EROFS(Enhanced Read-Only File System,增强型只读文件系统)是专为不可变场景设计的安全、高性能 Linux 内核文件系统,于 2019 年正式合入 Linux 5.4 LTS 社区主线。当前业界主流 Linux 发行版以及 Alibaba Cloud Linux 4.19、5.10 和 6.6 内核均支持 EROFS 文件系统。
EROFS 文件系统可应用于容器镜像、操作系统镜像、软件包管理及 AI 制品的分发与存储场景,目前已在多个主流场景获得原生支持:
不可变系统:Android 13 已将EROFS列入推荐的系统分区文件系统; AWS Bottlerocket、AWS Attestable AMIs 等发行版已采用EROFS作为根文件系统;Fedora 42+ 已将 Live CD 切为 EROFS 文件系统格式;
容器生态:containerd 2.1 正式支持 EROFS snapshotter;ComposeFS 使用 EROFS 作为其元数据格式;Dragonfly Nydus 的 RAFS v6 使用 EROFS 兼容的元数据格式;
包管理格式:如意玲珑使用 EROFS 文件系统作为 bundle 格式。
沙箱引擎:Kata containers;Containerd Nerdbox;gVisor;OpenEuler Conch沙箱引擎;Tencent Cloud Agent Runtime;
企业级Linux:RHEL 10 官宣支持 EROFS,并将 SquashFS 列入废弃状态。
作为一个精心打造的镜像内核文件系统,EROFS 凭借严格的块对齐设计、精简的元数据格式、原生压缩及内存共享机制,更适合在零信任或者信任域混合部署等场景高效分发、部署数据。
背景:为什么需要专门为镜像设计文件系统?
在容器化(含容器与轻量虚拟化混合)部署场景中,由于宿主机上的容器共享同一 host 内核,这给镜像的分发与部署带来了新的挑战。与物理机及传统虚拟化的完全隔离不同,通用文件系统磁盘格式(如 EXT4、XFS 等)的设计由于冗余的元数据和 journal,天然会带来严重的元数据不一致风险。
为了在绝大多数可信场景中追求高性能,这些通用文件系统在运行时放弃了对关键元数据的全局严格一致性检查(其一致性模型强依赖由用户正常写入生成的元数据和 journal,通过 journal 回放保障元数据强一致性),事实上也无法低开销做到严格一致性检查;规避不一致风险强依赖挂载前的 fsck 文件系统检查工具的检查和修复。
因此,在容器场景下,若未对镜像来源强管控(或镜像管控出现漏洞),使用未经检查的、通用文件系统格式的不可信镜像将严重威胁宿主机集群安全。此外,由于挂载此类文件系统到宿主机已存在风险,针对性它的镜像审计与安全扫描更无从谈起。
为解决上述问题,Docker 镜像(后由 OCI 组织标准化)采用了更简单且符合 POSIX 标准的 TAR 归档格式来构建、分发和部署镜像,通过 AUFS / OverlayFS 读写分离,把可写层完全隔离在可信的通用文件系统中(即用户的本地文件系统,不随远程不可信镜像分发),从而解决了不可信磁盘镜像的安全风险,并通过 Gzip 压缩进一步减小了体积。
采用简单归档格式也是 Docker 镜像能够在 Docker Hub 等公共镜像仓库上实现安全、零信任分发的基础。然而,由于 TAR 和 Gzip 严格意义上均不支持随机访问与解压,容器部署时必须将镜像完整拉取至本地后处理,这严重影响了大规模场景下的容器启动效率。特别是在 AI Agent 时代,面对形态各异的 Agent,除了需采用轻量虚拟化以满足基本强隔离需求外,鉴于用户隐私数据、敏感代码及认证凭证等信息存在被恶意 Agent 程序非法利用风险,针对 Agent 镜像及 Agent 生成制品的内容审计与扫描需求将更为迫切。
由此可见,若要系统化解决容器化部署和 AI Agent 的安全问题,并满足镜像审计与安全扫描等需求,来自虚拟化时代,复用现有可写文件系统格式的传统黑盒设计无法在全链路保障主机和用户隐私安全,有必要对存储格式进行自底向上的完全重构与设计,以提供更安全、可靠的镜像存储方案。
此外,针对压缩和去重等可选特性,镜像文件系统可面向离线生成场景进行针对性设计。相较于在线方案,通过采用优化的压缩机制、内容定义分块(CDC)技术及高性能压缩算法(如 LZ4 算法),不仅能进一步减小镜像体积、降低传输数据量,在云盘或低端存储等 I/O 受限场景下,甚至能实现比未压缩镜像更好的 I/O 性能。
磁盘格式设计原则
基于归档场景,精简的核心磁盘格式
在容器场景中,由于共享同一内核,直接挂载不可信远程镜像时,严重的元数据不一致问题尤其是恶意构造的元数据,可导致系统panic、用户数据丢失、隐私泄漏、数据非法篡改等问题。
典型问题包括但不限于:
- 空间分配与 inode extent 索引不一致(如 inode 已引用的数据块被但被标记为未分配导致空间非法复用;或某个数据块被多次引用,可导致数据篡改或者空间重复释放等,不做全盘扫描无法发现此类元数据不一致问题);
- 高级特性例如 reflink 和反向映射机制导致的元数据不一致(例如 XFS 的 refcountbt 和 rmapbt 元数据);
- 恶意构造的文件系统日志(journal)恢复导致文件系统不一致;
- 小众特性引发的不一致问题。
通用本地文件系统更倾向在本地可信设备上最大化性能,并非以不可信数据导入为其主要设计目标,因此存在大量 by design 的冗余元数据(主要用来优化写操作)。这导致文件系统往往需要在挂载前执行 fsck 进行离线检查,以保证无严重的元数据不一致(尤其是开启文件系统写入时),从而使得不可信镜像数据导入问题复杂化;毕竟,全盘 fsck 会使镜像懒加载变得失去意义。这些更深层次的安全问题,即使换用基于 FUSE 的用户态实现仍旧无法避免。
EROFS 自底向上从源头避免了通用文件系统格式带来的严重元数据不一致问题:一方面,通过设计极简元数据,防止同一语义的元数据在镜像中以不同形式重复出现;另一方面,凭借其严格的不可变设计,在代码实现上避免了经典通用文件系统中读/写逻辑耦合所带来的复杂系统级风险。
在上述这种模型下,所有写操作均通过 OverlayFS(或今后类似机制)copy-up(Copy-on-write)到可信的本地文件系统中,为正常的用户写 workload,既不影响不可变镜像完整性(且支持逐字节强校验和鉴权),也不会给本地文件系统带来任何非预期元数据不一致风险。
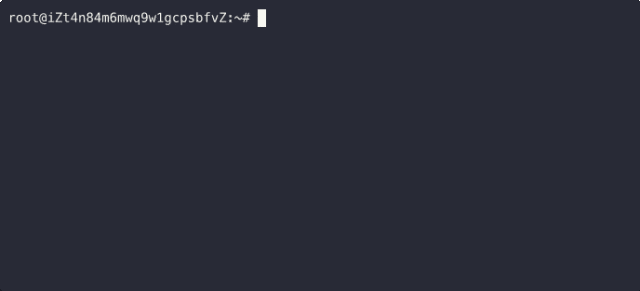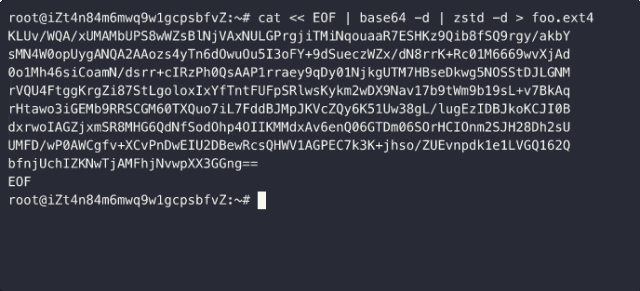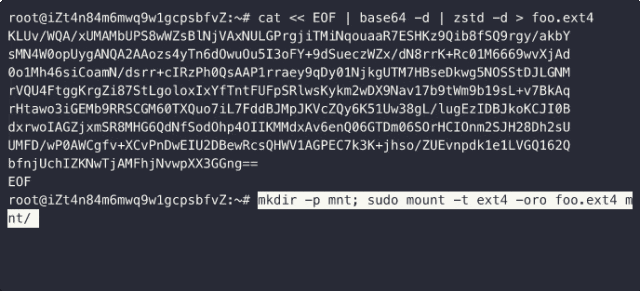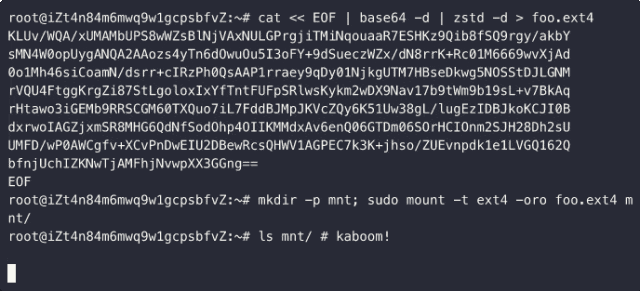
恶意构造的EXT4镜像可导致主机panic
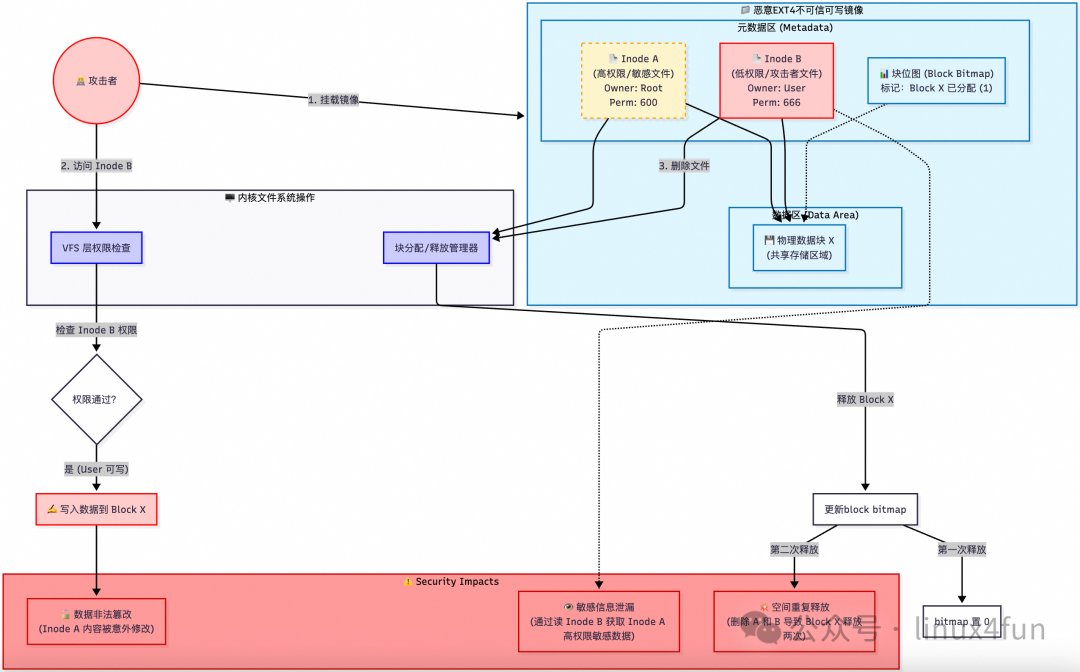
数据块重复引用恶意EXT4不一致可写镜像(违背 Copy-On-Write 原则)会导致:(1) 数据非法篡改【修改低权限文件来篡改高权限文件】;(2) 敏感信息泄漏【查看低权限文件来窥探高权限文件】;(3) 空间重复释放
严格基于固定块大小的文件系统设计
与 ZIP、cpio 等归档格式或 SquashFS 不同,EROFS 文件系统是一个严格基于固定块大小的文件系统(这方面它更像一个通用的文件系统)。它要求所有文件数据必须块地址对齐来消除额外的数据后处理步骤,来适用于所有存储场景:
- 基于块设备的存储需要 LBA 对齐的访问,可 DMA 透明搬运到 page cache;
- 基于内存语义数据需要 PAGE 大小对齐以满足 mmap 映射需求。
原生支持镜像分层和 content-addressable 存储
EROFS 文件系统支持传统细粒度 block diff,也支持类似 OCI 的更灵活 file diff。
file diff 相比 block diff 的优势在于每个增量层完全自包含,不依赖前面层的块数据:例如 GPU 驱动或各类软件包可作为独立的中间层打在各种基础镜像上使用,以实现存储最小化和更简单的构建和部署模式。
更灵活的元数据布局,无需预先估计镜像空间和inode总数,更好的支持增量更新
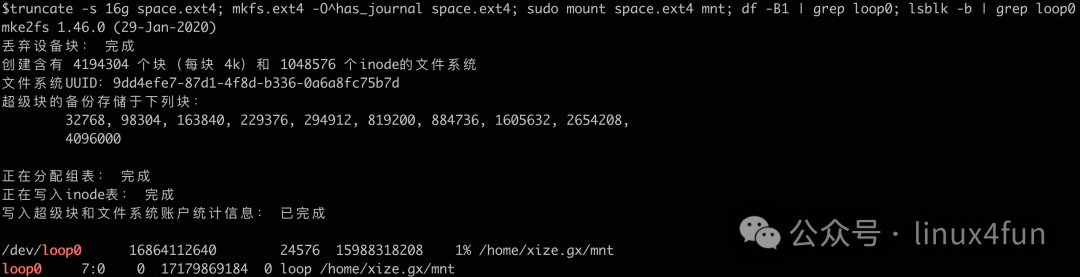
EXT4 文件系统元数据布局完全是静态划分,inode 总数与 mkfs 指定的参数强相关,若 inode 表用完(镜像层中小文件过多),即便还有剩余空间创建文件时也会报错,只能通过 resize2fs 扩充文件系统容量来规避。
例如:在容器镜像场景由于预留的盘大小或者 inode 表不够造成 ENOSPC 问题:EXT4 默认每 16K 空间预留一个 inode,例如 16GiB 的盘制作成 EXT4,会预留 301.1MiB(17179869184 - 16864112640 字节)LBA 空间给 inode 等元数据使用,即使不存在这么多 inode:
分层设计的磁盘格式,支持可选功能扩展
- 支持原生压缩(LZ4、LZMA、Zstandard、DEFLATE 算法等);
- 支持滚动哈希去重(CDC);
- 支持元数据压缩,针对海量小文件存储场景优化 inode 信息和文件属性占用空间。
运行时增强
支持文件系统镜像文件直接挂载
在较新的 Linux 内核(如 Linux 6.12+ 主线内核以及 Alibaba Cloud Linux 5.10 / 6.6 内核版本)中,EROFS 文件系统已支持直接挂载镜像文件的功能。与传统内核文件系统不同,后者通常需要通过 loopback 块设备中转方可挂载镜像文件。
相关 LWN: https://lwn.net/Articles/990750
Linux 内核原生懒加载(fscache -> fanotify)
结合镜像文件直接挂载特性,在较新的 Linux 内核中,EROFS 文件系统支持使用 fanotify 接口实现细粒度的按需访问,不再依赖虚拟块设备(例如 nbd, tcmu 或 ublk)来实现懒加载。
支持主机内镜像间 page cache 内存共享
目前内存成本日益敏感,传统磁盘文件系统(如 EXT4)因无法在多个挂载点间共享 Page Cache,导致多镜像不同挂载点间的相同数据需占用多份宿主机内存。
使用标准 OverlayFS 已支持不同镜像间相同层的 Page Cache 共享,但 EROFS 进一步实现了 host 侧文件粒度的 Page Cache 共享。在不同小版本的容器镜像启动实验中,EROFS 实测可带来 4%~47% 的内存复用收益。
相关 LWN: https://lwn.net/Articles/1055062
支持 FSDAX 内存直通,实现 guest 无 page cache
在虚拟化场景,若使用 virtio-pmem 直通虚机镜像,不同的虚机镜像内相同数据完全无法复用相同 host page cache:
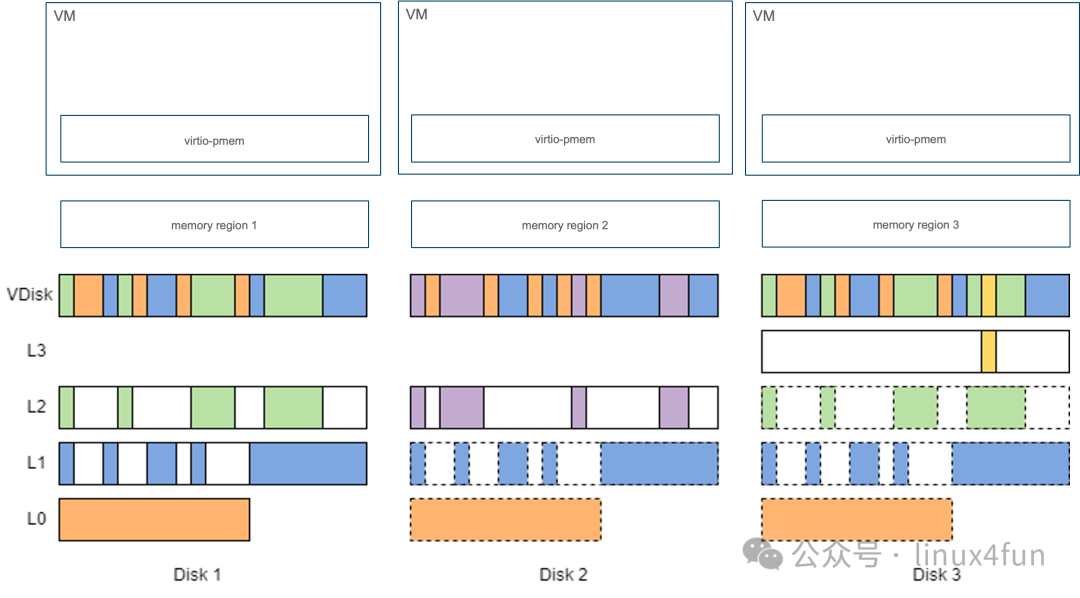
例如上图中的三个 Vdisk,虽然 L0、L1 在三个 Vdisk 中均有使用,L2 在 Disk 1 和 3 中复用,但由于三个 Vdisk 互相独立,无法做到镜像间相同层内存在 host 侧复用。
EROFS 文件系统结合 virtio-pmem 可实现更细粒度容器镜像层粒度的内存共享:
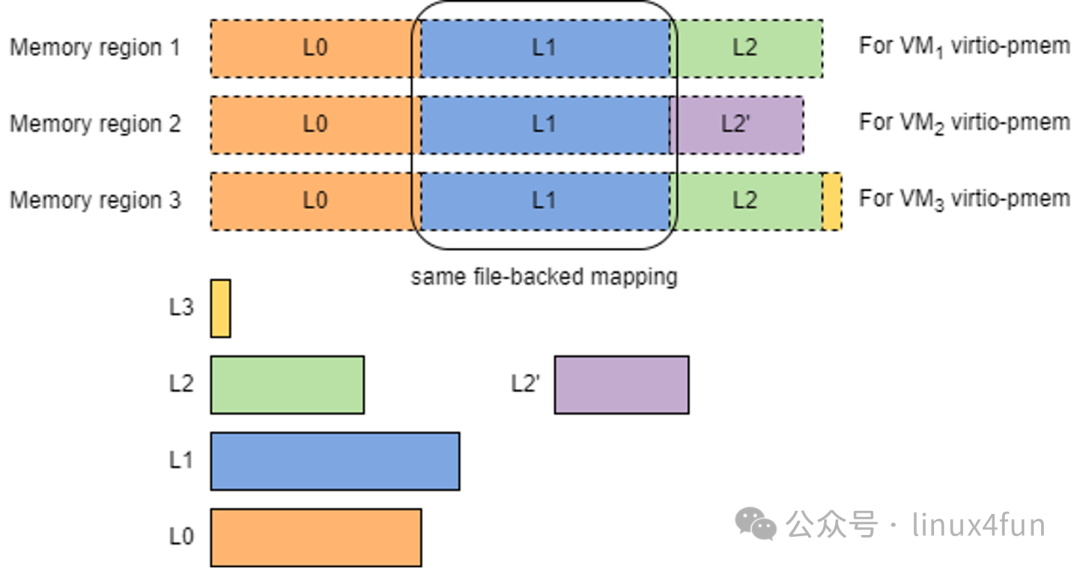
通过 EROFS 文件系统内置的原生分层机制,L0、L1、L2 层的 page cache 在 host 侧仅有一份,这样就可以在 host 侧做到更细粒度的内存复用;相比传统的磁盘快照基于块的无序映射,这种基于层 host <-> virtio-pmem 扁平映射开销更低,且每个 EROFS 镜像层在 host 侧由于是连续的,相比纯磁盘快照的方式,EROFS DAX 多层多 VM 共享可在 host 侧和 guest 侧均可直接组装成 THP 大页进一步降低 TLB 和数据访问开销。本方案的优势在高密部署的 AI Agent 时代会更加凸显。
相关链接:
典型应用场景
OCI 容器镜像本地转换
自 Containerd 2.1 起,EROFS snapshotter 支持 OCI 镜像完整透明转换为 EROFS 镜像格式(非仅索引构建),本方案可天然支持并发转换,提升容器启动速度,减少存储空间占用,并有效保障数据完整性:
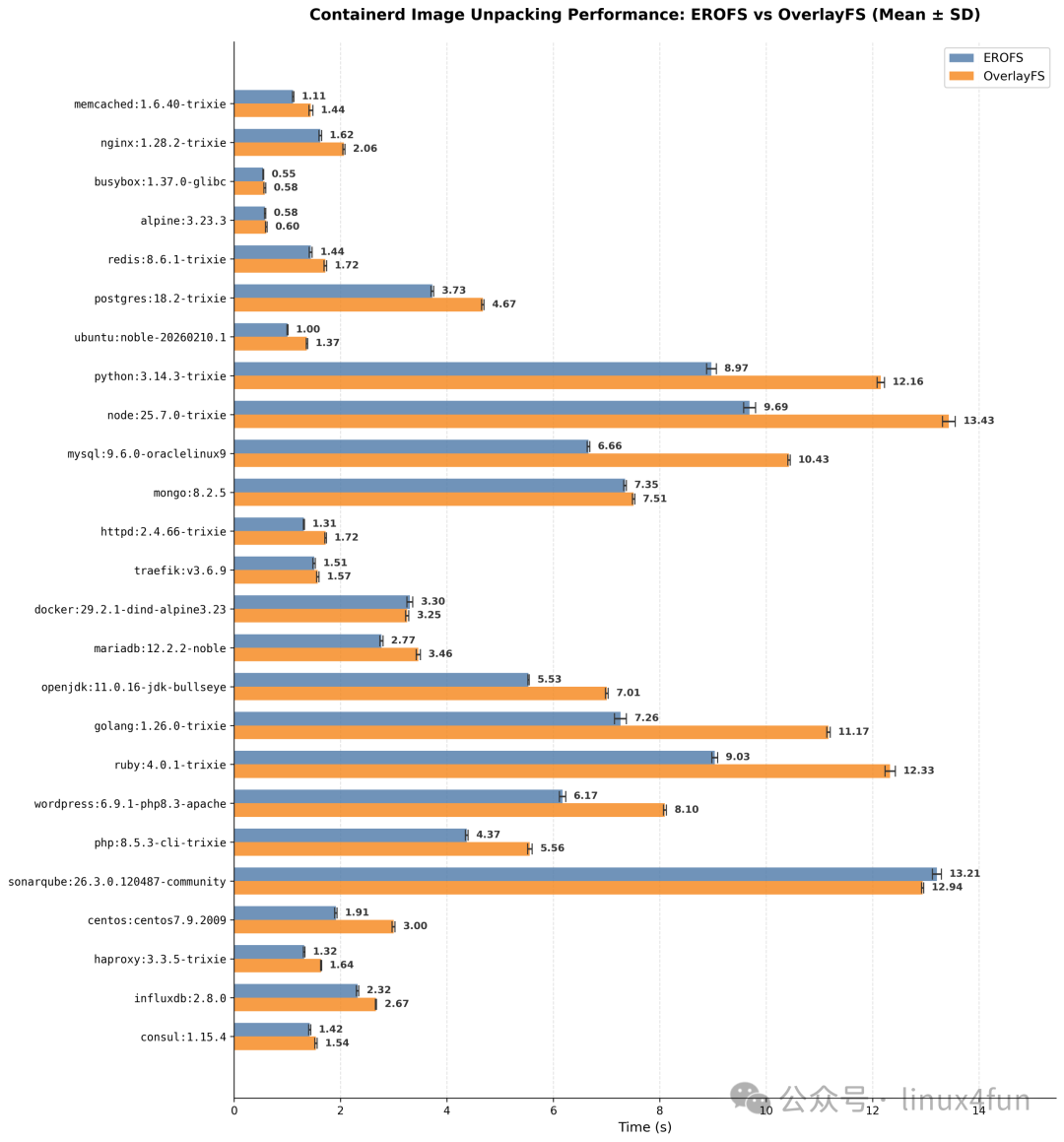
如下为 EROFS 对比 OverlayFS snapshotter 的镜像解包性能对比(镜像源为本地镜像仓库),首先是 Docker Hub Top25 镜像的对比:
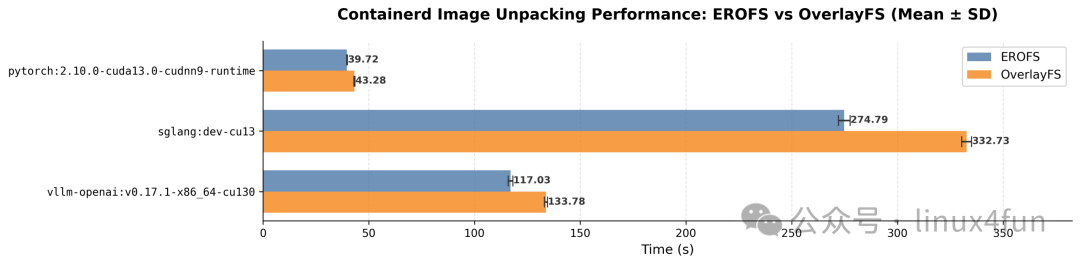
然后是 LLM 容器镜像的解包性能对比:
生成的 EROFS 镜像层支持通过 fsync(2) 实现数据持久化,确保转换过程中产生的 Dirty Page Cache 不会因掉电或系统崩溃而丢失。相较于 OverlayFS Snapshotter 在解压镜像层时必须调用 syncfs(2) 以同步整个目录树相比,本方案开销更小,运行更为轻量。
同时,这些镜像层还支持在 runC 容器和 Kata 等轻量虚拟化容器间高效复用。针对轻量虚拟化场景,它支持通过 virtio-blk 或 virtio-pmem 直接直通镜像层,既解决了当前 virtio-fs 直通(元)数据性能和 host 文件描述符资源占用等问题,又提升了系统整体稳定性。
更多信息见: https://github.com/containerd/containerd/blob/v2.3.0-beta.0/docs/snapshotters/erofs.md
EROFS 原生容器镜像
即将发布的 Containerd 2.3 版本支持 EROFS 格式的容器镜像拉取并运行,进一步缩短容器启动时间。
不可变系统根文件系统
- Container OS:如 AWS Bottlerocket 已全部切换至 EROFS 文件系统提升 Container OS 启动性能,并减少 RootFS 体积;
| Platform |
Baseline (EXT4) |
EROFS |
Improvement |
| x86 (m7i) |
11.11s |
6.72s |
-39.5% (~4.4s faster) |
| ARM (m7g) |
9.73s |
6.00s |
-38.3% (~3.7s faster) |
| NVIDIA (g4dn) |
23.56s |
17.03s |
-27.7% (~6.5s faster) |
见如下 issue: https://github.com/bottlerocket-os/bottlerocket/issues/4727
数据包/索引格式
由于 3FS 等分布式文件系统在访问海量文件时存在瓶颈,可通过包/索引格式(例如幻方量化公开的 FFRecord 格式)将元数据和海量小文件数据 I/O 变为大 I/O,提高运行时性能,并提高缓存效率。
SS/S3 等对象存储块语义直通
适配 AI 模型训练大规模数据集和对象存储直通等需求。不依赖 FUSE;支持元数据访问时动态按需构建。
随着不可变数据分发需求的日益增长,EROFS 凭借其在安全、性能和内存效率上的独特优势,正逐步成为容器、操作系统乃至 AI 存储场景下的关键技术选择。想了解更多关于 Linux 内核、容器技术和其他前沿技术讨论,欢迎访问云栈社区。
 发表于 2026-3-23 04:14:59
|
查看: 169|
回复: 0
发表于 2026-3-23 04:14:59
|
查看: 169|
回复: 0
