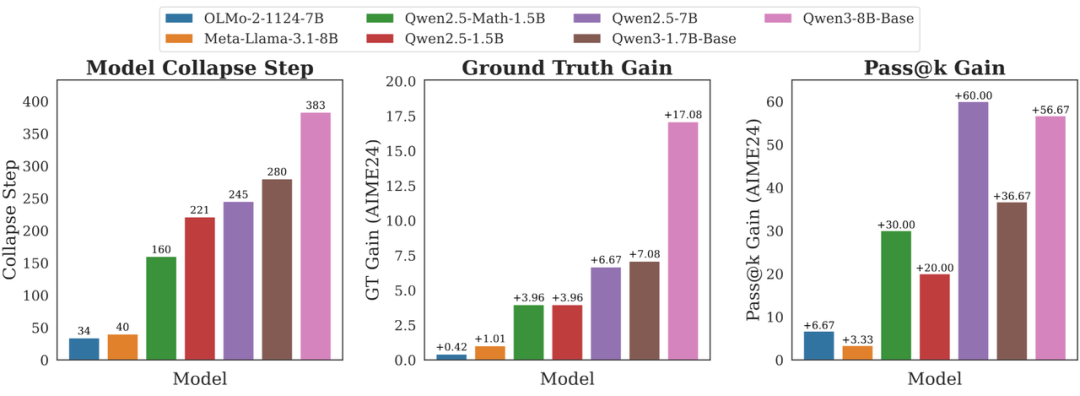
图表展示了不同基座模型在无监督内在奖励训练下的模型坍塌步数(左)、以及对应模型经过有监督RLVR后的性能增益(中)。结果显示,在无监督训练中崩溃越晚的模型,后续有监督RL的效果也越好。
🚀 发现四:外部奖励才是可扩展的真正方向
如果内在奖励注定存在天花板,那么无监督RLVR的未来之路在何方?问题的根源在于奖励信号的来源。内在奖励用模型自己的置信度来训练模型自己,这形成了一个闭环的“回声室”,奖励信号永远无法超越模型已知的知识范畴。
但无监督RLVR的天地不止于此。研究者将外部奖励方法归纳为两类:
- 利用无标注数据:从海量无标注语料中挖掘潜在的奖励信号。数据越多,信号越丰富,不会因为模型自身变强而枯竭。
- 利用生成-验证的不对称性:让模型自己生成答案,然后使用外部工具(如编译器、数学证明检查器、物理模拟器)进行客观验证,并提供环境反馈。这些验证器的判断不依赖于模型的自信度,因此是客观且稳定的。
研究者初步测试了自验证方法,结果展现出一条与内在奖励截然不同的学习曲线:性能持续改进,没有出现崩溃。原因在于,奖励不再来源于“模型有多自信”,而是来源于“答案能否通过外部客观验证”。生成一个复杂解法可能很难,但验证其正确性往往相对简单。这种不对称性,将模型的进化过程锚定在了真实世界的客观规律上,而非其自身的“回声”之中。
内在奖励在问:“你相信自己吗?”,而外部奖励在问:“这是真的吗?”。通往可扩展的无监督强化学习,答案或许更倾向于后者。

写在最后:认清边界,方能超越边界
我们描绘了无监督强化学习的诸多边界,但这张“地图”的价值,从来不在于简单地宣告“此路不通”,而在于清晰地指出:在什么条件下,哪一条路是通的。
一个系统能否通过自我审视而变得更好,根本上取决于它最初的判断有多准确。内在奖励方法失败的原因,恰恰也是它可能成功的原因,都源于同一个机制:自我强化。区别仅在于,被不断强化的是真理,还是偏见。
当我们真正认清了内在奖励的机制与宿命,才能更清晰地看到外部奖励所展现的星辰大海。通往可扩展的无监督强化学习,需要的不是对模型自我进化能力的盲目信仰,而是一种明智的“工具思维”:知道在何时、何种场景下,应该让模型倾听自己的“回声”进行微调;又该在何时,必须将其推向真实世界的“铁律”进行锤炼与验证。
内在奖励与外部奖励并非对立,它们是技术工具箱中不同的工具。认清各自的边界,不是为了让我们止步不前,而是为了 在边界之内进行更自由、更高效的创造,同时勇于在边界之外,探寻那些全新的、更具潜力的可能性。关于模型训练与AI前沿的更多深度讨论,欢迎访问云栈社区与同行交流。
 发表于 2026-3-22 03:08:59
|
查看: 214|
回复: 0
发表于 2026-3-22 03:08:59
|
查看: 214|
回复: 0
