当前,视觉语言模型的强化学习训练往往局限于几何题、图表分析等特定场景。这种领域的局限性,实际上制约了模型的探索和学习潜力。
那么,如何为VLM的强化学习训练开辟更广阔的天地?复旦大学NLP实验室的研究团队提出的 Game-RL,给出了一个新颖的思路:通过合成可验证的多模态游戏数据来激发VLM的通用推理能力。实验表明,这种方法不仅能让模型在多个域外的通用测试基准上实现泛化提升,其训练效果甚至能与传统的几何数据匹敌。更令人振奋的是,通过扩展训练游戏的数量和数据规模,模型的性能还能获得持续的增长。
这项研究揭示了一个重要方向:在游戏环境中进行规模化的强化学习,是提升模型通用推理能力的一条有效途径。

论文标题:
Game-RL: Synthesizing Multimodal Verifiable Game Data to Boost VLMs' General Reasoning
论文链接:
https://arxiv.org/abs/2505.13886
项目网站:
https://iclr26-game-rl.github.io
代码仓库:
https://github.com/tongjingqi/Game-RL
数据和模型:
https://huggingface.co/collections/OpenMOSS-Team/game-rl

Game-RL:VLM强化学习训练领域的重要拓展
电子游戏通常具备视觉元素丰富、规则明确且可验证的特点,这使其成为理想的多模态推理数据源。基于此,研究团队提出了 Game-RL 方法,其核心是构造多模态可验证的游戏任务,用于对VLM进行强化训练。下图展示了合成的游戏数据示例,涵盖了4个具有代表性的游戏。

图1:GameQA 数据集中各游戏类别的代表性任务:3D 重建、七巧板(变体)、数独和推箱子。每个游戏展示两个视觉问答示例,包含当前游戏状态图片、相应的问题、逐步推理过程和答案。

从游戏代码到训练数据:Code2Logic 方法的巧思
为了获得大规模、高质量的训练数据,团队提出了新颖的 Code2Logic 方法。该方法巧妙地通过游戏代码,系统化地合成可验证的游戏任务数据。
如图2所示,该方法主要分为三步:首先,利用强大的LLM生成可交互的游戏代码;其次,设计具体的任务及其问答模板;最后,构建数据引擎代码。完成这三步后,只需执行代码便能自动、批量地生成数据样本,并且能够灵活地控制样本难度和生成数据量,流程高效且可扩展。
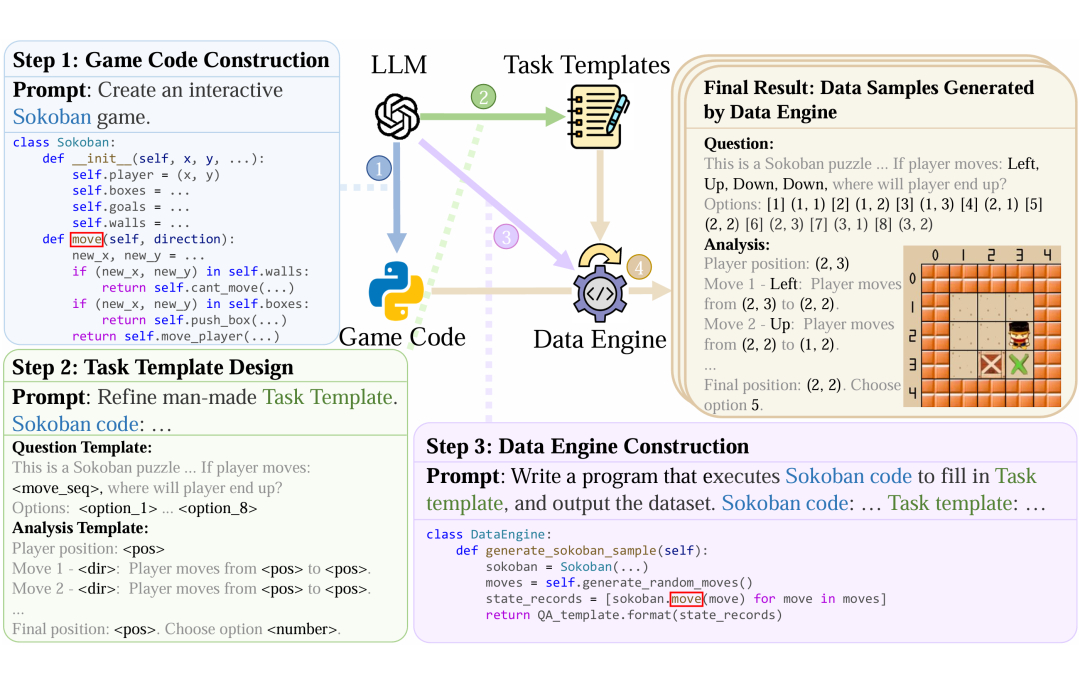
图2:Code2Logic 方法,借助 LLM 通过三个核心步骤将游戏代码转换为推理数据。第一步:游戏代码构建;第二步:游戏任务及其 QA 模板设计;第三步:数据引擎构建。基于前两步构建自动化程序,执行代码即可自动批量生成数据。

GameQA:丰富的游戏任务数据集
利用上述 Code2Logic 方法构建的 GameQA 数据集,不仅能用于评测VLM的推理能力,更重要的是可以作为多模态可验证的游戏任务数据,用于强化训练VLM。
GameQA 数据集具有以下特点:
- 涵盖4大认知能力类别:3D空间感知与理解、模式识别与匹配、多步推理、战略规划。
- 包含30个不同游戏(如图3分类),158个不同的推理任务,总计约14万个问答对。
- 难度分级:任务本身按难度分为三级;同时,样本也按视觉输入的复杂度分为三个级别。
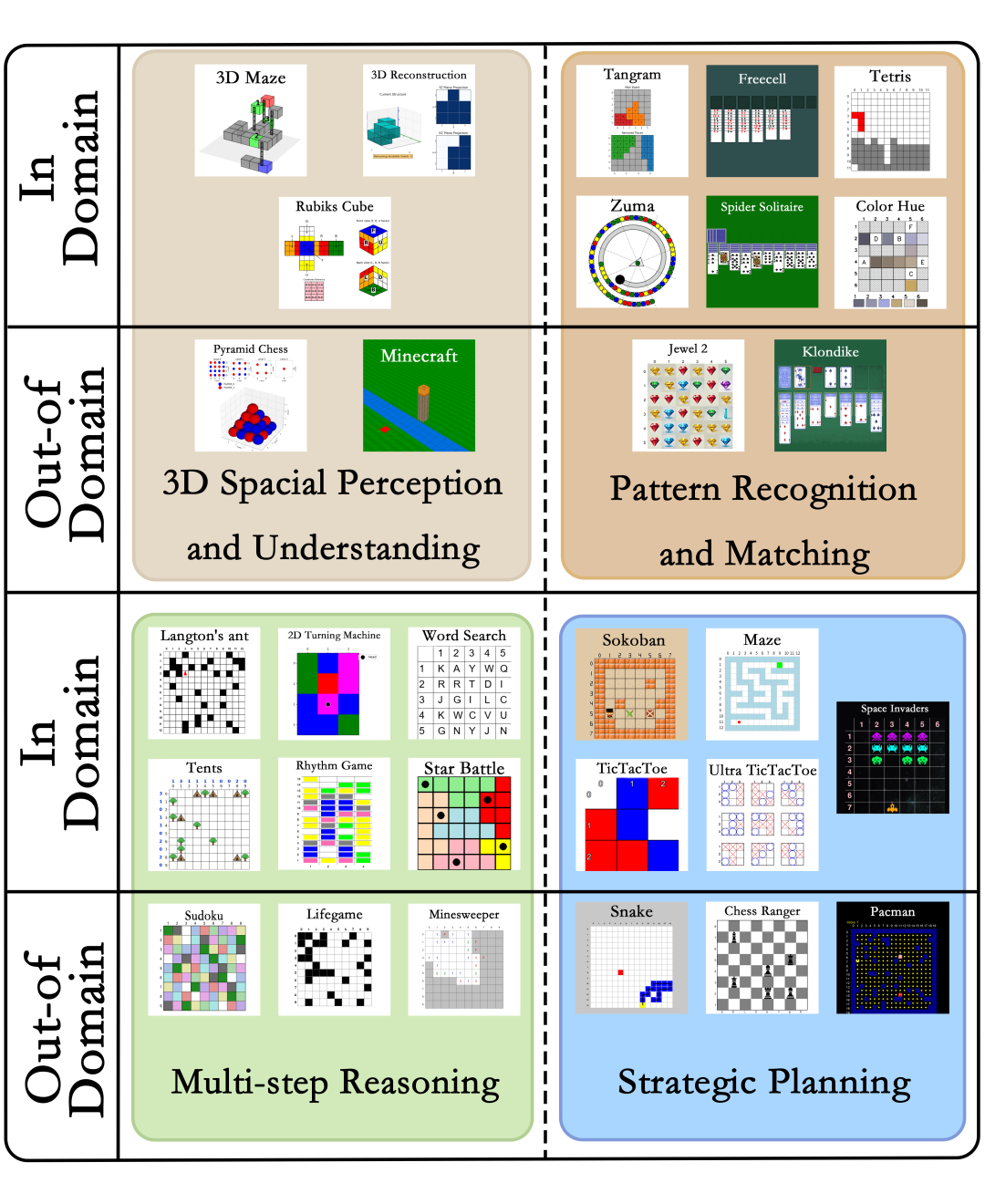
图3:GameQA 的 30 个游戏,分为 4 个认知能力类别。其中20个域内游戏用于训练和测试,而10个域外游戏不参与训练,专门用于测试模型在未见游戏场景下的泛化能力。

核心发现 I:Game-RL 带来了可泛化的通用推理提升
研究团队使用 GRPO 算法在 GameQA 数据集上对多个开源VLM进行训练。结果显示,训练后的模型在7个完全域外的通用视觉语言推理基准上均取得了显著提升(以 Qwen2.5-VL-7B 为例,平均提升达2.65%),这清晰地展现了该方法强大的跨领域泛化能力。具体数据见表1。
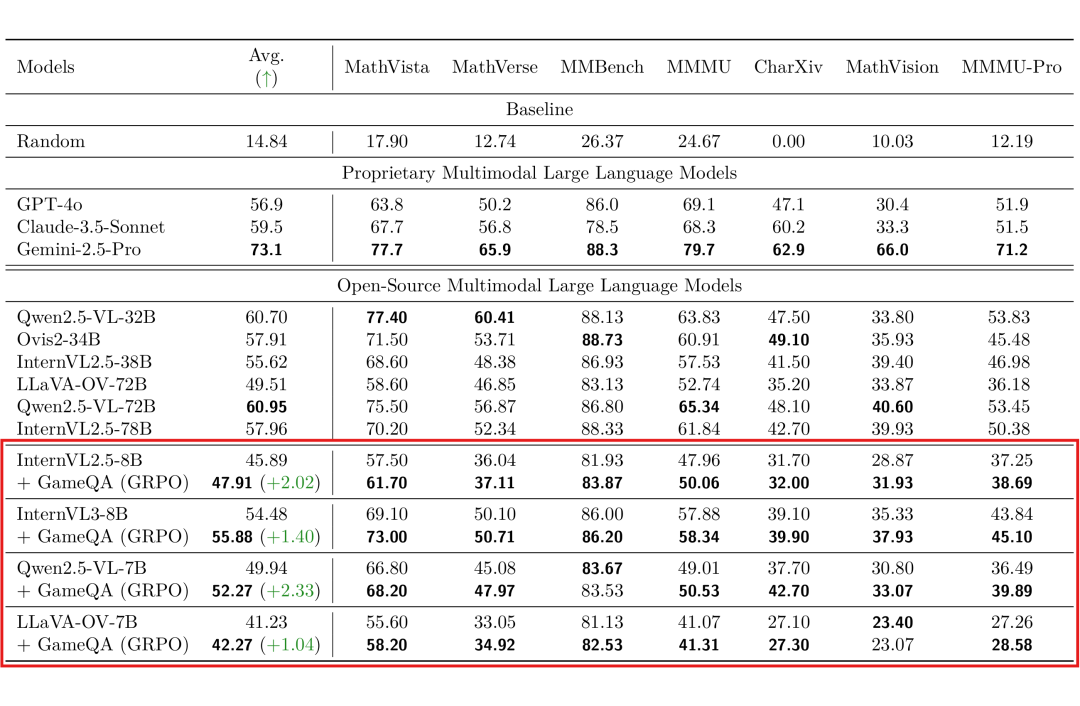
表1:通用视觉语言推理基准上的评测结果。经过GameQA (GRPO)训练后,多个开源VLM在MathVista、MathVerse等基准上表现均有提升。

核心发现 II:游戏数据训练效果竟匹敌几何数据
为了评估游戏数据的有效性,研究团队将其与专门的几何与图表推理数据集进行了对比训练。一个有趣的发现是:GameQA 的训练效果可以与这些“对口”的数据集相匹敌,甚至在部分基准上表现更优。
如表2所示,尽管GameQA的训练数据量更少,且与测试基准的领域不完全匹配,但其训练出的模型在通用基准上的总体表现极具竞争力。特别值得注意的是,在MathVista与MathVerse这两个与几何、函数推理密切相关的基准上,Game-RL 的训练效果甚至超过了使用专门几何数据训练的模型。
这表明,游戏中蕴含的认知多样性和推理复杂性,具有超出特定领域的通用性和强大的迁移能力。
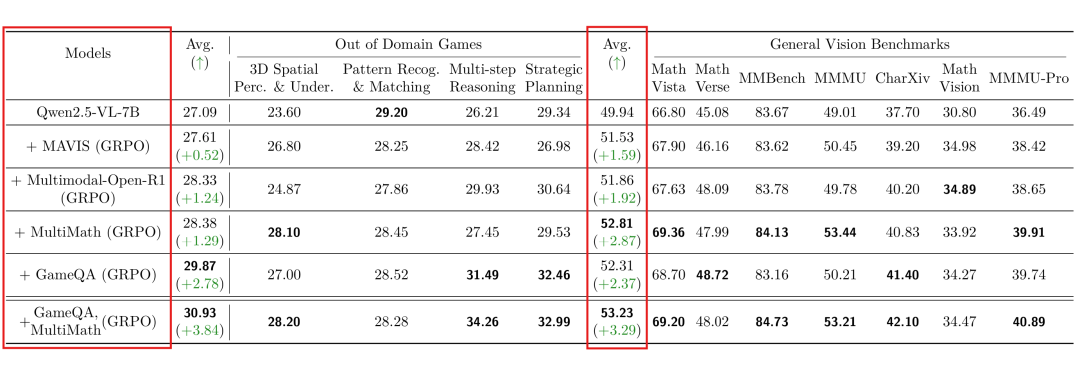
表2:不同数据源训练效果对比。使用5K GameQA样本训练的模型,其表现与使用8K几何/数学数据训练的模型总体相当,并在部分基准上领先。混合训练(GameQA + MultiMath)能带来进一步的提升。

核心发现 III:训练数据量和游戏个数的 Scaling Effect
研究进一步探索了规模扩展的影响,发现了两个积极的“Scaling Effect”:
-
数据量的 Scaling Effect:将训练的 GameQA 数据量增加至 20K。如图4所示,模型在通用推理基准上的表现总体呈现持续提升的趋势,说明更多的游戏数据有助于巩固和提升模型的通用能力。
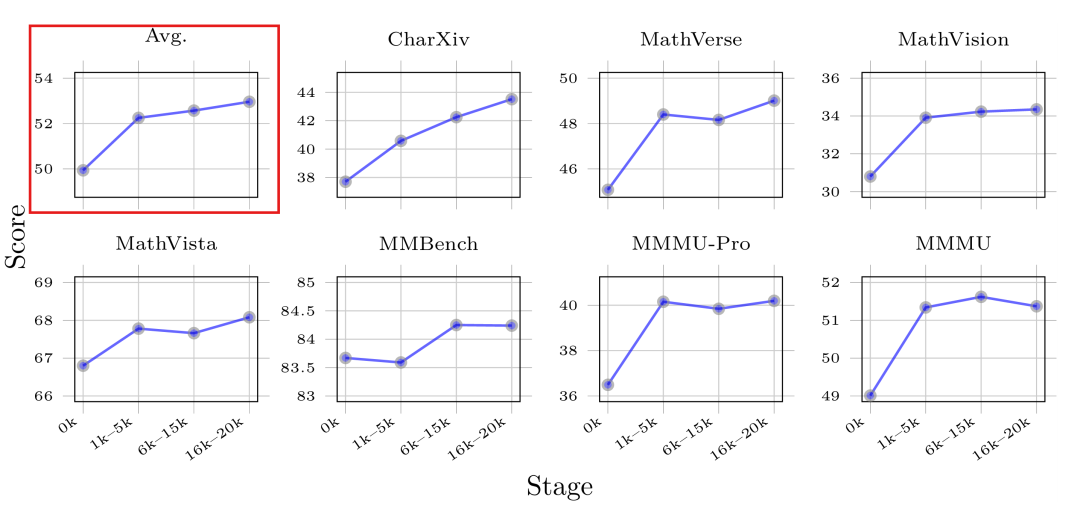
图4:训练数据量的 Scaling Effect。随着训练数据量(Stage)增加,模型在多个通用基准上的得分(Score)呈上升趋势。
-
游戏种类的 Scaling Effect:如图5所示,随着训练所涵盖的游戏种类增多,模型在域外通用基准上的泛化提升效果也更加明显。使用20种游戏进行训练,其效果显著优于仅使用4种游戏的配置。
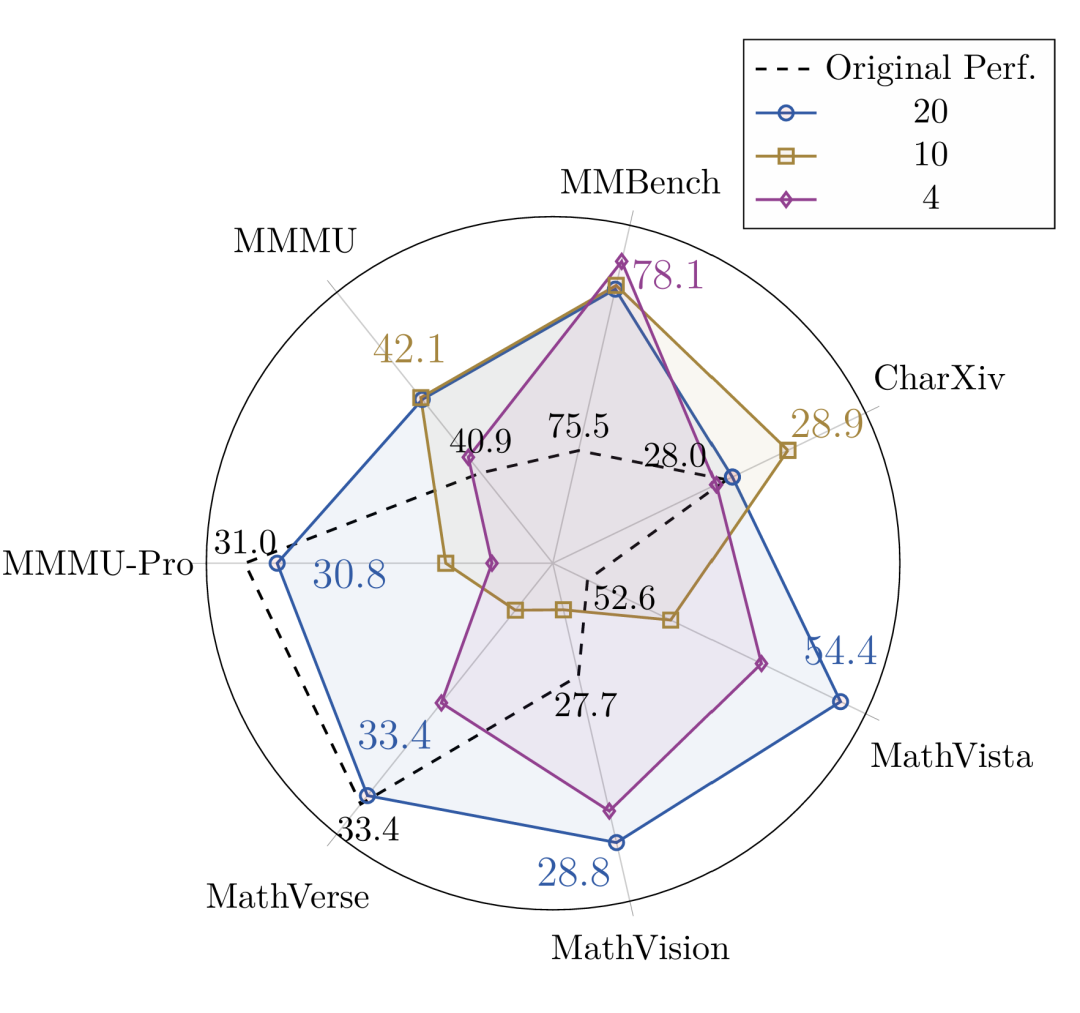
图5:使用 20 种游戏的任务训练,模型在域外通用基准上的提升(彩色线)优于使用4种游戏的配置(灰色线)。

深度剖析:Game-RL 后模型能力提升在哪?
为了更深入地理解 Game-RL 如何提升 VLM 的推理能力,研究团队对模型在训练前后的表现进行了细致的案例人工分析。
分析结果显示,经过 Game-RL 训练后,模型在视觉感知和文本推理两个方面均得到了改善。如图6上方的饼图所示,在域外基准任务中,超过80%的案例在两方面均无变化或有所提升。下方的案例则具体展示了一个视觉感知能力提升的例子:训练后的模型能够更准确地识别并描述图表中数据序列的相对关系。
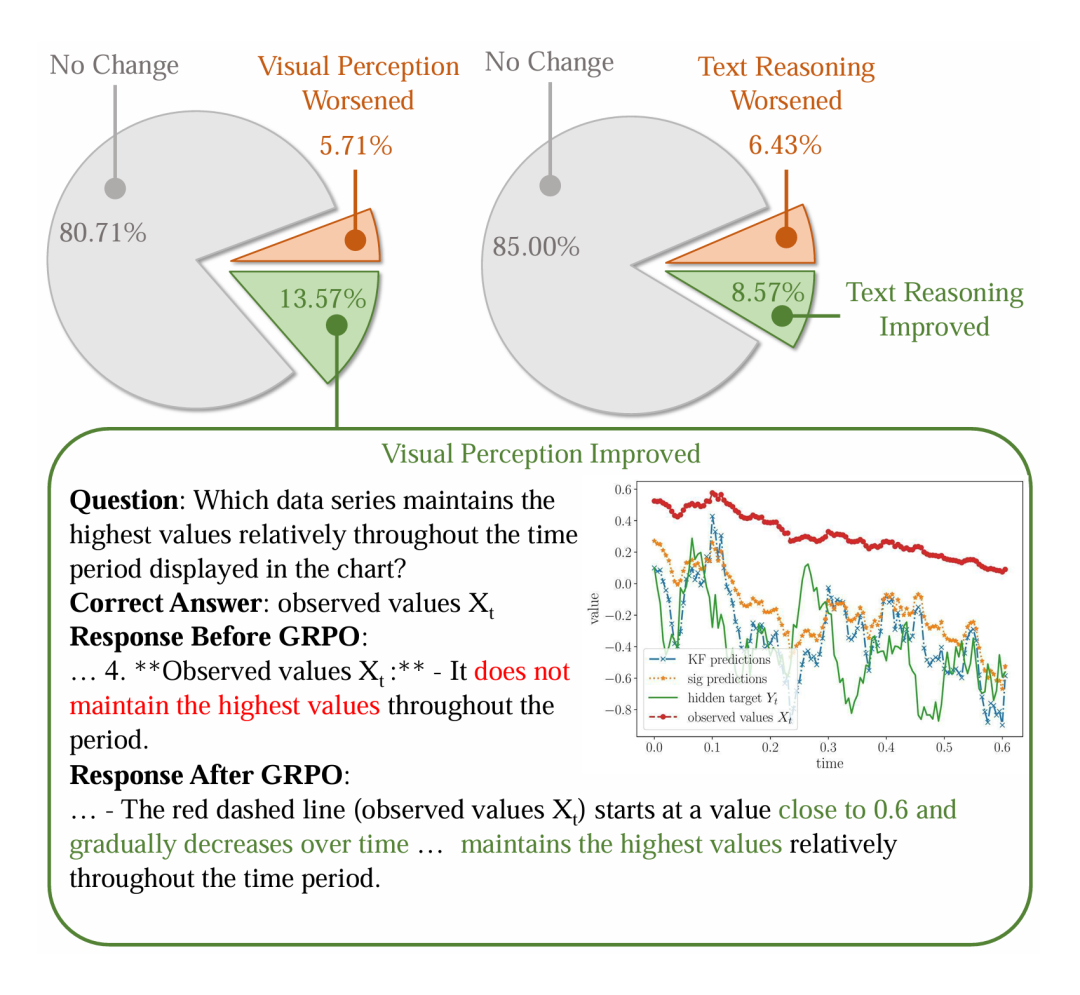
图6:人工定性分析。上方的饼图分别展示了模型在视觉感知和文本推理能力上的变化分布。下方是一个具体的视觉感知能力提升案例。

结论
本研究提出了 Game-RL 框架及配套的 Code2Logic 可验证游戏数据合成方法,并构建了大规模的 GameQA 数据集,成功地将VLM的强化学习训练领域拓展到了丰富多样的游戏场景。
通过系统的实验,研究证实了 Game-RL 能够有效提升 VLM 可泛化的通用推理能力。此外,游戏数据的训练效果足以媲美甚至部分超越传统的几何数据,并且扩展训练的游戏种类和数据量能为模型带来持续的收益。
这项研究为 强化学习 在通用人工智能训练中的应用开辟了一条新路径,表明在游戏环境中进行规模化的强化学习,是提升模型通用认知与推理能力的一个重要且有效的方向。
 发表于 2026-3-24 03:16:56
|
查看: 128|
回复: 0
发表于 2026-3-24 03:16:56
|
查看: 128|
回复: 0
