上周,月之暗面CEO杨植麟在GTC 2026现场发表了主题分享,系统阐述了Kimi在过去构建更强开源模型方面的核心经验与策略。
杨植麟在开场引用了黄仁勋在CES演讲中的一张图表,指出开源模型与闭源模型的性能差距正快速收敛,让“智能民主化”从口号变成现实路径。

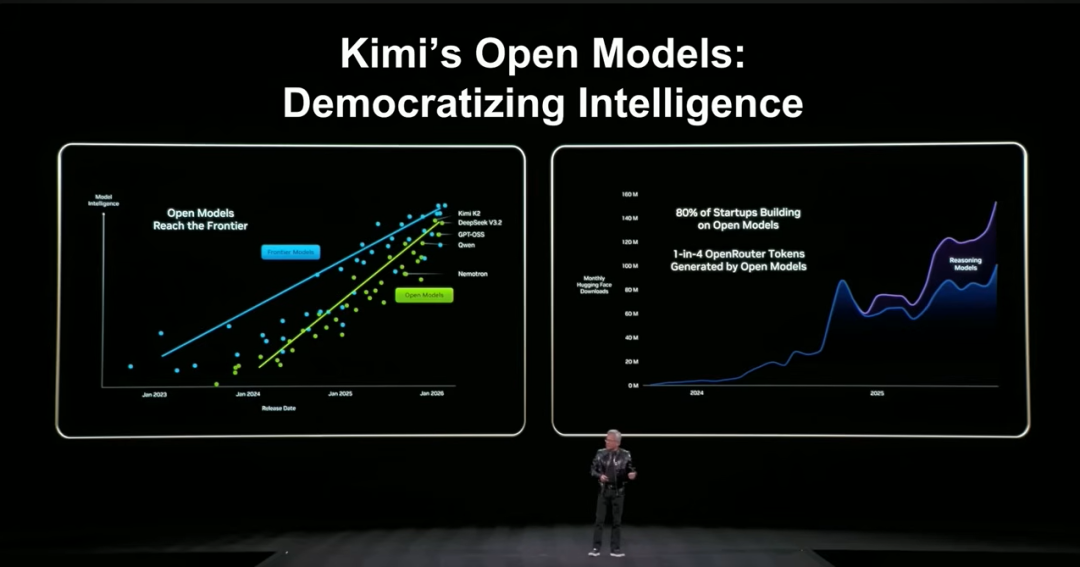
但紧接着他提出了一个关键观点:开源模型不能只是“开源”,它还必须足够优秀。 整场分享的核心逻辑便在于此——开源模型要赢得未来,就必须在能力上变得足够强。
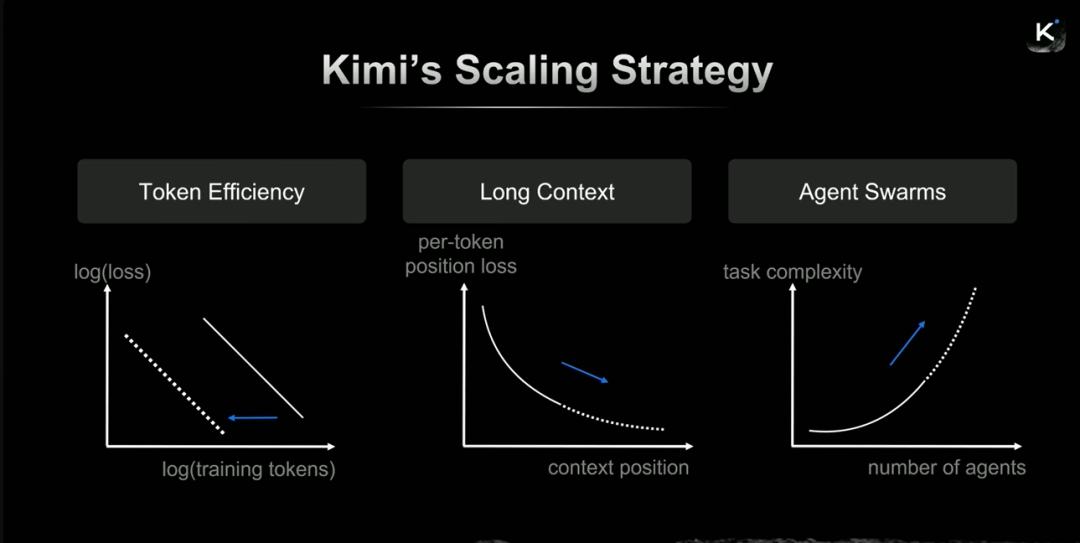
为此,Kimi提出了一个“三位一体”的“多维扩展”方法,覆盖了模型能力提升的三个关键维度:
- Token效率:决定智能的上限。
- 长上下文:重构任务边界,决定模型能做多复杂的事。
- 智能体集群:让模型具备“系统能力”,从个体智能升级为组织智能。
Token效率:用优化器“创造数据”
几乎所有重要的AI进展都离不开规模扩展,其中最经典的就是Scaling Law:随着训练token数量、模型参数和计算量的增加,模型的损失会持续下降。但Kimi更关注的是如何提升Token效率,即用更少的训练数据达到更低的损失。
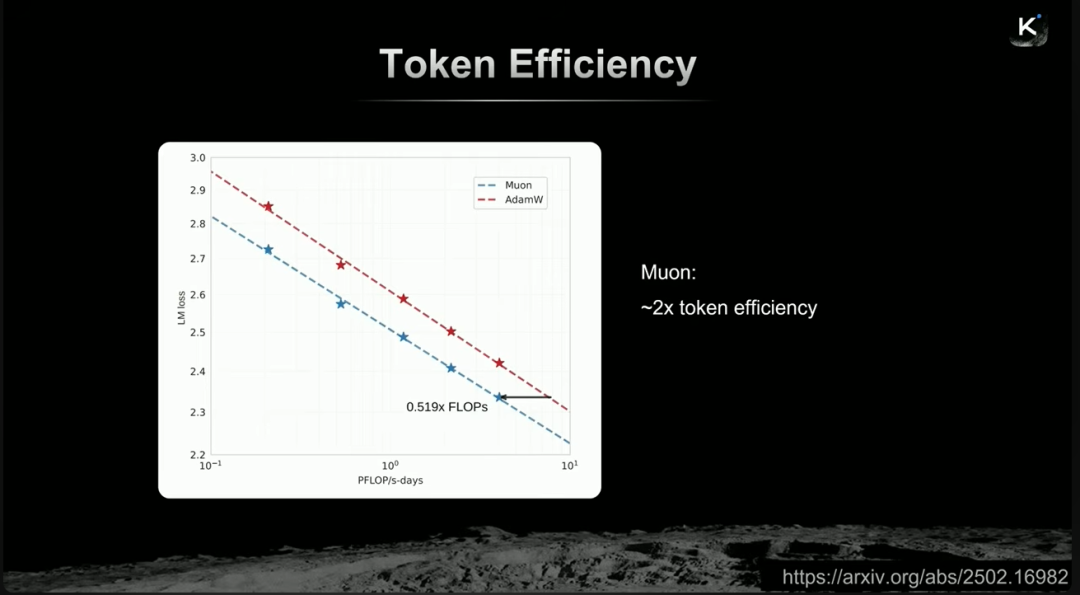
杨植麟强调,Token效率不只是节省算力的问题,它实质上决定了智能的上限。在高质量数据总量有限的现实下,提升Token效率意味着能逼近更高的智能边界。例如,若有50万亿高质量token,通过将Token效率提升2倍,等效上就相当于拥有了100万亿token的效果。
为此,Kimi重点投入了Muon优化器的研究。这是一个二阶优化器,通过对梯度更新进行变换,使各分量相互正交,从而带来约2倍的Token效率提升。

Kimi团队首次证明了此类优化器可以扩展至大规模Transformer模型训练,其工程实现包含两个关键:引入decay以适应更大模型,以及保持与Adam相似的RMS更新。同时,他们还设计了分布式算法以降低内存开销。
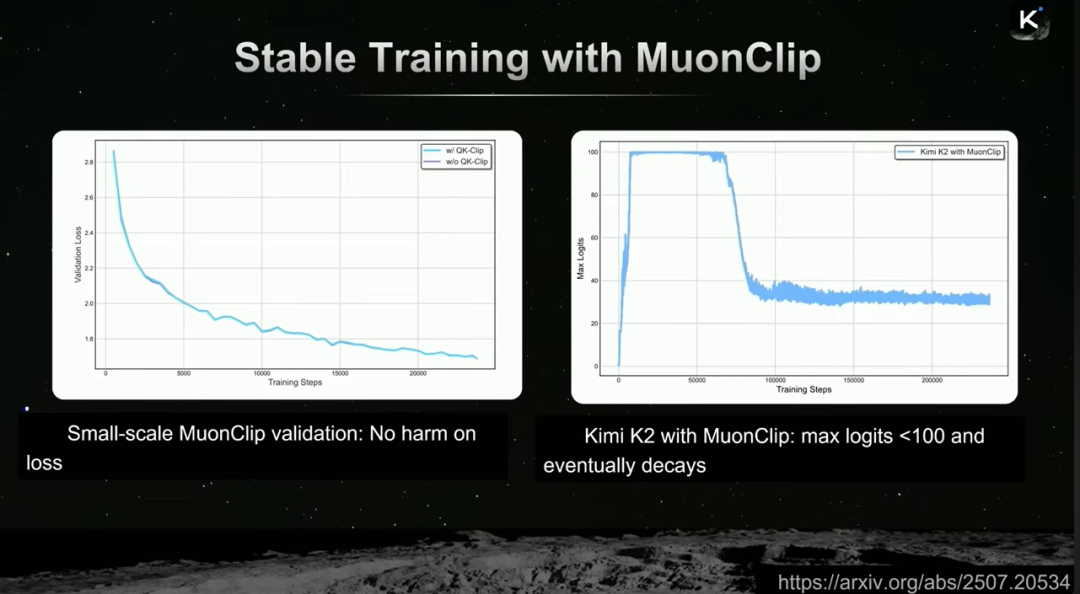
然而,当模型规模扩展到万亿参数时,训练出现了不稳定性:logits最大值迅速爆炸,超过1000,导致训练发散。
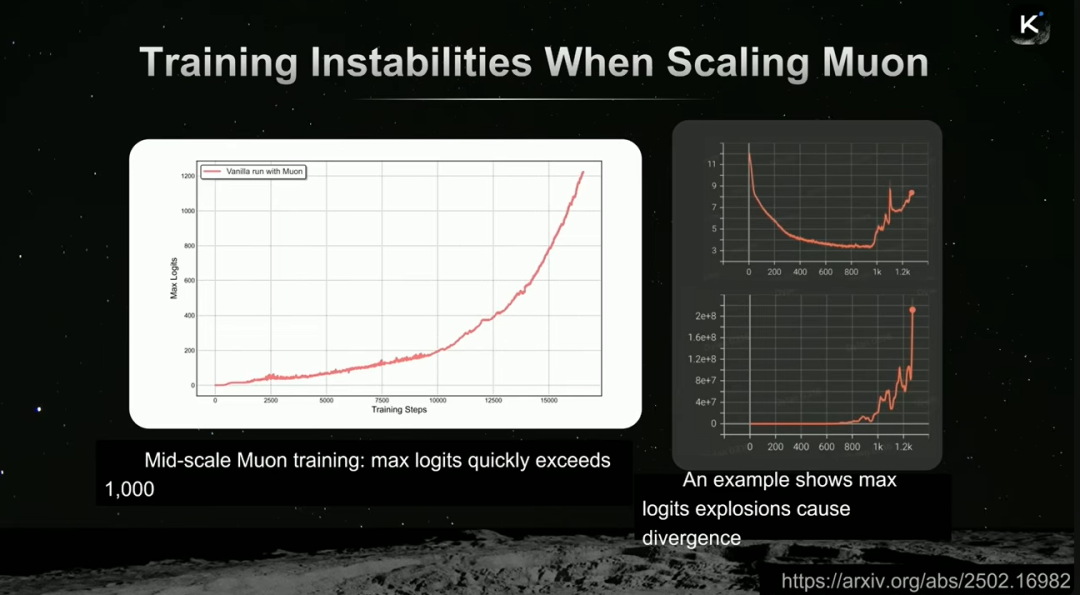
为解决此问题,Kimi引入了QK-Clip技术。其核心思路是,在前向传播时计算每个注意力头的最大logit值,并据此动态缩放query和key的投影权重,将其限制在合理范围内,从而避免数值爆炸。

实验表明,QK-Clip技术能有效稳定训练,将最大logits值稳定截断在100左右,且不影响损失下降过程,最终成功将K2模型扩展至万亿参数规模。
长上下文:Kimi Linear架构的诞生
第二个扩展维度是上下文长度。长上下文能力对于处理复杂任务至关重要,尤其是在智能体时代,任务往往需要模型能够理解并处理极其冗长的信息。
杨植麟引用了Kaplan定律论文中的一个“隐藏宝藏”图表,解释了Transformer相对于LSTM的优势根源:随着上下文位置增加,Transformer的损失持续下降,而LSTM很快达到平台期。这表明Transformer天生更擅长利用长程依赖。
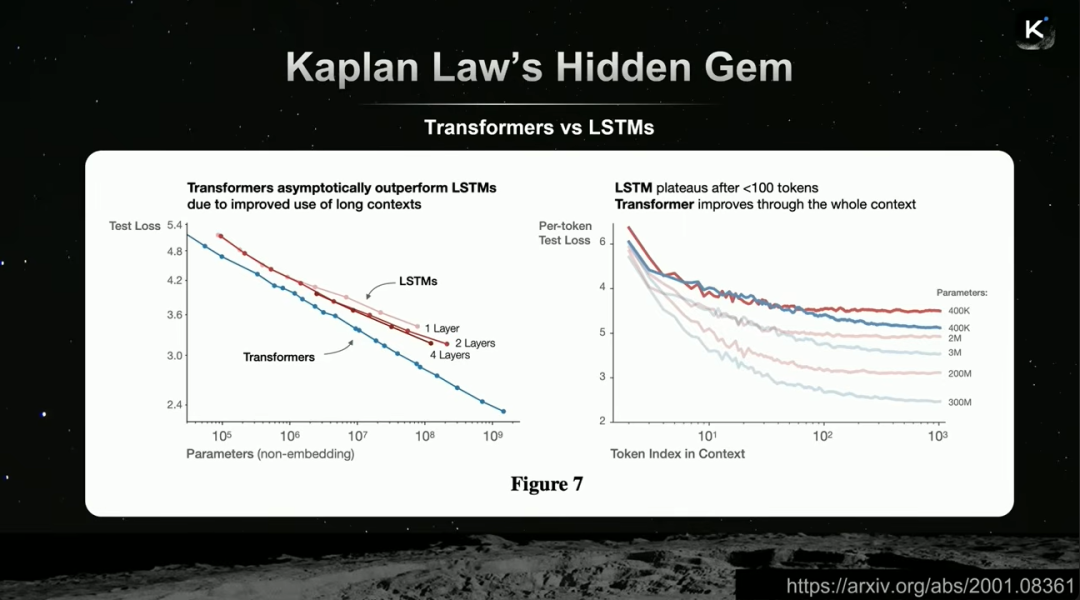
基于此,Kimi的目标是设计一种既能高效扩展上下文长度,又能在长序列中保持低损失的新架构,于是提出了 Kimi Linear。
Kimi Linear包含一种新的线性注意力变体Kimi Delta Attention,它在原有delta rule基础上增强了递归记忆管理。其核心创新在于将记忆衰减因子从标量升级为对角矩阵,使得模型的不同通道可以拥有独立的衰减速率,从而实现对信息的细粒度、选择性保留与遗忘,大幅提升了表达能力。

为了适配GPU并行计算,团队通过严格的数学变换重写了计算过程,使其支持分块并行。Kimi Linear采用混合设计(如3:1的线性注意力与全注意力比例),在多项基准测试中,无论是短上下文任务还是长达百万token的评估,均优于基线方法,是首个在所有场景下都能超越全注意力的架构。

Agent Swarm:从单一智能到群体智能
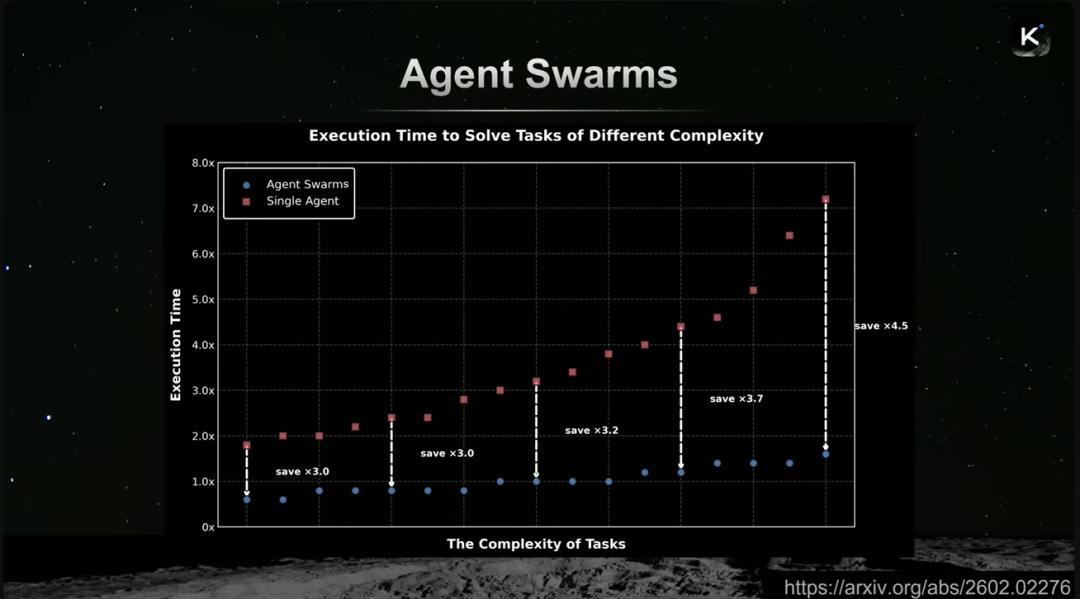
第三个扩展维度是智能体的数量。Kimi提出Agent Swarm范式,通过多个智能体并行协作来攻克复杂任务。
在该系统中,一个“指挥者”智能体负责动态创建专业化的子智能体(如AI研究员、物理研究员、事实核查员),并将复杂任务分解为可并行执行的子任务,最后聚合结果。

这种范式可以类比为一个组织,其优势在于能显著降低复杂任务的执行时间。随着任务复杂度提升,单智能体的执行时间急剧增加,而智能体集群的效率优势则越发明显。
为了有效训练Agent Swarm,Kimi设计了新的目标函数,在传统的结果奖励之外,引入了两个关键奖励:
- 实例化奖励:鼓励生成子智能体,避免模型退化为单智能体执行。
- 完成奖励:鼓励子任务被有效完成,防止模型生成大量“伪任务”作弊。

Kimi K2.5:实践与涌现能力
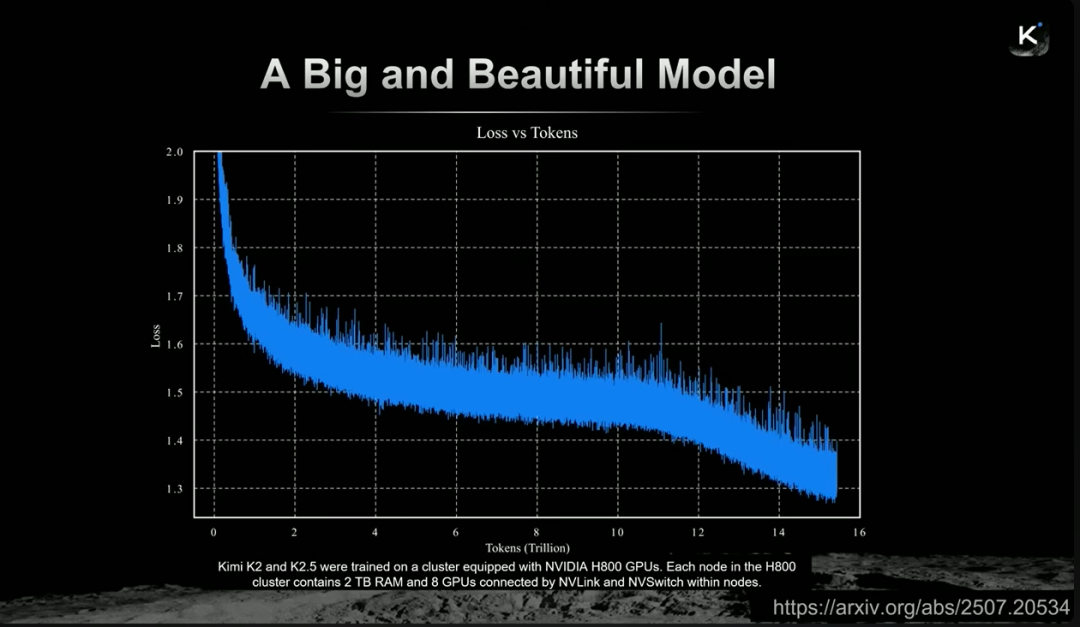
基于上述三大扩展策略,Kimi发布了新模型K2.5。其训练过程超过15万亿token,曲线平滑稳定,这为后续微调出强大能力奠定了坚实基础。
K2.5的一个关键创新是实现了原生视觉-文本联合预训练。不同于常见的“后期融合”方案,K2.5从训练伊始就将视觉和文本token融合在一起。
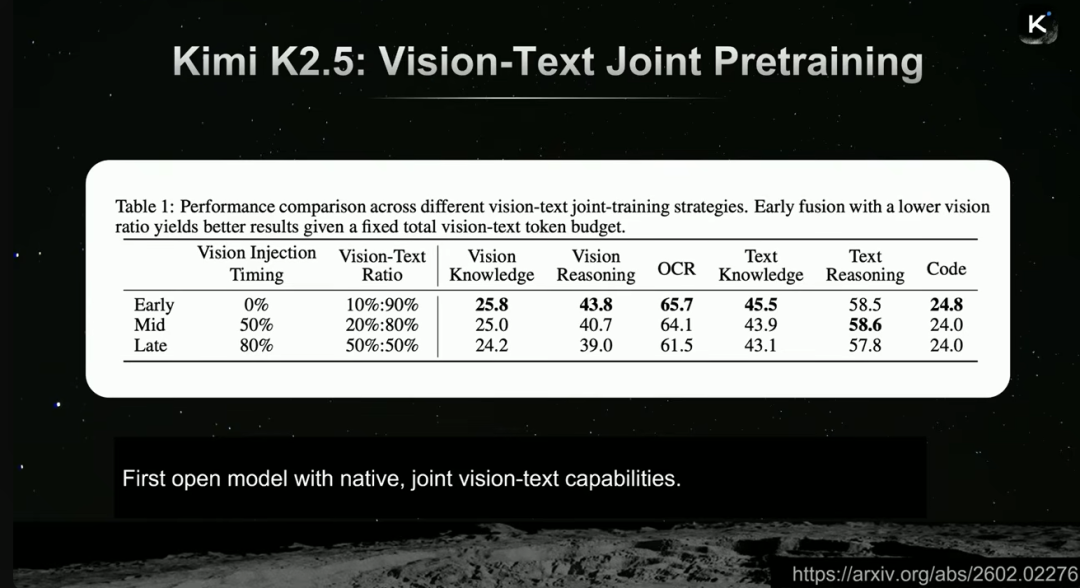
这种方式带来了两个反直觉的发现:
- 视觉提升文本:仅使用视觉任务进行强化学习,竟然能提升模型在文本推理任务上的表现。
- 文本提升视觉:在几乎没有视觉监督微调数据的情况下,仅依靠强大的文本基础模型和联合对齐的表示空间,模型就能在视觉任务上达到接近SOTA的水平。

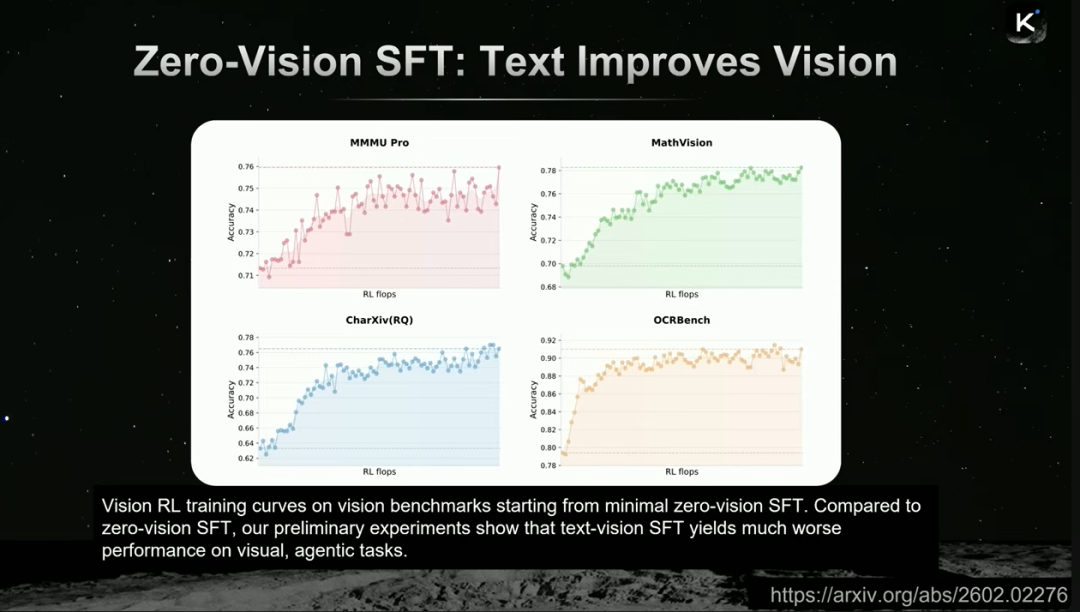
这表明,多模态能力的关键可能不在于数据量,而在于是否将不同模态对齐到统一的表示空间。K2.5展现出的“视频生成网页代码”等涌现能力,正是这种统一表示的产物。
下一代架构预告:Attention Residuals
演讲最后,杨植麟预告了下一代模型架构方向——Attention Residuals。这一工作的灵感来源于Ilya Sutskever的观点:残差连接可视为LSTM在深度维度上的“旋转”。

既然加法形式的残差连接有效,那么能否用注意力机制来替代?Attention Residuals的核心思想是:让当前层可以“关注”所有历史层的输出,而不仅仅是上一层的输出,相当于将注意力机制从时间维度扩展到了深度维度。
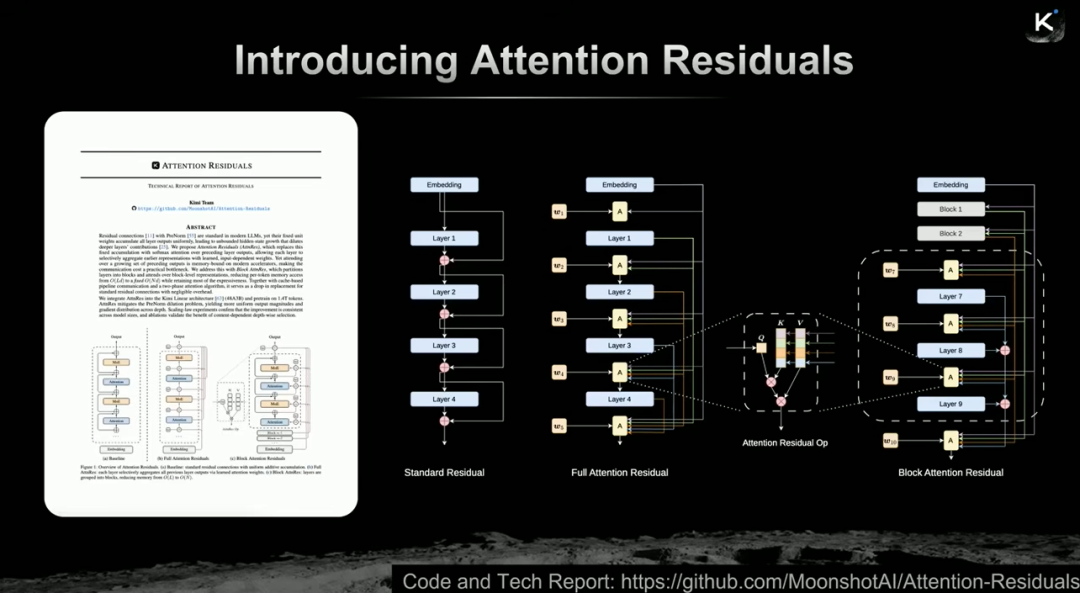
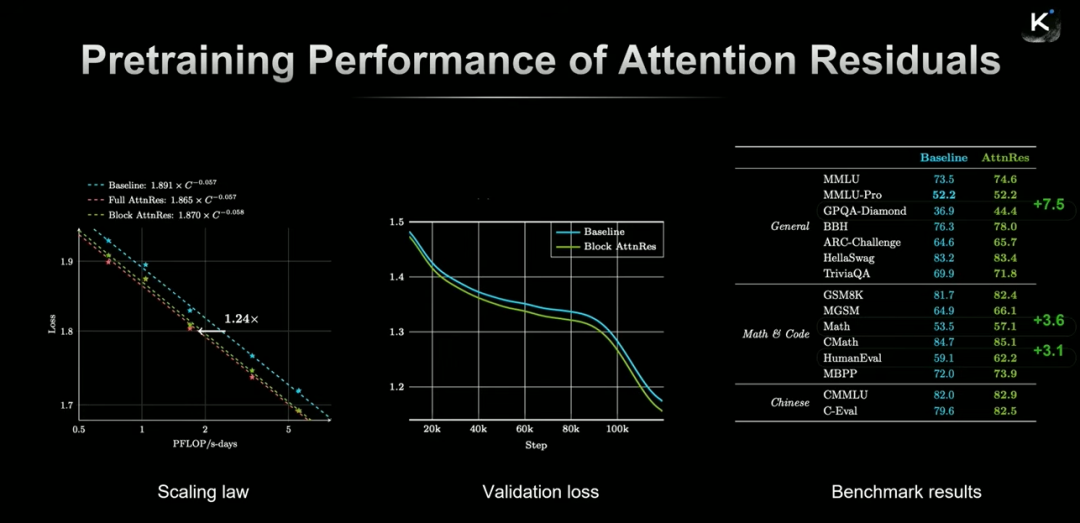
为了平衡性能与计算开销,Kimi提出了工程优化版本Block Attention Residual,将网络分块,在块内使用标准残差连接,在块间使用注意力残差。
初步实验结果显示,该架构能将Token效率提升约24%,并在代码、数学等高难度任务上取得明显进步。
AI研究范式转变:从提出想法到系统验证
杨植麟指出,当前AI研究正经历一个深刻的范式转变:从“提出想法”转向“系统验证”。
十年前,受限于实验条件,许多想法难以被充分验证。而现在,Scaling Law提供了可预测的路径,强大的算力支持大规模实验,完善的评测基准让结果可比较。这促使许多“老技术”被重新挖掘并获得新突破。
例如,Adam优化器(2014年)正在被MuonClip这样的新优化器超越;注意力机制(约8年前)衍生出Kimi Linear这样的高效变体;残差连接(约10年前)则被扩展为Attention Residuals。

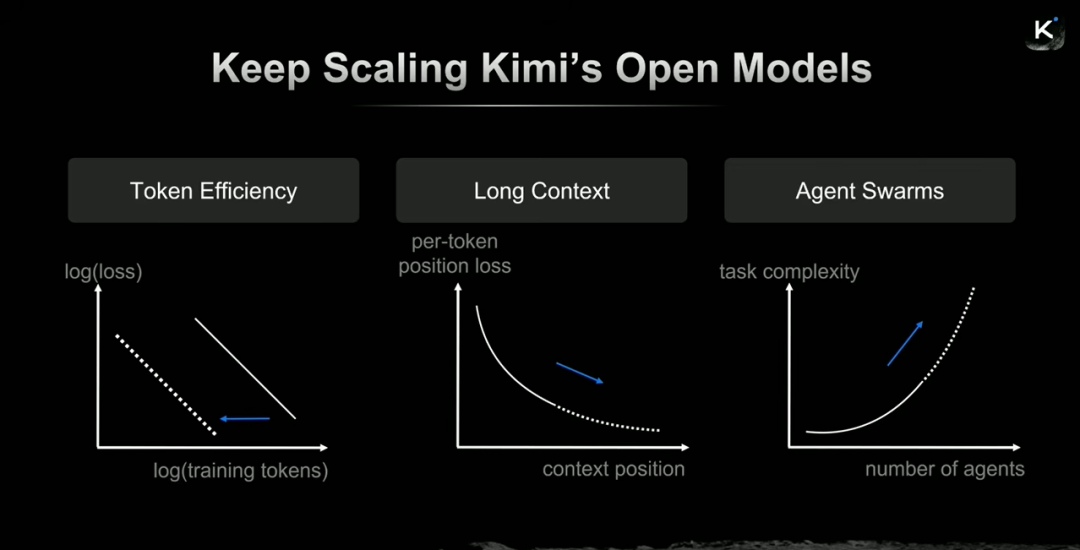
杨植麟总结道,Kimi将继续在Token效率、长上下文和Agent Swarm等维度推进模型扩展,并相信未来会出现新的扩展维度。他重申了对开源和智能民主化的承诺,期待与整个社区共同推动智能边界向前发展。
这场演讲清晰地展示了Kimi在Scaling Law指导下,通过系统性工程与创新,重新发明模型“基础设施”的实践路径,也为整个AI开源社区提供了宝贵的技术洞见与方向指引。关于大模型架构演进与训练的更多深度讨论,欢迎在云栈社区与广大开发者继续交流。
 发表于 2026-3-24 02:17:20
|
查看: 148|
回复: 0
发表于 2026-3-24 02:17:20
|
查看: 148|
回复: 0
