逼真且高效的 3D 服装生成,一直是计算机视觉与数字时尚领域的一个长期挑战。现有方法多基于大型视觉语言模型,先输出缝纫图案的序列化表示,再通过 GarmentCode 等服装建模框架将其转换为可仿真的 3D 网格。
虽然这些方法产出的结果质量很高,但其推理速度往往不尽如人意,生成一件服装通常需要 30 秒到 1 分钟。那么,有没有办法将这两个步骤统一起来,实现更快的端到端生成呢?
在这项工作中,我们提出了 SwiftTailor。这是一个新颖的两阶段框架,其核心思想是利用一种紧凑的几何图像表示,将缝纫样板推理与基于几何的网格合二为一。
SwiftTailor 包含两个轻量化模块:PatternMaker 和 GarmentSewer。
- PatternMaker 是一个高效的视觉语言模型,能够从文本或图像等多种输入中预测出缝纫样板。
- GarmentSewer 则是一个基于 Transformer 架构的密集预测网络,它能将这些样板转换为一种新颖的“服装几何图像”。这种图像在统一的 UV 空间中,编码了所有服装裁片的完整 3D 表面信息。
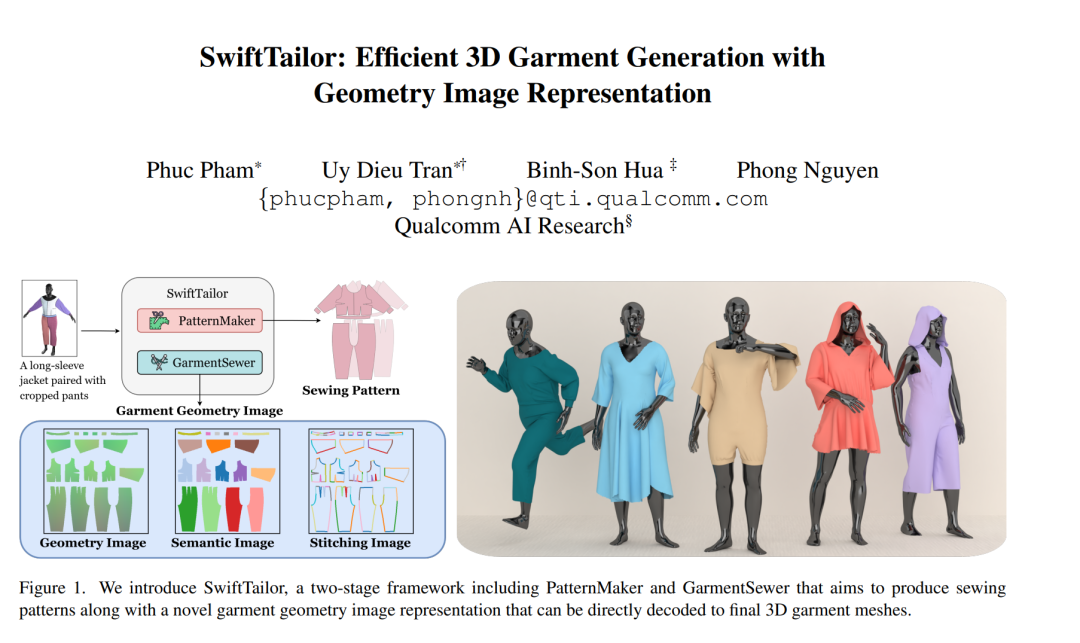
最终的 3D 网格通过一个高效的逆映射过程重建出来。这个过程结合了重网格化和动态缝合算法,可以直接组装服装,从而完全避免了传统物理仿真带来的巨大计算开销。
在 Multimodal GarmentCodeData 数据集上的实验表明,SwiftTailor 在显著缩短推理时间的同时,仍然保持了最先进的生成准确度和视觉逼真度。这为下一代 3D 内容创作,尤其是在需要快速原型设计和批量生成的数字时尚与虚拟人应用中,提供了一个极具潜力的解决方案。
从整体流程来看,SwiftTailor 的工作机制非常清晰。PatternMaker 模块基于一个轻量化的视觉语言模型 InternVL-3-2B,专门训练用于输出结构化的缝纫图案。这些图案由离散的标记和连续的参数构成。
随后,GarmentSewer 模块登场。它首先对缝纫图案进行预处理,得到语义图和缝合图,然后将它们输入到一个 DPT-ViT(密集预测视觉 Transformer)模型中,预测出最终的几何图像。这一步完成了其核心的“服装几何图像表示”。最后,经过一个后处理步骤,将几何图像转换为可供渲染和使用的 3D 网格模型。
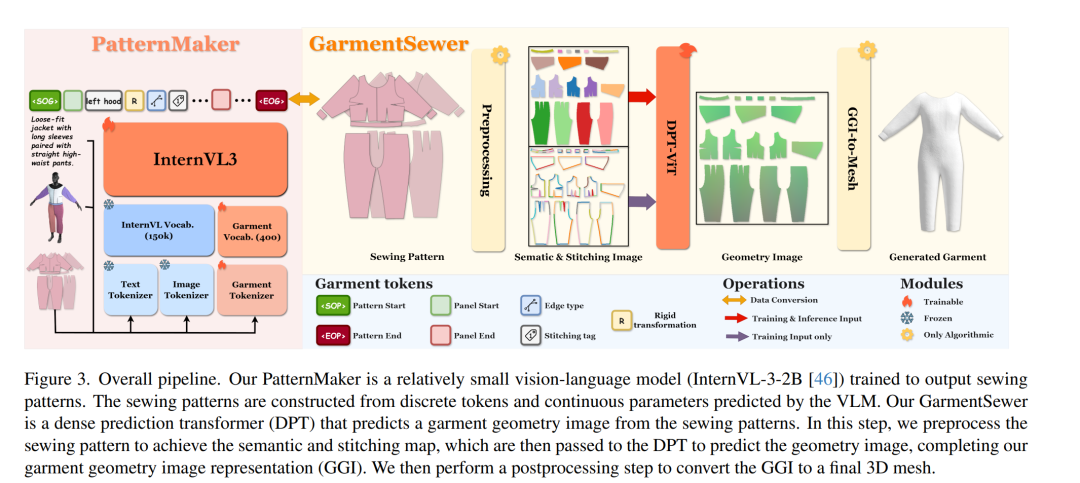
总而言之,SwiftTailor 通过引入几何图像这一中间表示,巧妙地绕开了耗时的物理仿真,在计算机视觉驱动的 3D 内容生成效率上迈出了关键一步。其两阶段、模块化的设计也使得整个系统更易于理解和扩展。如果你对这类结合了 AIGC 与Transformer模型的前沿技术感兴趣,欢迎到 云栈社区 与更多开发者交流探讨。 |  发表于 2026-3-24 17:35:58
|
查看: 167|
回复: 0
发表于 2026-3-24 17:35:58
|
查看: 167|
回复: 0
