想象一下,你戴着苹果的Vision Pro,一边在古堡里漫步,眼前的世界就一边被实时、高精度地重建成了3D模型。或者你的扫地机器人,不需要提前测绘,自己溜达一圈就能给你画出一张细节满满的3D户型图。
这背后离不开一项核心技术:SLAM (Simultaneous Localization and Mapping,即时定位与地图构建)。简单说,就是让机器在未知环境中,一边“看”一边确定自己的位置(定位),一边把“看到”的东西构建成地图(建图)。
最近,AI领域的大杀器——多视角几何基础模型(比如能从一个视频里直接猜出3D结构和相机位姿的模型)横空出世,大家以为SLAM的春天来了:直接把模型预测的结果喂给SLAM,岂不是又快又好?
但现实很骨感。直到上海人工智能实验室、上海交大等机构联合提出的M³出现,才真正打通了这个任督二脉。这个M³可不是手机型号,它的全称是 “Dense Matching Meets Multi-View Foundation Models for Monocular Gaussian Splatting SLAM”。
它到底做了什么?简单讲,它发现并修补了之前“基础模型+SLAM”方案中的一个关键漏洞,让单目视频的实时3D重建,既拥有了基础模型的“大局观”,又具备了SLAM所需的“像素级强迫症”,结果就是精度和速度的双双飙升。
痛点剖析:为什么现有SLAM+基础模型组合不给力?
要理解M³的厉害,得先知道之前的方案为啥会“卡脖子”。
以前的SLAM,像一位严谨的测绘员,通过在两幅图像间寻找大量的特征点对应关系(比如窗角对窗角,门框对门框),用几何原理一点点反推出相机运动和3D结构。这个过程很准,但慢,且对纹理不好的地方(比如白墙)容易抓瞎。
多视角基础模型(比如Pi3X)的出现,像给机器装上了“透视眼”。给它一段视频,它能直接“猜”出每帧图像的深度、相机位姿,输出一个粗糙的3D点云。这大局观有了,速度也快(一次前向传播就行)。
于是大家就想:用基础模型输出的位姿和3D点作为SLAM的“优质初值”,岂不美哉?但一做就发现不对劲。
根本矛盾在于:SLAM后端优化(Bundle Adjustment)需要极其精确的像素级密集对应关系作为约束,而大多数多视角基础模型只管“猜”整体几何,压根不关心“这个像素到底对应着另一张图的哪个像素”。
这就好比,基础模型告诉你:“这栋楼大概在这个位置。” SLAM问:“很好,但请具体指出左边这扇窗户的窗框,在上一张图里对应的是哪一部分?” 基础模型:“呃...大概...也许是那一块?”
没有精确的像素级对应,SLAM的优化就成了无米之炊,导致轨迹漂移、重建出现“鬼影”。现有的方案要么计算冗余(成对处理图像),要么几何精度不够,一直没解决这个核心矛盾。
核心创新:给基础模型装上“像素级对齐”的眼睛
M³的解决方案非常巧妙,它没有重新发明轮子,而是选择“升级”现有的强大基础模型。它选取了表现优异的多视角模型Pi3X,然后做了一个关键手术:给它加装一个“密集匹配头”(Dense Matching Head)。

图:M³ 的整体流程框架图。该框架包含用于位姿估计的联合跟踪与全局优化,以及用于场景重建的建图器。对于单目序列,增强后的Pi3X模型在一次推理中处理检索到的历史关键帧和新帧,以帮助构建因子图和选择关键帧。高斯点遵循ARTDECO的神经高斯与LOD架构进行初始化和优化。
这个匹配头是干嘛的?原来,Pi3X一次能处理多帧图像,输出每帧的3D点云、相机位姿和置信度。现在,匹配头同时为每一帧的每一个像素,生成一个高维的“特征描述符”和一个匹配置信度。
你可以把“特征描述符”想象成每个像素的“身份证”,包含了它的外观、几何上下文等信息。当需要找两帧图像中像素的对应关系时,不用蛮力全局搜索,而是:
- 几何引导: 利用基础模型预测的位姿,把一个像素的3D点投影到另一帧图像上,得到一个大概位置。
- 局部特征匹配: 只在这个大概位置周围一个小范围内,比较像素“身份证”(特征描述符)的相似度,找到最匹配的那个。
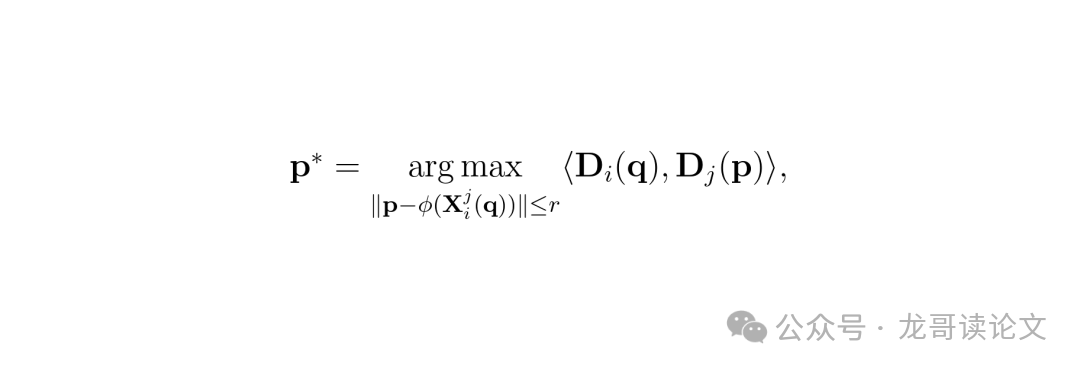
这个公式 $p^* = \arg \max \langle D_i(q), D_j(p) \rangle, \ ||p - \phi(X_i^j(q))|| \le r$ 描述了像素级匹配过程:在投影点附近半径 r 的区域内,寻找特征描述符 D 最相似(〈,〉表示内积)的像素 p*。
这样,M³就实现了“鱼与熊掌兼得”:既有多视角基础模型提供的强大几何先验和高效多帧处理能力,又能产出SLAM渴求的、精确的像素级密集对应关系。这正是当前人工智能与几何视觉交叉领域所追求的目标。
动态区域?直接“无视”!
现实场景中总有走动的人、开过的车。这些动态物体会严重干扰静态场景的重建。M³利用它新获得的“特征描述符”能力,顺带实现了一个巧妙的动态区域检测模块。
原理很简单:对于静态背景,相邻帧间同一位置的特征描述符经过运动补偿后应该很相似;对于移动的物体,特征就对不上了。通过计算这种特征一致性,M³可以生成一个“运动图”,标记出动态区域,在后续优化和重建中自动降低这些区域的权重或直接忽略,从而得到更干净、一致的静态场景模型。
高效框架:一次推理,搞定跟踪与优化
有了“增强版”基础模型,M³设计了一个非常高效的流式处理框架。传统SLAM通常把“跟踪”(估算新帧位姿)和“全局优化”(联合优化所有关键帧位姿)分开,导致基础模型要被反复调用,效率低下。
M³的做法很聪明:它维护一个包含历史关键帧和新来帧的滑动窗口。将整个窗口(例如8帧)一次性送入增强的Pi3X模型。只做一次推理,得到的输出就有双重用途:
对于新帧: 直接获得初始位姿、点云和特征描述符,用于实时跟踪和判断是否选为新的关键帧。
对于历史关键帧和新帧一起: 它们之间的密集匹配关系被用来构建和更新一个全局的“因子图”,后端基于这个图对所有关键帧位姿进行联合优化,确保全局一致性。
这种“一次前向传播,服务前后端”的设计,极大地减少了计算冗余,提升了效率。
用3D高斯泼溅进行惊艳重建
定位(SLAM中的L)搞定了,接下来是建图(SLAM中的M)。M³选择了目前渲染质量和速度平衡得最好的显式表征——3D高斯泼溅(3D Gaussian Splatting, 3DGS)。
它不像NeRF那样隐式地学习一个复杂的神经网络(辐射场),而是用一大堆可以优化的小椭球(高斯)来显式地表达场景。这些高斯有自己的位置、颜色、大小、透明度等属性。渲染时,它们被“泼溅”到屏幕上,速度快且效果逼真。
M³在获得精确的相机轨迹后,从关键帧出发,利用预测的深度和前面提到的动态区域掩码,智能地初始化这些3D高斯。然后通过优化,让这些高斯从各个视角渲染出来的图像,都和实际拍摄的图像尽可能一致,从而得到一个高保真的3D场景模型。这种从单目序列到高精度重建的完整流程,可以在云栈社区的“智能与数据”板块找到更多相关讨论。
实验结果:室内外通吃,精度速度双丰收
理论很美好,实战行不行?论文在ScanNet++、ScanNet、KITTI、Waymo等多个权威的室内外数据集上进行了全面测试,对比了包括DROID-SLAM、VGGT-SLAM 2.0、ARTDECO等在内的众多前沿方法。
结果相当能打,我们直接看干货:
1. 定位精度(ATE RMSE)全面领先:

表:在多个数据集上与最先进SLAM框架的定位精度对比(ATE RMSE,单位:米)。ATE越小越好。
可以看到,M³在几乎所有数据集上都取得了最低的绝对轨迹误差(ATE)。特别是在ScanNet++上,相比之前的优秀方法VGGT-SLAM 2.0,ATE降低了64.3%;在KITTI这样的大规模户外数据集上,优势也非常明显。这证明了其“像素级密集匹配”对于提升几何优化精度的关键作用。
2. 重建与渲染质量鹤立鸡群:
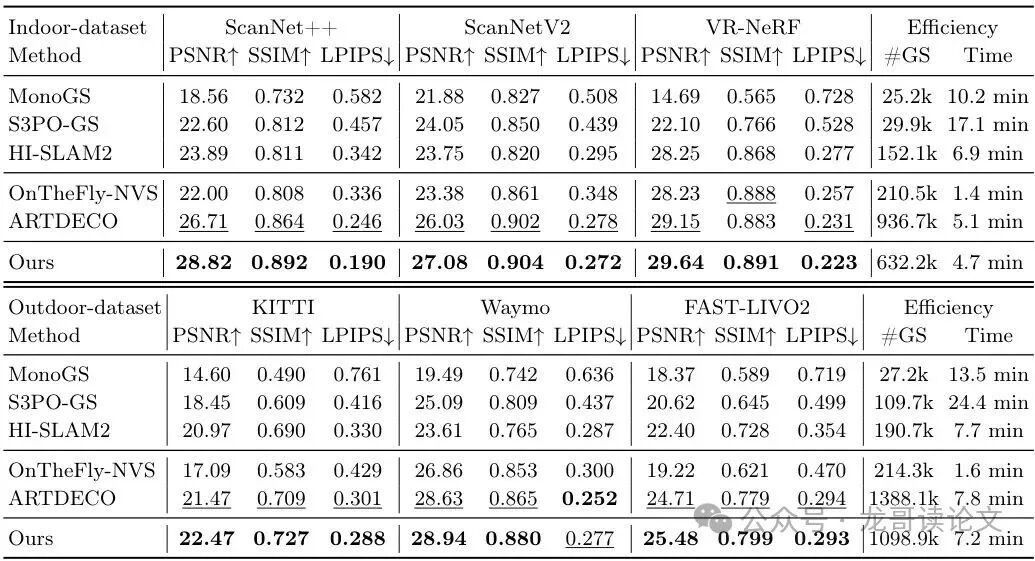
表:在室内外数据集上的渲染质量与效率对比。PSNR(峰值信噪比)、SSIM(结构相似性)越高越好,LPIPS(学习感知图像块相似度)越低越好。#GS是重建所用的高斯数量,Time是训练时间。
在重建质量的核心指标PSNR上,M³在多数场景下都是第一。例如在ScanNet++上,它比之前的最佳方法ARTDECO还高了2.11 dB。同时,它的训练时间还更短(4.7分钟 vs 5.1分钟),实现了质量与效率的双重提升。更少的高斯数量(#GS)也意味着模型更紧凑。
3. 视觉效果一目了然:
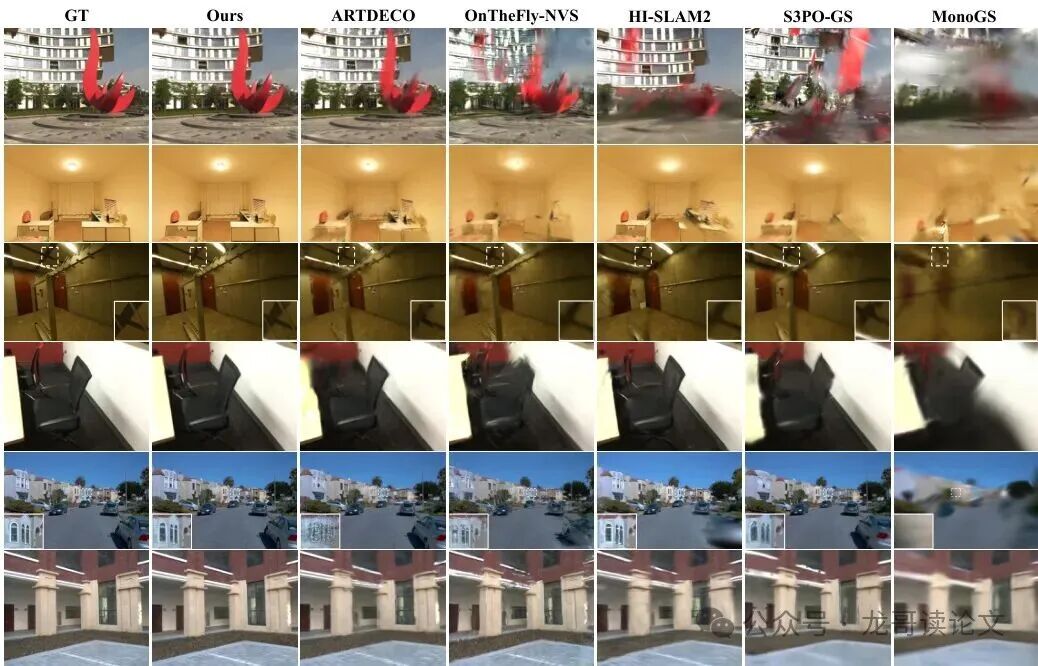
图:与流式重建基线方法在多个数据集上的渲染质量定性对比。M³在复杂环境下(如白色矩形框区域)保留了高保真的渲染细节。
光看数字可能不够直观,看看上面的对比图。在白框标出的细节区域(比如椅子腿、桌面物品),M³的重建结果明显更清晰、锐利,伪影更少。这就是精确几何约束带来的红利。
未来展望:更鲁棒、更融合的下一代SLAM
M³为“基础模型+SLAM”的融合提供了一个非常扎实的范本。它精准地找到了当前融合中的瓶颈,并用一个相对轻量的修改(加匹配头)解决了核心问题。
展望未来,这条路还可以走得更深更远:
更强的泛化与动态处理: 虽然M³已经能处理一般动态物体,但对于极端运动、完全遮挡等情况,鲁棒性仍有提升空间。结合更强的视频理解基础模型,或许能实现更智能的场景理解与分解。
多模态深度融合: 除了视觉,激光雷达(LiDAR)、惯性测量单元(IMU)等传感器的信息如何与视觉基础模型更优雅地融合,是迈向全天候、全地形可靠SLAM的关键。
端到端可微架构: 目前M³的流程中,基础模型和SLAM优化还是相对独立的。未来,探索更彻底的端到端可微架构,让基础模型能直接接收SLAM优化的反馈进行自我改进,可能会催生出更强大的“感知-建图”一体模型。
总结与常见问题
SLAM到底是什么?能举个生活中的例子吗?
SLAM(即时定位与地图构建)就像是机器人的“内在GPS”加“记忆绘图师”。举个例子:你蒙着眼睛在一个陌生的房间里走路,你用手触摸墙壁、家具(感知),在心里估算自己走了几步、转了多大角度(定位),同时根据触摸到的信息在脑海里画出一张房间布局图(建图)。整个过程同时进行,就是SLAM。扫地机器人、无人机自动驾驶、AR眼镜的空间定位,都离不开它。
论文里总说的“密集匹配”到底有多重要?
至关重要,它是高精度SLAM的“生命线”。你可以把它想象成玩“找不同”游戏时,在两个相似图片间画出无数条精确的连线。每一条连线都提供了一个几何约束:“A图片的这个点,在3D空间中,必须和B图片的那个点是同一个点”。这样的连线(约束)越多、越精确,反推出来的3D结构和相机运动就越准。M³的核心贡献就是让基础模型具备了产生这种高质量“连线”的能力。
3D高斯泼溅(3DGS)和NeRF有什么区别?
两者目标都是从一个图像集合中重建出3D场景,但“打法”不同。NeRF像一个“隐士”,它学习一个复杂的神经网络(辐射场),你问它“从某个视角看某个位置是什么颜色?”,它经过一通计算给你答案。渲染质量高,但速度慢。3DGS像一个“显摆的富豪”,它直接撒一大把“智能色块”(高斯),每个色块自带位置、颜色、大小等属性。渲染时,把这些色块按照视角投影到屏幕上就行,速度极快,且质量现在也能媲美NeRF。M³选择了3DGS,就是为了在保证高质量的同时,满足实时或准实时的流式重建需求。
论文信息
 发表于 2026-3-22 03:45:25
|
查看: 218|
回复: 0
发表于 2026-3-22 03:45:25
|
查看: 218|
回复: 0
