AI 换脸、AI 造谣早已无孔不入,一张篡改的图片、一段大模型生成的通顺文案,就能炮制出一条以假乱真的新闻,搅动舆论、误导公众。然而,现有的检测系统在面对这类攻击时,却常常“视而不见”。
问题的核心在于,当前的假新闻检测技术,像个只会找“图文错别字”的新手——它只擅长识别图文不匹配的低级伪造,却对多模态大模型精心打造的、语义严丝合缝、逻辑毫无破绽的高欺骗性内容,彻底束手无策。
政客换脸伪造的现场新闻、名人表情篡改搭配的虚假声明、真实画面搭配AI大模型编造的误导叙事……这些关键场景的识别与拦截,正是计算机视觉与内容安全领域亟待攻克的“最后一公里”痛点。现有技术对此力不从心,急需能识破“一致性陷阱”的新一代智能检测方案。
西安交通大学、合肥工业大学和澳门大学的研究团队,在CVPR 2026上提出了一套从数据集构建到跨模态建模的全流程解决方案。论文、代码、数据集均已开源,为探索多模态内容安全新范式提供了有力工具。

论文名称: The Coherence Trap: When MLLM-Crafted Narratives Exploit Manipulated Visual Contexts
论文链接: https://arxiv.org/abs/2505.17476
代码 & 数据集: https://github.com/YcZhangSing/AMD
新挑战:AI大模型带来的「一致性陷阱」,传统检测失灵
不止找图文不匹配,更要识破「看起来全对,实则全假」的完美骗局!
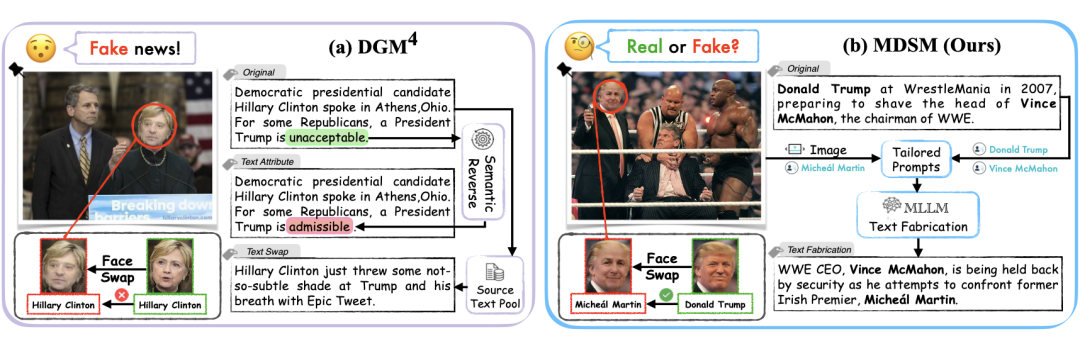
图文一致的伪造(右)与传统的图文错位的伪造(左)的比较
传统方案通常将视觉篡改和文本编辑拆成两个独立步骤,造出来的假内容满是图文错位的破绽,普通人也能一眼看穿(上图左)。
而真实世界的恶意攻击,早已用上了更隐蔽的套路:先精准篡改图像,再用AI大模型生成与篡改画面完全对齐、语境通顺的虚假叙事,彻底抹平所有显性破绽(上图右)。这种“一致性陷阱”,直接戳中了现有研究的两大致命短板:
- 低估AI大模型的欺骗风险:主流方案只针对规则化的文本篡改,完全忽视了AI大模型能生成高连贯、高迷惑性虚假内容的能力,对新型攻击毫无防备;
- 与真实场景严重脱节:现有数据集大多是人工制造的图文不匹配样本,欺骗性极低,训练出的模型在真实攻防中完全“水土不服”。
44万+图文基准:MDSM数据集发布!还原真实世界的AI假新闻
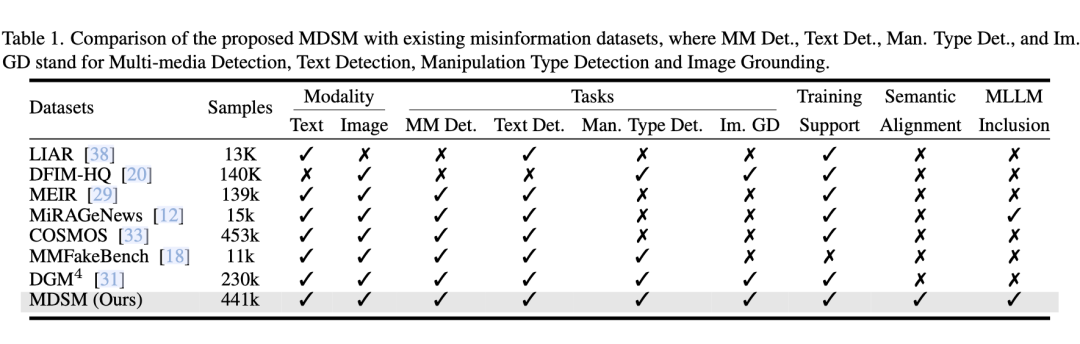
大模型驱动的多模态伪造数据集(MDSM)与现有数据集的综合比较
为解决上述问题,研究团队构建了全新的MDSM数据集,其特点如下:
- 规模空前:包含超44.1万高质量图文对,源数据覆盖《卫报》《纽约时报》等五大主流媒体,是目前多模态伪造检测领域规模最大的基准数据集。
- 高度语义对齐:业界首个全量样本实现图文语义完全对齐的基准,完美复刻真实攻击场景,检测难度指数级提升。
- 场景真实全面:涵盖人脸换脸、属性篡改、文本伪造等5类核心伪造类型,同时支持虚假内容检测、伪造类型识别、篡改区域定位三大核心任务。
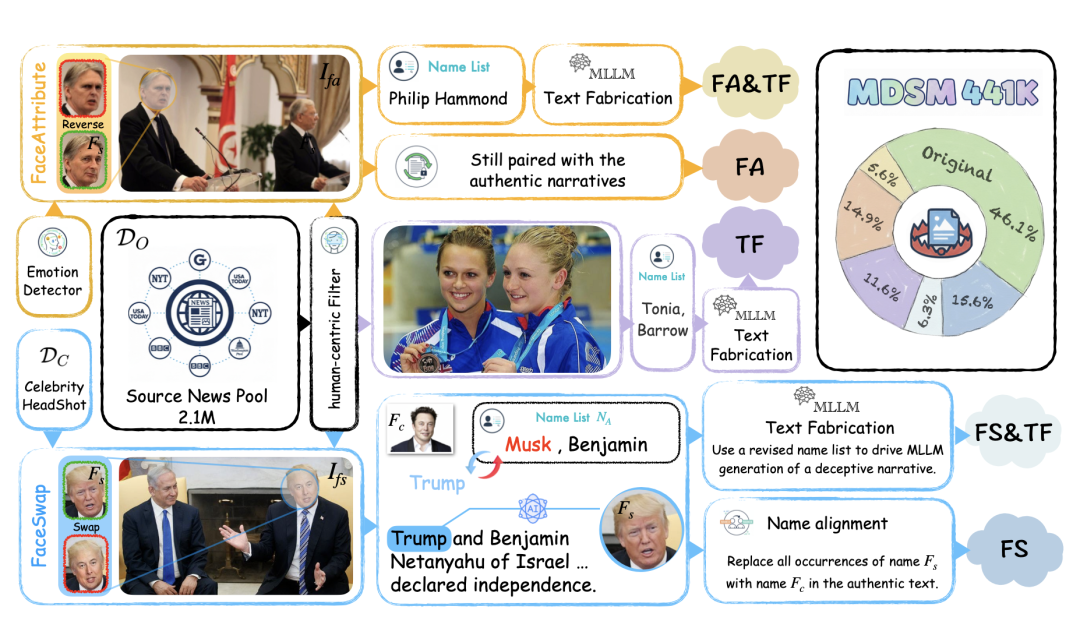
大模型驱动的多模态伪造数据集(MDSM)的构建流程
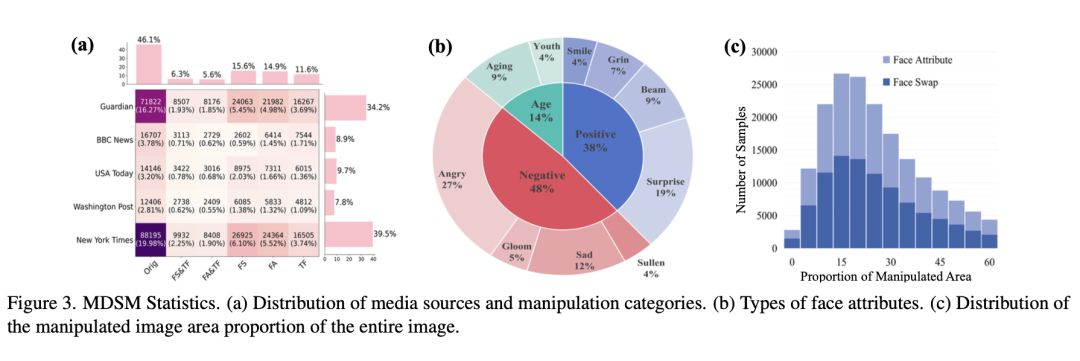
大模型驱动的多模态伪造数据集(MDSM)的数据统计
「伪影捕手」AMD框架:一眼看穿AI大模型的伪造套路
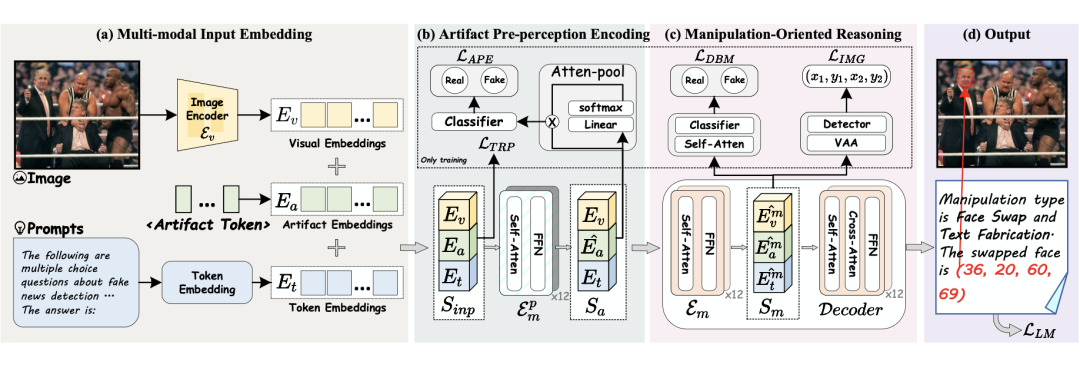
操纵诊断模型 (AMD) 的框架概述
针对“一致性陷阱”,研究团队提出了名为AMD(Artifact-aware Manipulation Diagnoser)的检测框架。
- 看懂“伪影”辨真假:创新设计伪影预感知编码机制,给模型装上“伪造雷达”,专门捕捉篡改内容留下的隐性痕迹,在保留海量世界知识的同时,注入极强的伪造感知能力。
- “双路找茬”精准定位:采用面向伪造的推理模块,双分支交叉捕捉视觉、文本双模态的伪造线索,同时精准定位图像中的篡改区域,实现“是否造假+哪里造假+造了什么假”的端到端全流程识别。
- 轻量化高效率:仅用0.27B参数量,就实现了超百亿级通用大模型的检测效果,兼顾顶尖性能与极快推理速度。
实验结果:性能全面领跑SOTA,效果惊艳!
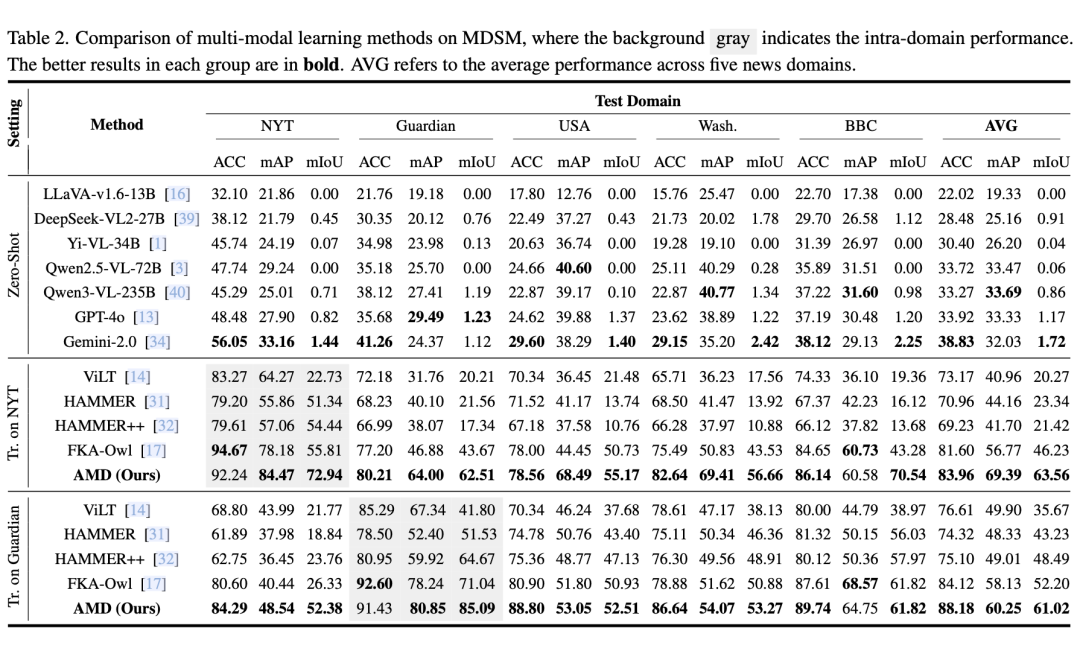
表2:MDSM数据集上多模态学习方法的性能对比(背景灰色表示域内性能)
实验结果表明,AMD框架在多方面展现出显著优势:
- 核心性能拉满:如表2所示,在MDSM跨域测试中,AMD实现平均88.18% ACC、60.25 mAP、61.02 mIoU 的顶尖成绩,全面碾压ViLT、HAMMER++、FKA-Owl等现有SOTA方案。
- 通用大模型集体失灵:GPT-4o、Gemini 2.0、Qwen3-VL等通用大模型,在该场景下零样本检测效果几乎失效,进一步印证了AMD的针对性优势。
- 超强泛化能力:如表3所示,在跨数据集DGM⁴测试中,AMD依然拿下平均74.47% ACC 的最优成绩,表现出强大的场景适应能力。
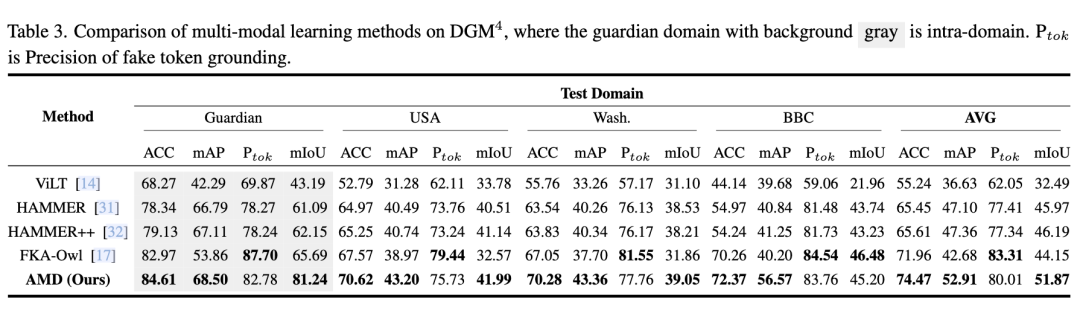
表3:DGM⁴数据集上的跨数据集性能对比
- 小参数高性能:如表4所示,仅0.27B参数量,在RTX 4090上推理速度可达13.38 pairs/s,在精度与效率间取得了优秀平衡。
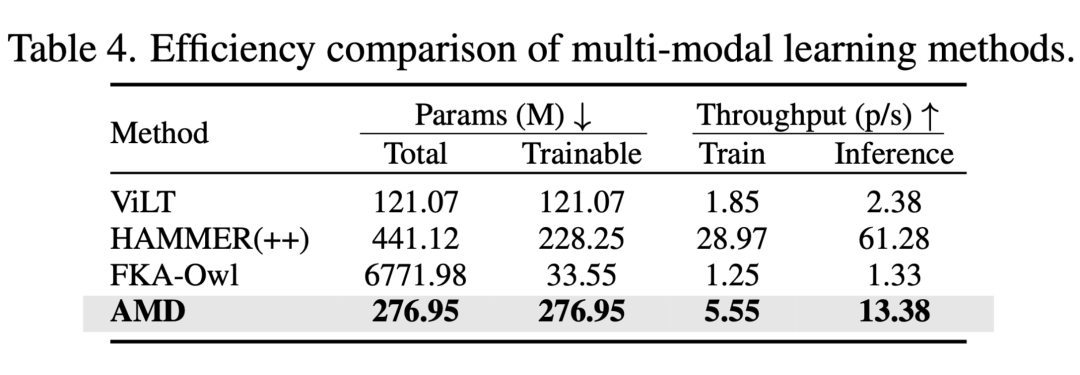
表4:多模态学习方法的效率对比
为什么这很重要?
这项研究的意义远超技术本身,主要体现在三个方面:
- 内容安全全面升级:为社交媒体风控、新闻真实性核验、舆情防控等场景提供了强大的“AI假新闻识别引擎”,有望精准拦截AI时代的高欺骗性虚假信息,筑牢数字内容安全防线。
- 行业研究破局拐点:首次系统性揭示了AI驱动的一致性伪造风险,填补了该领域的研究空白。MDSM数据集更是解决了长期以来“数据与真实场景脱节”的核心瓶颈,有望推动整个多模态内容安全领域的技术迭代。
- 落地效率倍增:轻量化、端到端的统一架构,无需复杂的多模块组合,即可实现全维度的伪造检测,大幅降低了产业落地门槛,让AI内容安全技术真正变得能用、好用。
|  发表于 2026-3-25 00:03:19
|
查看: 171|
回复: 0
发表于 2026-3-25 00:03:19
|
查看: 171|
回复: 0
