PPO(Proximal Policy Optimization)一直是 RLHF 训练的主流算法,但其对 Critic 网络的依赖和高昂的内存开销,使得训练大规模语言模型(LLM)的成本极高。GRPO(Group Relative Policy Optimization)由 DeepSeek 团队在 DeepSeek-R1 训练中提出,它通过完全移除 Critic 网络、使用组内相对优势替代值函数估计,在显著降低内存和计算开销的同时,依然保持了出色的训练效果。
理解 PPO 与 GRPO 的本质区别及各自的适用场景,对于设计高效、稳定的大模型强化学习训练系统至关重要。
01 PPO 的核心机制与代价
(1)PPO 算法框架
PPO 通过一个精巧的目标函数,在鼓励策略改进和防止其偏离旧策略过远之间寻求平衡:
![PPO目标函数公式:L_PPO = E[min(r_t(θ)A_t, clip(r_t(θ), 1-ε, 1+ε)A_t)]](https://static1.yunpan.plus/attachment/adc3200f3ccfdd31.webp)
其中 r_t(θ) = π_θ(a_t|s_t)/π_θ_old(a_t|s_t) 是新旧策略的概率比,A_t 是优势估计,ε(通常设为0.2)用于控制更新步长。
(2)Critic 网络的作用与开销
PPO 算法需要一个与策略模型规模相当的 Critic(价值函数网络) 来估计优势函数 A_t,其计算通常依赖于广义优势估计(GAE):
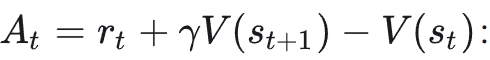
正是这个 Critic 网络,带来了显著的资源与复杂性开销:
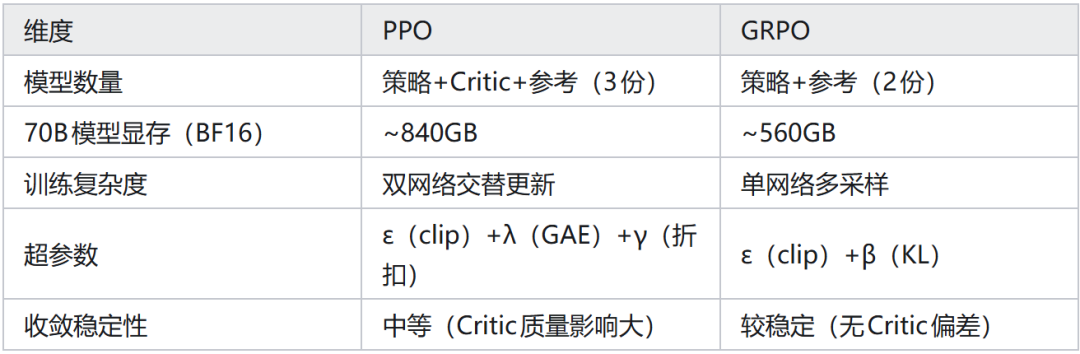
- 内存开销翻倍:一个70B参数的策略模型加上一个70B参数的 Critic 模型,总参数量达到140B。以 BF16 精度计算,训练时显存需求高达约 560GB。
- 训练复杂度增加:策略网络和 Critic 网络需要交替更新,而 Critic 的训练目标(最小化时序差分误差)有时会与策略网络的改善目标产生矛盾。
- 方差-偏差权衡难题:GAE 虽然有助于降低估计方差,但也引入了自举偏差(bootstrapping bias),在处理长序列任务时,这种偏差尤为明显。
(3)PPO 在 LLM 训练中的实际挑战
当 PPO 应用于语言模型时,还面临一些特有的问题:
- 奖励归因困难:在文本生成任务中,“状态”是已生成的序列,“动作”是下一个 token。Critic 需要估计每个中间 token 的“价值”,但许多功能性 token(如连接词、标点)本身并无明确的语义价值,导致 Critic 难以学习到有效的信号。
- 训练不稳定:InstructGPT 的实践报告指出,PPO 训练在大约500步后容易出现奖励退化现象,这通常是因为 Critic 出现高估,进而导致策略过于激进地偏离参考模型。
02 GRPO 的设计理念与优势
(1)无 Critic 的组内相对优势
GRPO 的核心创新在于完全摒弃了 Critic 网络。它的思路很直观:与其训练一个复杂的网络来估计每个动作的绝对价值,不如直接比较同一问题的多个回答,使用它们在组内的相对表现作为优势信号。
其优势 A_i 的计算公式为:
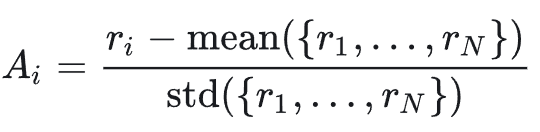
具体训练流程可分为四步:

这本质上是将 REINFORCE 算法与一个基线函数(即组内奖励的均值) 相结合,完全基于蒙特卡洛回报,避免了自举带来的偏差。
(2)GRPO 的资源与效率优势
移除 Critic 带来了立竿见影的好处。我们可以通过一个直观的对比表格来看:
GRPO 在 开源实战 项目 DeepSeek-R1-Zero(一种无需 SFT 预热、纯靠 RL 训练的模型)中展现了令人惊讶的效果:模型自发地涌现出长链思维和反思行为,而这在传统的 PPO 训练框架中是极难实现的。
(3)REINFORCE++ 的改进
在 GRPO 的基础上,REINFORCE++ 算法进行了几点重要优化:
- Token-level KL 惩罚:逐 token 计算与参考模型的 KL 散度,提供比序列级约束更精细的控制。
- 小批次多轮更新:对同一批采样数据进行多轮梯度更新,提高了数据利用率。
- 优势归一化:在 mini-batch 内部对优势进行归一化,有助于稳定梯度量级。
实验表明,这些改进使得 REINFORCE++ 在数学推理任务上的准确率比标准 GRPO 高出约 1-2%。
03 适用场景对比与选型
那么,在实际项目中,我们究竟该如何选择呢?
(1)GRPO 更适用的场景
- 结果清晰可验证的任务:例如数学推理(答案对错分明)、代码生成(单元测试通过与否)。这类任务只需最终结果的奖励信号,无需中间的价值估计,完美契合 GRPO 的组内比较模式。
- 计算资源受限的环境:节省 30-40% 的显存开销,使得在单台机器上训练更大规模的模型成为可能。
- 训练初期的策略探索:在策略随机性较高的训练初期,GRPO 基于蒙特卡洛的方法方差相对较小,因为组内样本的多样性天然提供了丰富的对比信号。
- 需要快速迭代的研究项目:超参数更少,调参成本低,能加速实验循环。
(2)PPO 更适用的场景
- 密集奖励或连续控制任务:如果任务本身能提供步骤级的奖励信号,PPO 的 Critic 网络能更有效地利用这些中间信号进行自举学习。
- 具有长期依赖的任务:当序列极长(超过1000步)且奖励信号出现在序列中间时,PPO 的 GAE 机制在时序信用分配上可能优于蒙特卡洛方法。
- 拥有高质量预训练 Critic 时:如果已经通过其他方式获得了一个稳定、准确的价值函数估计网络,PPO 的偏差-方差权衡可能会优于纯蒙特卡洛的 GRPO(后者在奖励稀疏时方差可能较高)。
(3)混合训练策略
在实践中,越来越多的团队开始采用混合方案来取长补短:
- SFT 预热 + GRPO 微调:即 DeepSeek-R1 采用的路线。先用监督微调让模型掌握基础的回答格式,再用 GRPO 强化其推理能力。
- PPO 的渐进式启动:先用 GRPO 训练若干轮,得到一个初步优化的策略模型,然后用这个策略模型来初始化 PPO 中的 Critic 网络,从而降低 Critic 网络冷启动的难度和不稳定性。
04 工程实践建议
如果你决定尝试 GRPO,以下是一些来自实践的经验建议:
- 数学/代码类任务可优先考虑 GRPO:其实现简单,无需维护 Critic 网络,训练过程通常也更稳定。
- 采样数 N 建议设为 8-16:N 太小(如4)会导致组内方差过高,估计不准;N 太大(如32以上)则容易导致组内样本“全对”或“全错”,使得优势计算失效。8-16 是一个经验上的甜点区间。
- 监控组内奖励方差:如果
std(r_group) < 0.05,意味着奖励高度集中,表明当前任务对模型来说要么太简单,要么太难,都需要调整任务难度或模型能力。
- 注意采样温度:GRPO 对生成多样性敏感。温度过低(如0.5)会导致组内样本多样性不足,影响优势估计的质量。建议将
temperature 设置在 0.8 到 1.0 之间。
参考文献
- Schulman et al., Proximal Policy Optimization Algorithms, arXiv 2017
- Shao et al., DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, 2024
- DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via RL, 2025
- Hu et al., REINFORCE++: A Simple and Efficient Approach for Aligning LLMs, 2025
本文探讨了 强化学习 领域中两种重要算法的工程选型,希望对你的项目有所启发。关于大模型训练与对齐的更多深度讨论,欢迎访问 云栈社区 的智能与数据板块进行交流。 |  发表于 2026-3-24 03:21:39
|
查看: 323|
回复: 0
发表于 2026-3-24 03:21:39
|
查看: 323|
回复: 0
