
过去几年我一直从事内容质量方面的算法工作,近期出于兴趣对假新闻这个领域做了一些调研。本文将我的学习心得简单总结一下,希望能为读者提供一个清晰的概览。
假新闻检测在某种程度上是一个微观领域问题,它与谣言鉴别、事实核查、标题党检测、垃圾内容挖掘等任务有相似之处。从宏观上看,这些都属于内容质量管控的范畴,因此很多技术方法和框架其实是相通的。
本文将简要介绍业界常见的实践思路,并重点解读几篇具有代表性的学术论文。我们会从不同的技术路径出发,了解多模态信息融合、网络传播分析以及深度特征挖掘等手段在虚假新闻检测领域的具体应用。
模型构建的基本思路
根据 [Kai Shu, 2017] 的划分,虚假新闻检测模型主要可以分为两大类:1)基于新闻内容本身的建模;2)基于社交网络上下文的建模。
1. 基于内容建模
基于内容的建模又可以细分为两个方向:1.1 面向知识库和事实核查的;1.2 面向文章行文风格分析的。
1.1 面向知识库与事实核查
事实检查系统有点类似于谣言鉴别系统,核心是对文章描述的观点和客观事实进行校验。这本质上是一个复杂的自然语言处理问题,涉及知识表示、知识推理等技术。目前,构建用于事实核查的知识库主要有以下几种途径:
1. 专家系统:依赖各个领域专家人工构建的知识库。这种方式精度可能较高,但效率和可扩展性非常差。不过,在生物、历史等客观事实较多的垂直领域,或许可以尝试。
2. 集体智慧:利用用户集体的反馈和知识来构建知识库,例如维基百科模式。
1 和 2 结合:在积累了上述知识库后,可以通过检索和相似度计算的方法,利用历史内容中蕴含的特征来对新内容进行判断。
3. 基于算法的分类与推理:使用知识图谱或事理图谱对内容的真实性进行逻辑推理。当前主流的开放知识图谱有 DB-pedia 和 Google Relation Extraction 数据集等。
这个领域的问题,类似于自然语言处理中的问答系统。有兴趣的读者可以参考 [Yuyu Zhang, 2017] 提出的 VRN(Variational Reasoning Network,变分推理网络)。
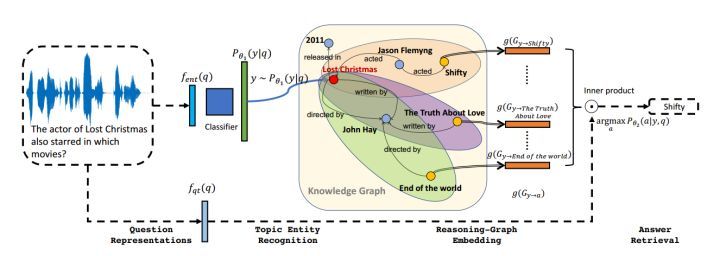
该工作通过概率模型识别问句中的实体,在知识库上进行可学习的逻辑推理,此框架也可用于事实判断。
目前,这个方向的技术落地成本高、难度大,且最终效果不一定理想。
1.2 面向内容风格分析
这类方法不关注内容陈述的事实真伪,而是分析文章本身的行文风格。例如,通过上下文无关文法分析句子的句法结构,或利用 RST(修辞结构理论)等 NLP 深度模型来捕捉文本的修辞和文法信息。
根据所捕捉信息的不同,又可以分为两类:检测文本的欺骗性程度,以及检测描述的主观/客观程度(通常越客观公正的内容可信度越高)。“震惊体”标题党就属于典型的风格问题。
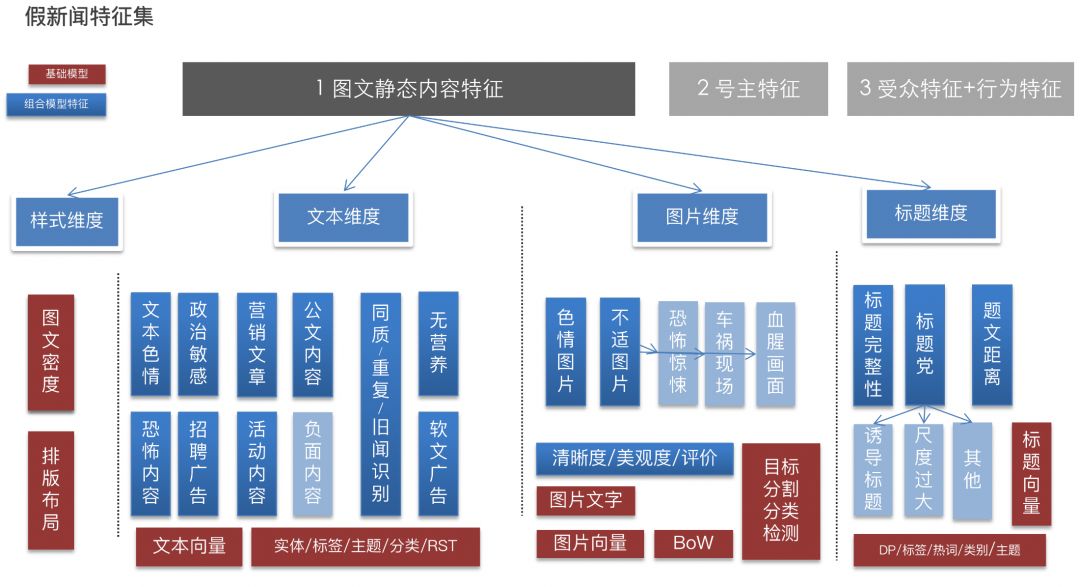
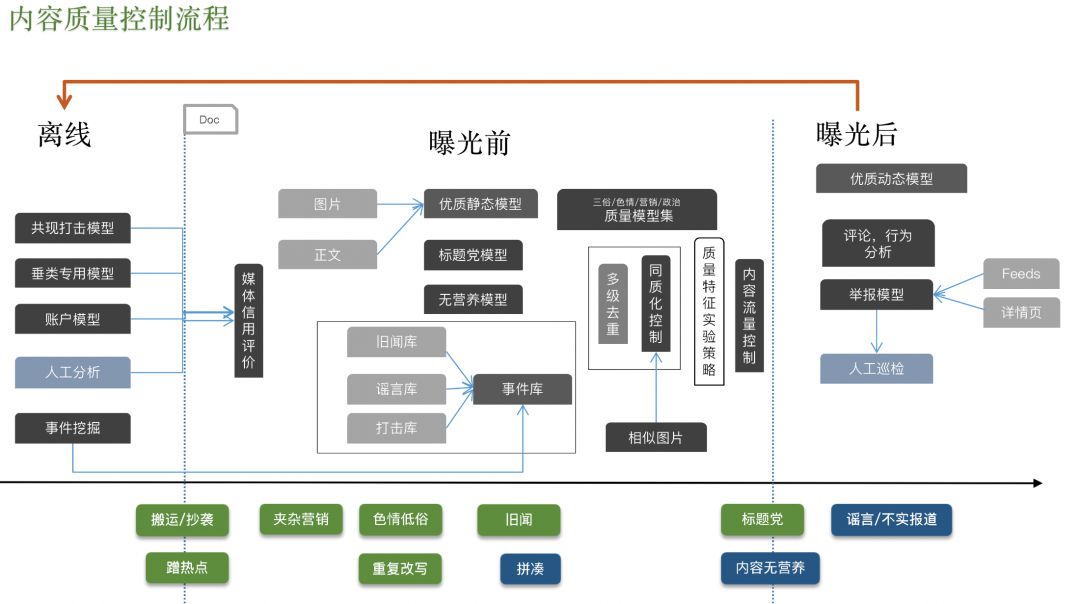
虚假新闻检测可能用到的特征非常庞杂,大致可分为普通特征和聚合特征两大类。普通特征指页面、文本、图片、标题等单一模态的特征嵌入表示。聚合特征则是将各类普通特征进行组合,并通过有监督训练成一个个子模型(如标题党模型、低质模型)。这些子模型的输出又可以作为更高层的聚合特征,用于最终的虚假新闻判定。
下图展示了我们在实践中使用的一个主要特征集合:
2. 基于社交网络建模
基于社交网络的方法也可以分为两种:基于用户立场的和基于信息传播行为的。
基于立场的方法主要利用用户对内容的操作行为(如评论、点赞、转发、举报等)来构建关系矩阵或图模型。
基于传播行为的方法则对信息的传播路径和扩散模式进行建模,类似 PageRank 的思想。下文将要介绍的 News Verification by Exploiting Conflicting Social Viewpoints in Microblogs 一文就属于这种类型。
具体的研究方向包括:
- 对虚假新闻的传播轨迹进行跟踪,并利用图模型或演化模型对特定假新闻事件进行深入分析。
- 识别虚假新闻传播过程中的关键节点(传播者),这对于遏制其在社交媒体上的扩散范围至关重要。
虚假新闻研究的主要方向
[Kai Shu, 2017] 的文章总结了该领域的几个主要研究方向:
数据方面的研究:目前仍缺乏标准、统一的评测数据集,这是亟待解决的问题。此外,如何利用传播特性实现更早的虚假新闻检测也是一个重点。另一个常被忽视的角度是从心理学出发,进行虚假新闻的发布意图检测。
模型特征方面的研究:通常会综合利用用户画像特征、内容特征(来自 NLP 和 CV)以及传播网络特征(如用户与内容互动构成的关系网络及其嵌入表示)。
模型方法方面的研究:首先是不同特征之间的有效融合。其次是预测目标的多样化设计。再者,无论是基于内容源、文章风格还是用户反馈(评论等行为)的单一模型都有其局限,因此需要探索如何组合这些模型。最后是通过空间变换,将特征映射到潜在的语义空间中进行求解。
常用数据集
FakeNewsNet
包含来自 BuzzFeed 和 PolitiFact 两个平台的数据,不仅包括新闻内容本身(作者、标题、正文、图片/视频),还包含了社交上下文信息(用户画像、收听、关注等关系)。
数据集获取方式:
https://github.com/KaiDMML/FakeNewsNet
代表论文:

LIAR
该数据集同样来源于 PolitiFact,包含新闻内容及其基础属性(如声明来源、正文)。
数据集获取方式:
http://www.cs.ucsb.edu/~william/data/liar_dataset.zip
代表论文:

Twitter and Weibo DataSet
一个较为全面的微博/推特谣言数据集,包含帖子 ID、发帖用户 ID、正文、回复等数据。
数据集获取方式:
http://alt.qcri.org/~wgao/data/rumdect.zip
代表论文:

被上述 CSI 模型等论文所使用的数据集。包含来自 Twitter 2015 和 2016 年的帖子,以及帖子间的树状回复、关注关系和正文内容。
数据集获取方式:
https://www.dropbox.com/s/7ewzdrbelpmrnxu/rumdetect2017.zip?dl=0
代表论文:

Buzzfeed Election Dataset & Political News Dataset
包含 Buzzfeed 在 2016 年美国大选期间收集的选举相关假新闻,以及作者收集的 75 个新闻故事,涵盖假新闻、真新闻和讽刺新闻。
数据集获取方式:
https://github.com/rpitrust/fakenewsdata1
代表论文:

数据驱动的特征洞察
[Benjamin D. Horne and Sibel Adalı, 2017] 通过手工构建大量特征,并运用单因素方差分析和秩和检验进行数据挖掘,发现了一些有趣的模式:
- 真新闻文章的平均长度明显长于假新闻。
- 假新闻很少使用技术词汇,使用的标点符号更少,引号也更少,但词汇冗余度更高。
- 标题特征差异明显:假新闻的标题更长,更倾向于增加名词和动词。
- 真新闻倾向于通过说理来服人,而假新闻更喜欢通过情绪渲染来吸引眼球。
类似的内容分析研究还有 Automatic Detection of Fake News。
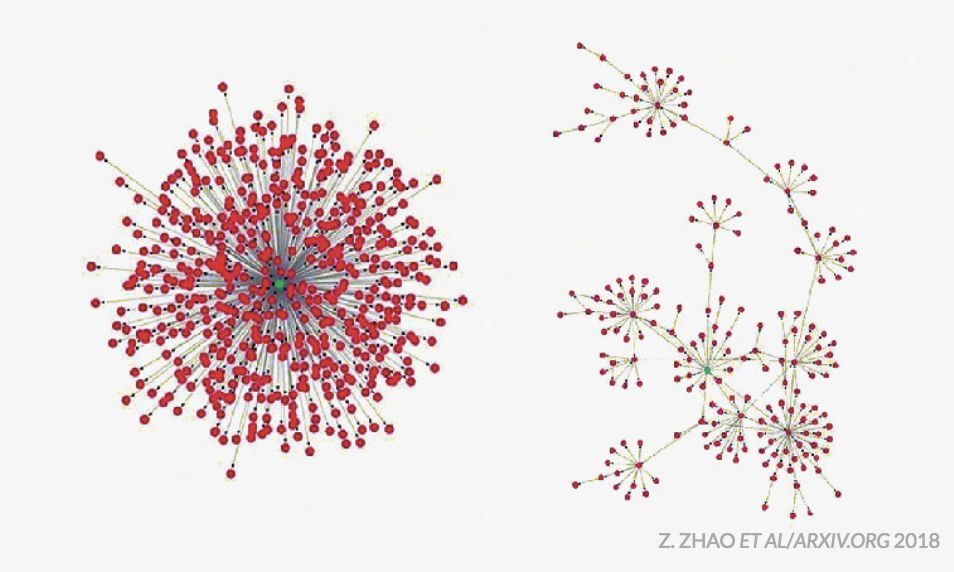
[Z. Zhao et al., 2018] 通过分析转发网络发现:大多数人转发真实新闻时,往往源自少数几个集中的信源(图中绿点)。而虚假新闻的传播则更多是通过用户之间相互转发(红点)形成的链式或网状结构。
核心论文深度解读
在工业界,例如各大互联网公司,解决虚假新闻问题主要依靠构建一个复杂的处理流水线,融合多个模型:包括内容侧模型集、用户侧模型集,并结合发布者特征、内容产生后的用户行为特征等,综合构建一套防控体系。
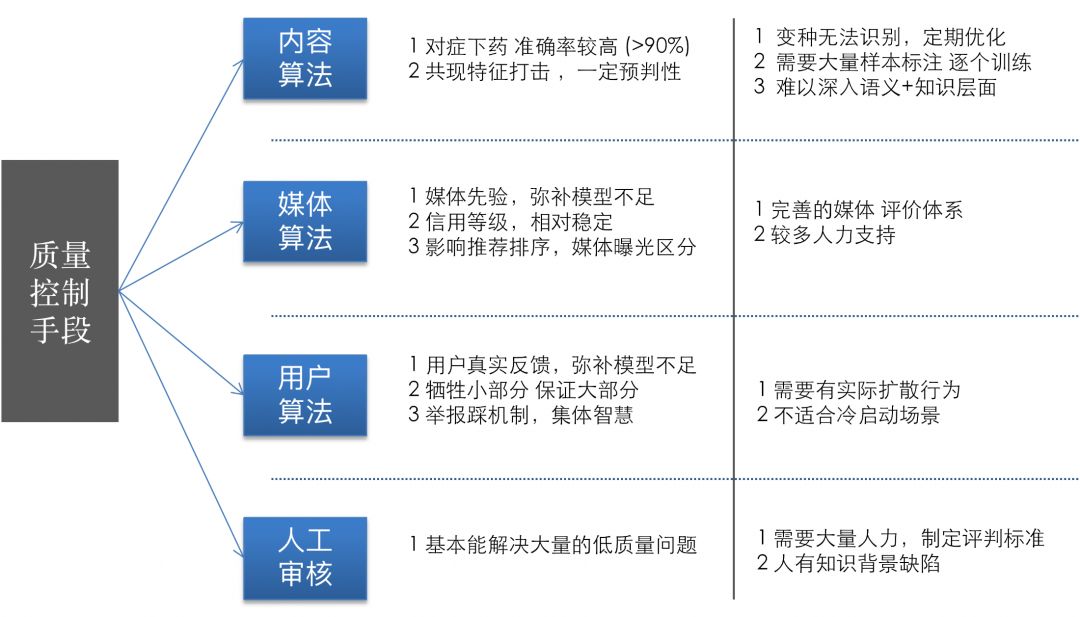
我们在实际应用中,结合了数十个静态与动态特征模型,并辅以知识库进行召回,再通过人工进行验证。
然而,与工业界处理问题的方式不同,顶级学术会议上的相关论文通常基于特定数据集的特点,专注于通过单一但精巧的模型来解决问题。这些模型主要从三个维度参考并融合特征:1)内容本体;2)内容生产源(如来源、发布者);3)内容消费者(用户)及其行为(如订阅、评论)。
许多研究尝试通过端到端的深度学习、基于概率分布的特征挖掘,或构建新颖的综合损失函数等“大一统”的方式来解决。不过,很多复杂模型目前仍只能在小规模数据集上进行实践。下面我们介绍几篇较新且有代表性的学术论文。

这篇是 CIKM 2017 的 Long Paper。 作者认为,构建完整的社交图谱并不容易,而手工设计假新闻特征又需要大量先验知识。文章指出,以往的检测方法未能很好地一次性整合新闻正文、用户反馈和消息来源这三者的特征。该论文的数据集来自 Twitter 和微博,在微博场景中,“正文”指某个话题的讨论,“反馈”指参与者的回复,“源”则指回复的用户。
整个模型架构由两部分组成:
- Capture 模块:用于提取一篇正文下所有回复的文本信息,通过循环神经网络来聚合多个回复内容。
- Score 模块:通过构建用户关系网络并进行降维,计算得到用户表示 $s_i$ 和 $\hat{y}_i$。其中 $s_i$ 用于后续计算,$\hat{y}_i$ 也可用于单独的用户分析。
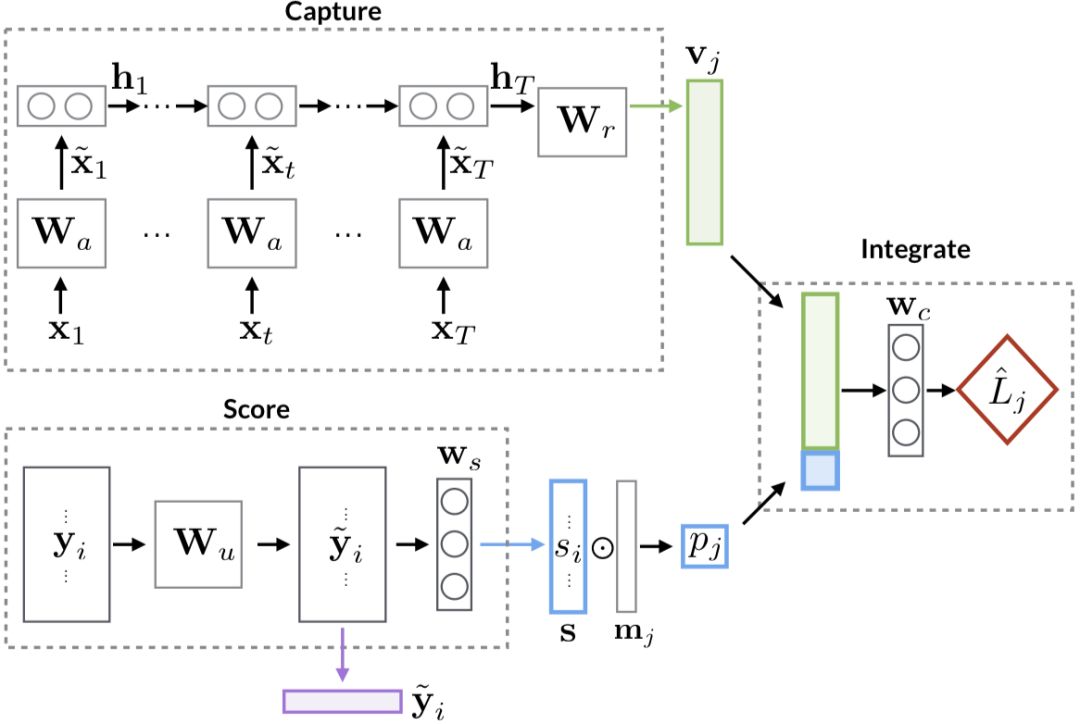
如上图所示,Capture 部分用来抽取文章和用户的低维表示。它使用一个 RNN 来抽取正文的向量表示 $v_j$。对于每个时间步 $t$ 的输入 $x_t$,由三部分构成:
$$x_t = (\eta, \Delta t, x_u, x_\tau)$$
其中 $\eta$ 表示订阅(或关注)的数量,$x_u$ 表示用户的全局特征,$x_\tau$ 是所有回复评论的文本特征。
Score 部分,作者基于用户之间共同参与话题的数量构建矩阵,然后进行 SVD 降维,获得用户的向量表示 $y_i$,接着通过一个全连接层变换:
$$\tilde{y}_i = \tanh(W_u y_i + b_u)$$
之后,通过一个掩码 $m_j$ 处理,仅筛选出与正文 $a_j$ 产生过交互的用户,将他们的 $\tilde{y}_i$ 向量求和平均,得到文章在该维度上的打分向量 $p_j$。
最后,将 Capture 模块得到的正文向量 $v_j$ 和 Score 模块得到的社交上下文向量 $p_j$ 进行拼接,得到最终的融合表示 $c_j$,并通过一个分类层得到预测概率 $\hat{L}_j$:
$$\hat{L}_j = \sigma(w_c^T c_j + b_c)$$
模型的损失函数是二分类交叉熵损失加上 L2 正则项:
$$\text{Loss} = -\frac{1}{N} \sum [L_j \log \hat{L}_j + (1 - L_j) \log(1 - \hat{L}_j)] + \frac{\lambda}{2} \|W_u\|^2$$
不得不说,作者巧妙地将基于用户参与内容的刻画和基于用户行为网络的刻画,二者所蕴含的信息都转化为文章的向量表示,并进行联合的端到端学习,这是一个很大的创新点。

这篇是中科院计算技术研究所的研究工作,发表在 AAAI 2016。
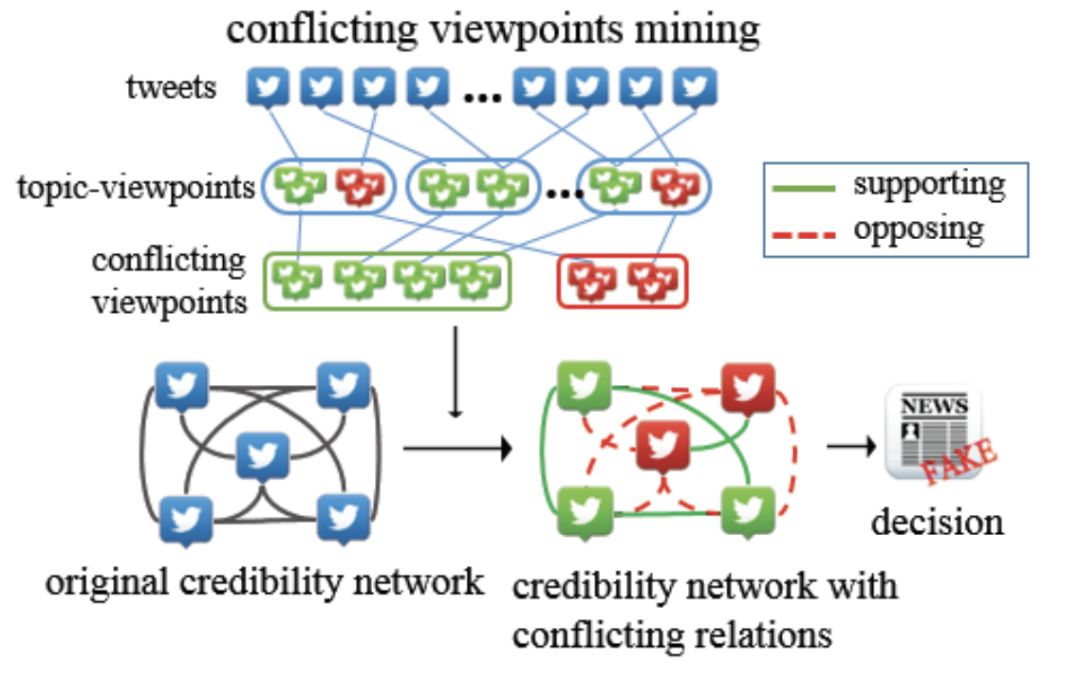
Step 1:通过主题模型进行冲突观点挖掘。
首先,根据用户发帖内容所表达的支持或反对立场,构建初始的可信度网络。作者假设每条推文都由一组混合的主题,以及对每个主题的多种观点组成。每一个“主题-观点”对的分布参数 $\phi_{kl}$ 服从狄利克雷分布:
$$\phi_{kl} \sim \text{Dir}(\beta)$$
其中 $k$ 表示主题维度,$l$ 表示观点维度。
- 对于每条推文 $t$,其主题分布 $\theta_t$ 也服从一个狄利克雷分布:$\theta_t \sim \text{Dir}(\alpha)$。
- 同样,对于每个可能的主题 $k$,其观点分布 $\psi_{tk}$ 也服从一个狄利克雷分布。
生成一条推文的过程是:先从以 $\theta_t$ 为参数的多项式分布中采样一个主题 $z_{tn}$,再从以 $\psi_{t z_{tn}}$ 为参数的多项式分布中采样一个观点 $v_{tn}$。因此,最终推文中词 $w_{tn}$ 的生成来自于以 $\phi_{z_{tn} v_{tn}}$ 为参数的多项式分布:
$$w_{tn} \sim \text{Mult}(\phi_{z_{tn} v_{tn}})$$
如果来自同一个主题下的不同“主题-观点”对之间的 Jensen-Shannon 距离(JSD,KL散度的一种对称变体)很大(超过设定阈值 $h$),则认为它们是冲突的。
具体冲突观点挖掘流程如下:
- 对新闻数据集建模,生成大量的“主题-观点”对。
- 比较同一主题下生成的不同观点对之间的 JSD 距离,建立冲突关系。
- 使用 Wagstaff et al. (2001) 提出的带约束的 K-means 算法,将每个主题下的观点聚合成两个彼此对立的簇。
Step 2:构建可信度网络并迭代学习。
根据主题模型,我们已经得到了参数 $\theta_t$(主题分布)和 $\psi_{tk}$(观点分布),可以计算推文 $t$ 在主题 $k$ 上持有观点 $l$ 的概率为:
$$p_{tk} = \theta_t \cdot \psi_{tk}$$
定义两条推文 $t_i$ 和 $t_j$ 之间的关联函数为:
$$f(t_i, t_j) = \frac{(-1)^a}{D_{JS}(p_{t_i k} \| p_{t_j k}) + 1}$$
其中 $D_{JS}$ 表示 Jensen-Shannon 距离。$w_{ij} = f(t_i, t_j)$ 构成了权重矩阵。
文中定义的可信度学习损失函数如下:
$$Q'(T) = \mu \sum_{i,j=1}^{n} W^{i,j} \left( \frac{C(t_i)}{\sqrt{D^{i,i}}} - \frac{C(t_j)}{\sqrt{D^{j,j}}} \right)^2 + (1-\mu) \| T - T_0 \|^2$$
其中 $T = \{C(t_1), ..., C(t_n)\}$,$C(t_i)$ 表示推文 $t_i$ 的可信度分值,是需要学习的参数。经过推导,可以得到每轮迭代 $k$ 的更新公式:
$$T(k) = \mu H T(k-1) + (1-\mu) T_0$$
具体的求导和网络收敛性证明可参考原论文。

论文首先通过数据分析发现,帖子内容、发布作者和所属主题三者与新闻的真假有很强的关联性。因此,作者将这三者融入一个深度扩散网络,并同时最小化三者的目标损失。
$$\min_{W} \mathcal{L}(T_n) + \mathcal{L}(T_u) + \mathcal{L}(T_s) + \alpha \cdot \mathcal{L}_{reg}(W)$$
模型通过学习显式特征和潜在特征来进行表示。潜在特征通过 GRU 的隐藏层和融合层得到:
# Fusion Layer:
x_n,i = σ(∑_{t=1}^{q} W_i h_i,t)
# Hidden Layer:
h_i,t = GRU(h_i,t-1, x_i,t; W)
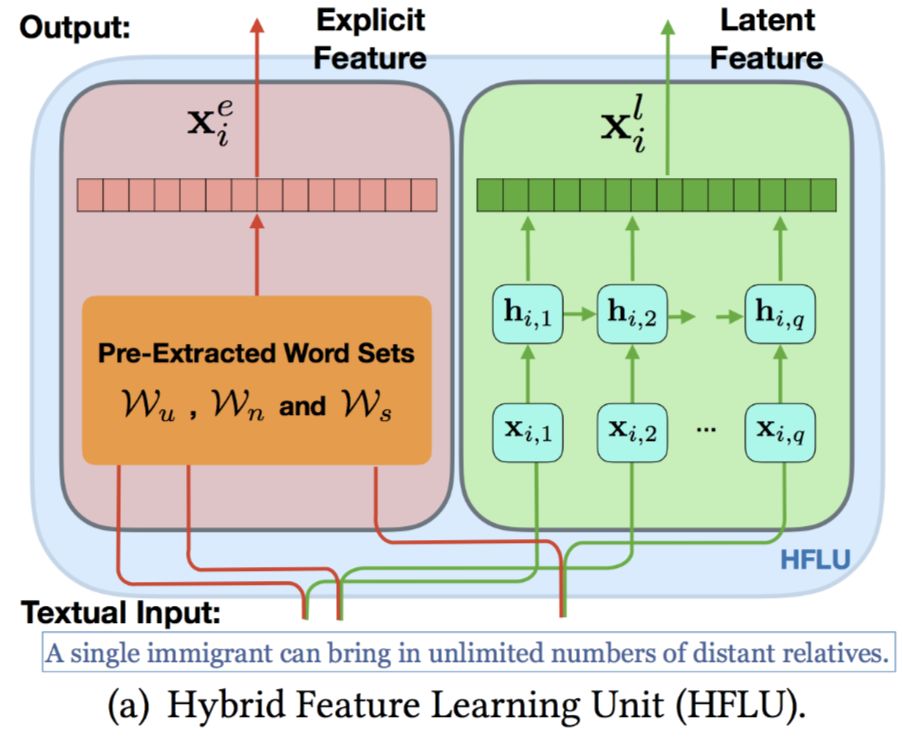
论文提出了一个 GDU(门控扩散单元),不仅可以学习帖子正文的表示,还可以同时对作者和主题进行建模。
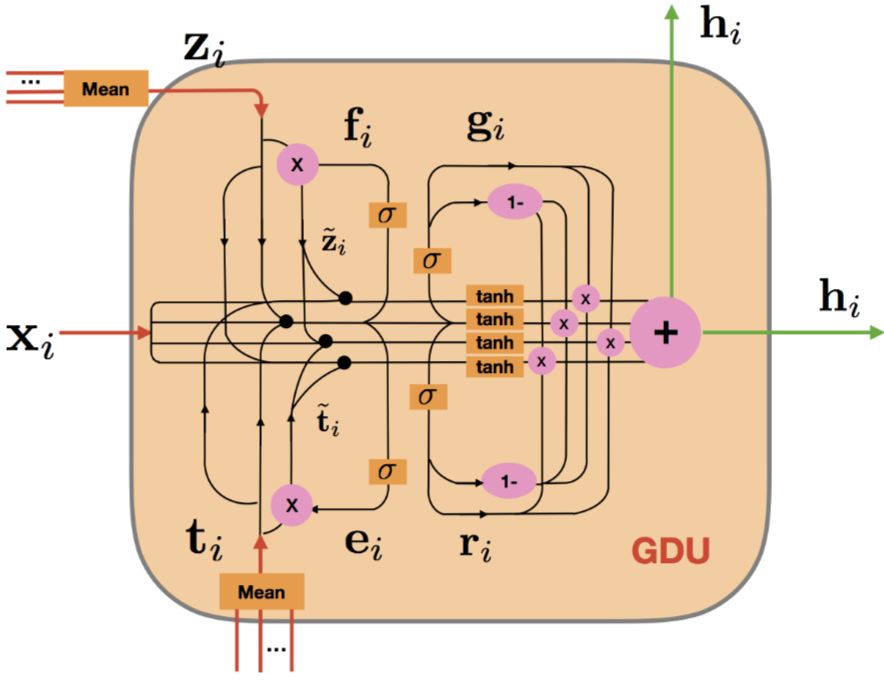
模型的输出层对新闻、用户和主题分别进行预测:
$$\begin{cases} y_{n,i} = \text{softmax}(W_n h_{n,i}) \\ y_{u,j} = \text{softmax}(W_u h_{u,j}) \\ y_{s,l} = \text{softmax}(W_s h_{s,l}) \end{cases}$$
其中,关于用户部分的损失 $\mathcal{L}(T_u)$ 形式如下(新闻和主题的损失形式类似):
$$\mathcal{L}(T_u) = - \sum_{u_j \in T_u} \sum_{k=1}^{K} \hat{y}_{u,j}[k] \log y_{u,j}[k]$$
最终的网络架构将新闻、用户和主题三者相互连接起来,形成一个复杂的扩散网络:
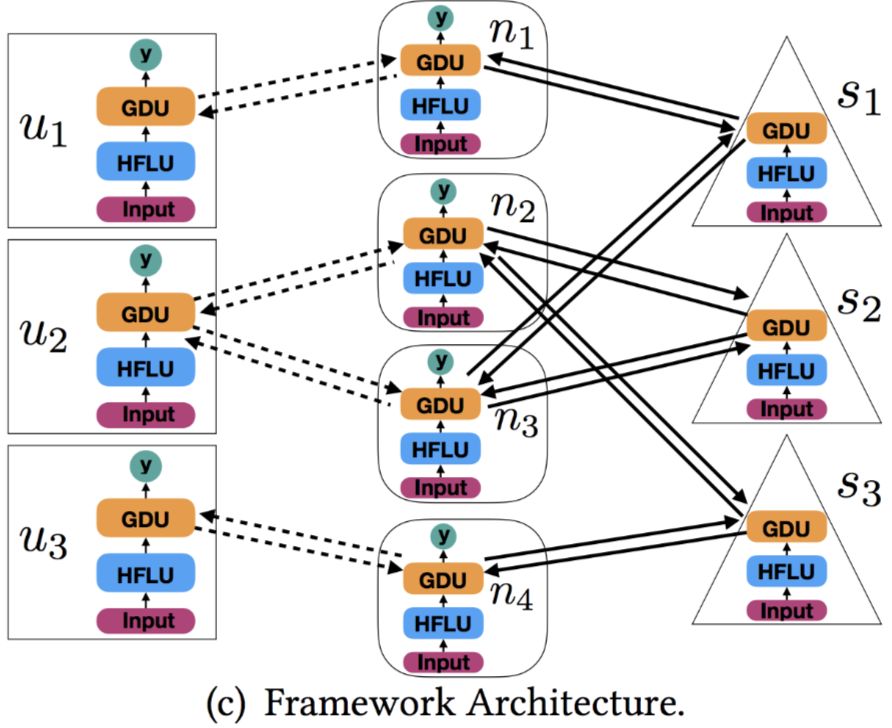
论文与其他方法进行了对比,结果表明该方法取得了优异的效果。整个方法的思想类似于图神经网络在虚假新闻检测上的应用。

这篇论文发表在 WSDM ‘19,个人认为创新性很高。它将发布者、新闻、社交网络用户,以及用户间的互动行为,构建成 5 个关联矩阵进行联合建模。
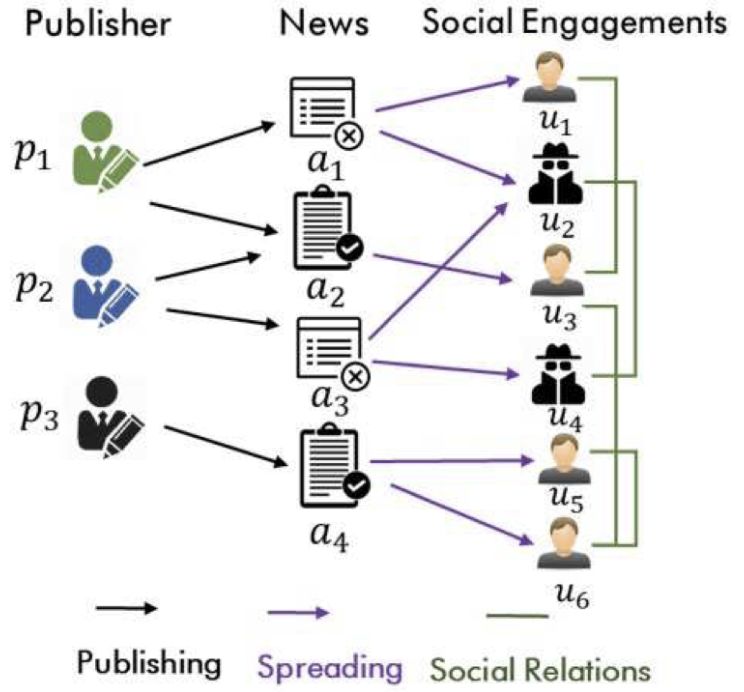
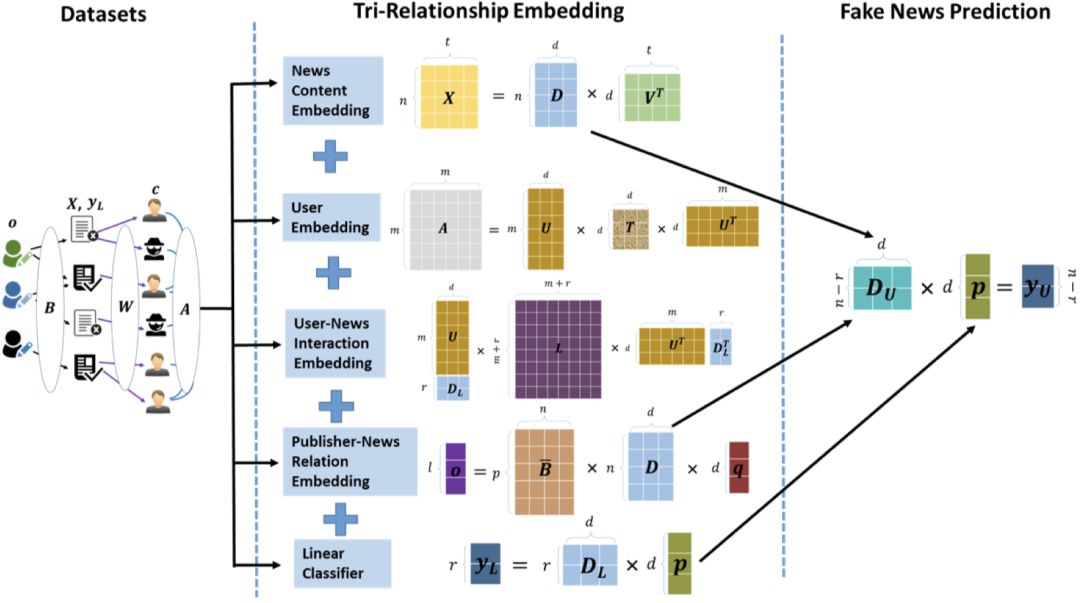
具体包括:新闻内容矩阵 $X$;用户社交关系矩阵 $A$;用户-新闻交互矩阵 $Y$;发布者-新闻关系矩阵 $B$;以及已标注新闻的标签向量 $y_L$。
对新闻内容矩阵 $X$ 和用户社交关系矩阵 $A$,采用非负矩阵分解(NMF)来学习潜在特征:
$$\min_{D, V \ge 0} \| X - D V^T \|_F^2 + \lambda (\|D\|_F^2 + \|V\|_F^2)$$
$$\min_{U, T \ge 0} \| Y \odot (A - U T U^T) \|_F^2 + \lambda (\|U\|_F^2 + \|T\|_F^2)$$
对用户-新闻交互矩阵 $Y$ 的分解,其目标是:让高可信度的用户更倾向于分享真实新闻,而低可信度的用户更倾向于分享虚假新闻。这通过一个带权重的目标函数实现:
$$
\min_{U, D_L \ge 0} \sum_{i=1}^{m} \sum_{j=1}^{r} W_{ij} \left[ c_i \left(1 - \frac{1+y_{L_j}}{2}\right) \| U_i - D_{L_j} \|_2^2 + (1-c_i) \left(\frac{1+y_{L_j}}{2}\right) \| U_i - D_{L_j} \|_2^2 \right]
$$
对发布者-新闻关系矩阵 $B$ 的分解,目标是基于新闻发布者的潜在特征 $q$ 来拟合其政治倾向等属性 $o$:
$$\min_{D \ge 0, q} \| e \odot (B D q - o) \|_2^2 + \lambda \| q \|_2^2$$
这里 $e$ 是一个哈达玛积(元素乘)矩阵,用于衡量误差。
最后,利用已标注新闻学到的特征 $D_L$ 来预测其标签 $y_L$:
$$\min_{p} \| D_L p - y_L \|_2^2 + \lambda \| p \|_2^2$$
将上述所有矩阵分解的目标和最终的预测目标整合起来,就得到了整体的目标函数:
$$
\min_{D,U,V,T \ge 0, p, q} \| X - D V^T \|_F^2 + \alpha \| Y \odot (A - U T U^T) \|_F^2 + \beta \cdot \text{tr}(H^T L H) \\
+ \gamma \| e \odot (B D q - o) \|_2^2 + \eta \| D_L p - y_L \|_2^2 + \lambda R
$$
具体的优化求解过程需要一定的数学基础,对此论文感兴趣的读者可以深入阅读原文。这种将多源异质信息通过矩阵分解统一在同一框架下的思想,在人工智能领域,尤其是社交大数据分析中非常具有启发性。
相关技术竞赛
Dean Pomerleau 和 Delip Rao 在 2017 年发起了“假新闻挑战赛”,旨在探索如何利用人工智能技术来对抗虚假新闻。
比赛地址:
http://www.fakenewschallenge.org/
该比赛的任务是立场检测。输入是一个新闻标题和一段正文内容,输出是正文内容对标题所持的立场:1)同意,2)反对,3)讨论,4)不相关。
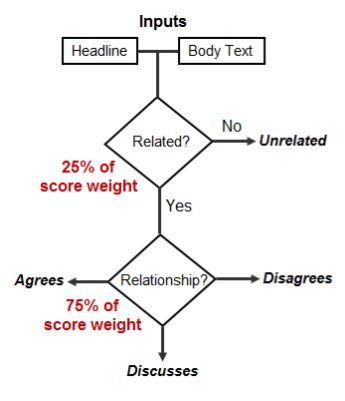
组委会认为,立场检测任务与假新闻检测场景强相关,因为仅仅判断相关与否过于简单。通过分析正文对标题内容的赞同与否,可以为真实性判断提供重要依据。当年的冠军方案采用了深度卷积神经网络和 GBDT 的混合模型。亚军则使用了多种特征(如 NMF、LDA、LSI、unigrams 等)加上多层感知机。
[Andreas Hanselowski, 2018] 这篇 COLING 论文对此次比赛前三名的方法进行了深入分析,并提出了改进方案,取得了该任务的 state-of-the-art 效果。
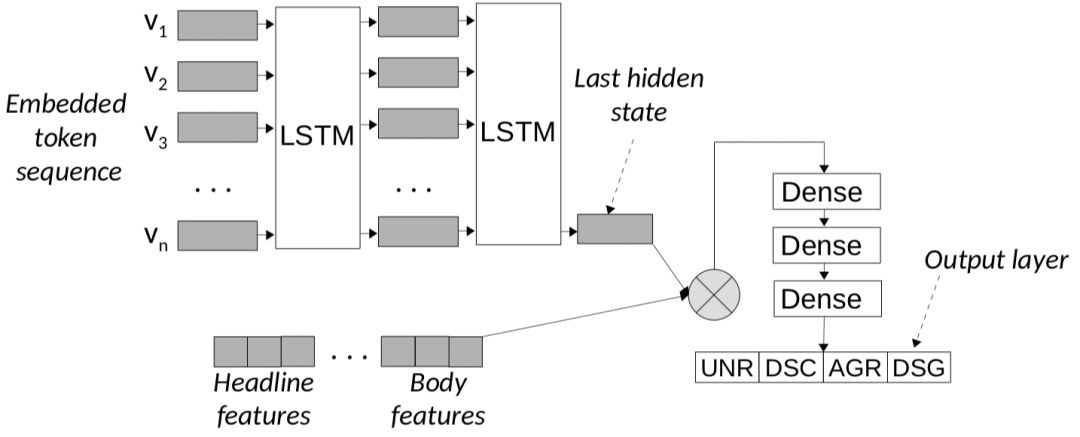
他们的框架利用 stackLSTM 来表征文本的深层语义信息,再融合标题和正文的特定特征,实验表明该框架在样本较少类别上的表现有显著提升。
参考文献
[1]. Yuyu Zhang, Hanjun Dai, Zornitsa Kozareva, Alexander J. Smola, Le Song. "Variational Reasoning for Question Answering with Knowledge Graph". arXiv preprint arXiv:1709.04071, 2017.
[2]. Zhiwei Jin, Juan Cao, Yongdong Zhang, and Jiebo Luo. "News Verification by Exploiting Conflicting Social Viewpoints in Microblogs". AAAI 2016.
[3]. Kai Shu, Suhang Wang, Huan Liu. "Beyond News Contents: The Role of Social Context for Fake News Detection". WSDM 2019.
[4]. Kai Shu, Amy Sliva, Suhang Wang, Jiliang Tang, Huan Liu. "Fake News Detection on Social Media: A Data Mining Perspective". SIGKDD 2017.
[5]. William Yang Wang. “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. ACL 2017.
[6]. Natali Ruchansky, Sungyong Seo, Yan Liu. "CSI: A Hybrid Deep Model for Fake News Detection". CIKM 2017.
[7]. Andreas Hanselowski, Avinesh PVS, Benjamin Schiller, Felix Caspelherr, Debanjan Chaudhuri, Christian M. Meyer, Iryna Gurevych. "A Retrospective Analysis of the Fake News Challenge Stance Detection Task". arXiv preprint arXiv:1806.05180, 2018.
[8]. Benjamin D. Horne, Sibel Adali. "This Just In: Fake News Packs a Lot in Title, Uses Simpler, Repetitive Content in Text Body, More Similar to Satire than Real News". ICWSM 2017.
虚假新闻检测是一个充满挑战且不断演进的研究领域,它融合了自然语言处理、社交网络分析、深度学习等多个方向的知识。希望本文梳理的技术脉络和论文解读,能为感兴趣的开发者或研究者提供一个有价值的入门指南。对于更深入的技术交流和资源共享,欢迎关注云栈社区的相关技术板块。
 发表于 2026-3-25 00:10:28
|
查看: 121|
回复: 0
发表于 2026-3-25 00:10:28
|
查看: 121|
回复: 0
