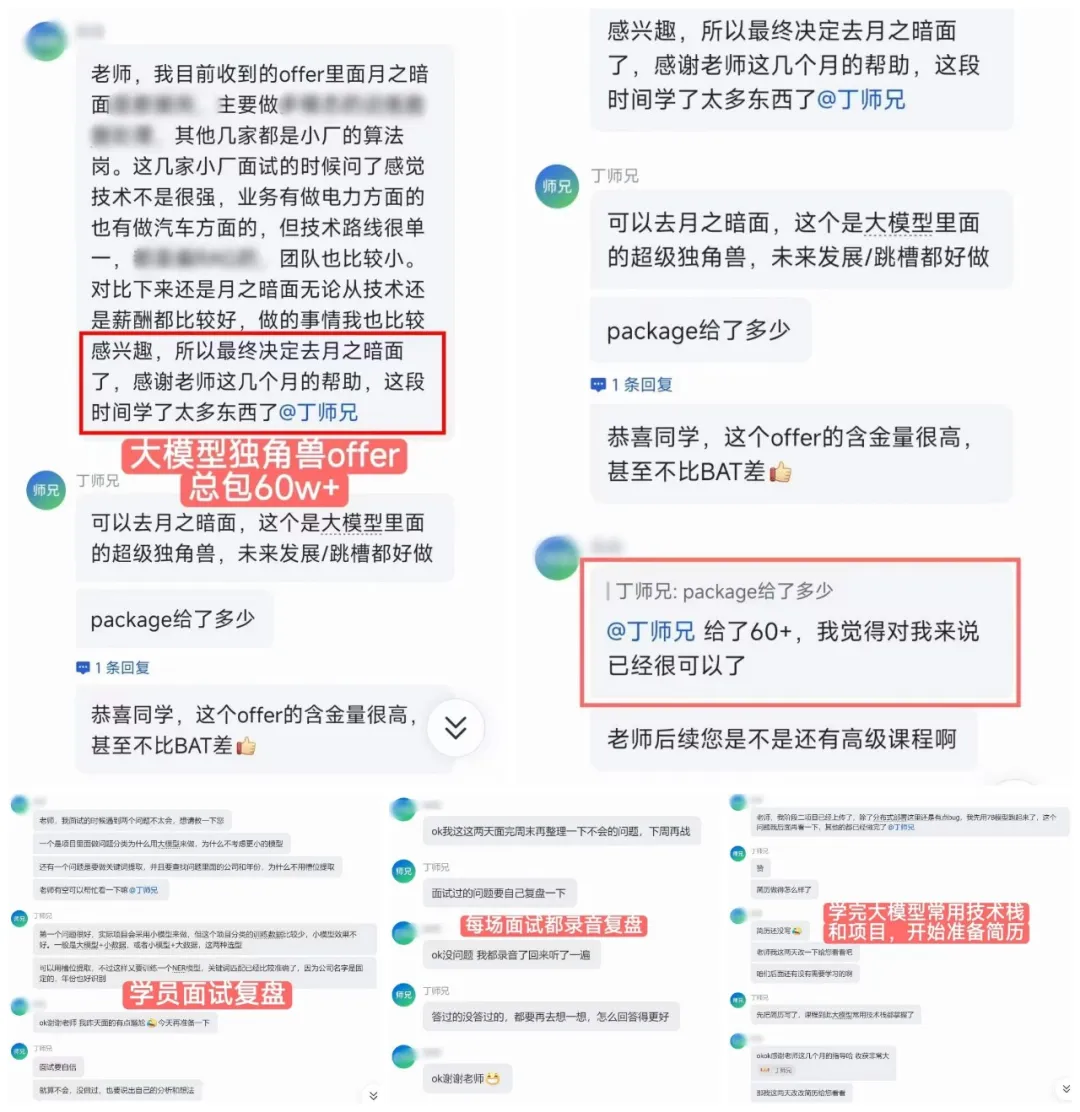
恭喜学员拿下大模型独角兽月之暗面offer,总包60w+。从最开始面试被卡,回来做面试复盘,每场面试都录音回听,补齐短板。训练营这边,我布置的实战作业一个都没有落下,项目手动复现吃透。上岸靠的不是运气,而是方法+强度,逼你在实战中,一步步把能力练出来!
下面分享一下我个人参加腾讯AI应用开发二面的经验,依旧忘了录音,只能记录下有印象的问题,希望能给大家一些参考。
Q:项目中说到了从 Claude ADK 迁移到 Gemini API,为什么?
Q:如果有个无限长上下文的模型,是否可以把所有信息都放到上下文?
A: 不能,信息可能会有噪音,影响模型判断。
Q:场景:一个有很多内容的需求文档,是否可以把整个文档放到上下文中,让模型直接实现?
A: 内容太多,模型的注意力可能兼顾不了,需要分模块输入。(猜的)
Q:如果分模块输入,Agent 是否会对整个需求没有认知,导致做出来的成果不符合预期?
A: 可以参考人的协作,每个 Agent 工作在独立的 worktree 上,定义一个约束,每个模块期望的效果、接口等。
Q:用过哪些 Code Agent?
A: Cursor,Claude 等。
Q:你觉得 Claude Code 和 Cursor 分别适合什么样的任务?
A: 我觉得没啥区别,效果都可以,主要用 Cursor 因为便宜。
Q:Cursor 用过什么 skill 觉得好用?
A: Superpowers,有 brainstorming,git 等。前者可以帮助理清需求,后者是教 git 的最佳实践。可以每个任务对应一个 worktree,代码追溯更方便,适合多 Agent 协作。
补充:(skill creator,这个没说,但是也挺好用的,需要干重复的任务可以直接让 Cursor 写个 skill)
Q:了解过 spec-driving 的 Code Agent 吗?
A: 用过 kilo 的 spec 模式,觉得机制有点重,需求文档+实现文档,不如 brainstorm + plan mode。
Q:了解上下文压缩机制吗?
A: 看过 Gemini CLI 的源码,它的实现是保留最近 30% 对话,压缩另外 70% 的内容,用 LLM 生成结构化摘要。
Q:为什么压缩前 70%?最开始的几轮对话明确需求不是很重要吗?
A: 生产摘要的提示词明确要求模型填写需求内容。
Q:你觉得以后的软件工程会变成什么样?
A: 我觉得以后不用人不用写代码,而是给 Agent 说明需求,并校验 Agent 生成的代码。
补充:这个问题我觉得答得不太好,软件工程不只是写代码,也包含测试、部署、维护等操作。
补充:现在想想可以是 AI 驱动的软件工程,代码 AI 写,测试 AI 自动测,部署维护也是 AI 来做。
Q:玩过 OpenClaw 吗?了解其的记忆机制吗?
A: 了解,主要有两阶段:memory_search,用 RAG 检索 memory 文件,返回 topN 相关的内容以及文件路径以及行数。Agent 可以选择调用 memory_get,一个类似 read 的 tool 读取 memory 文件的内容。
Q:如果检索返回了很多相关的内容,如何选择最相关的?
A: 向量相似度比较,选择最相近的 n 个。
Q:了解 embedding 吗?
A: 好像是语义检索计算相似度的模型,这个不太了解。
Q:用大模型来判断哪些内容最相关,是否可行?
A: 挺有意思的。
Q:实际上没人这么做,你觉得为什么?
A: 返回的内容可能很多,超过模型最大上下文,模型判断不好。
补充:(可以加上速度、成本的因素)。
Q:OpenClaw 有个 pi-coding-agent,与你的项目有什么区别?
A: 不太了解 pi。
Q:对候选人的期望:
A: 代码能力不要求,因为 100% AI 生成代码。
A: 了解底层原理,需要有较强的学习能力,对前沿的产品能快速复现。
Q:反问环节:
Q:你觉得 Agent 开发最重要的是什么?
A: 评测机制。
补充:无手撕。
这次面试体感上感觉还可以,但是仔细复盘发现有不少问题,主要是对 RAG 的机制不熟,rerank 不知道,还有对大模型的底层原理了解不够深入。
这次面的问题都比较开放,所以我把我的回答也写了上去,各位如果有不同意见,欢迎一起讨论。这份真实的面经希望能帮助到正在准备类似岗位的朋友。也欢迎来我们云栈社区交流更多的技术问题和面试心得。
作者:尘土飞扬
来源:https://zhuanlan.zhihu.com/p/2019474229989516552
 发表于 2026-3-24 03:19:20
|
查看: 219|
回复: 0
发表于 2026-3-24 03:19:20
|
查看: 219|
回复: 0
