还在为Depth Anything、MoGe-2等强大模型搞不定透明物体而烦恼?
这篇论文解决了一个非常实际且棘手的问题:让现有的强大单目深度估计模型(如Depth Anything V3)能“看透”玻璃瓶、水杯等透明物体。它没有选择费力不讨好地重新训练深度模型,而是巧妙地用一个扩散模型作为“前端滤镜”,把透明区域“变”成几何一致的不透明图像,再交给现成的深度模型处理。这种“即插即用”的思路非常聪明,实验效果也相当扎实,在多个数据集上零样本超越了需要专门训练的模型。对于机器人抓取、3D重建等需要精确感知透明物体的应用,这无疑是个福音。
原论文信息如下:
论文标题:
SeeClear: Reliable Transparent Object Depth Estimation via Generative Opacification
发表日期:
2026年03月
发表单位:
未明确列出
原文链接:
https://arxiv.org/pdf/2603.19547v1.pdf
项目链接:
https://heyumeng.com/SeeClearweb/
想象一下,你让家里的扫地机器人去清理洒在地上的水,结果它一头撞上了旁边装着水的透明玻璃杯。或者,你戴上一副VR/AR眼镜,想拿起虚拟桌子上的一个玻璃瓶,结果手指直接穿了过去——因为系统“看”不到它。
这不是科幻,而是目前AI视觉系统面临的真实困境。以Depth Anything V3、MoGe-2为代表的顶尖单目深度估计模型,能精准感知不透明物体的远近和形状,但一遇到玻璃、水瓶、眼镜这些透明物体,深度图就常常变成一团乱麻,预测得忽深忽浅,甚至完全失效。
为什么?因为光在穿过透明物体时会折射、反射,你看到的其实是扭曲、重叠的背景,而非物体本身的表面。这彻底破坏了计算机视觉中“外观对应几何”的基本假设,让模型“看”了个寂寞。
今天要聊的这篇论文《SeeClear: Reliable Transparent Object Depth Estimation via Generative Opacification》,就瞄准了这个“盲区”。它提出了一个极其聪明的思路:既然深度模型看不懂透明,那我们能不能在输入图片之前,先把透明物体“变”成不透明的?
就像一个魔法滤镜,把玻璃杯“P”成一个颜色均匀、形状不变的陶瓷杯,再扔给Depth Anything去算深度。而且,最关键的是,这个“滤镜”即插即用,不需要对背后的深度模型做任何改动或重新训练!
下面,就让我们一层层揭开这个名为SeeClear的“显形魔法”的秘密。
透明物体,深度估计的“盲区”
单目深度估计(Monocular Depth Estimation)是一项让AI从一张2D图片中推测出每个像素点距离摄像头有多远的技术。它在机器人导航、3D重建、VR/AR交互等领域是基石般的存在。
现有的深度模型,无论是基于CNN(卷积神经网络)还是Transformer,其强大的背后都依赖于一个关键假设:物体表面的外观(颜色、纹理、明暗)与其几何形状(深度)存在某种稳定的对应关系。例如,通过阴影可以判断凹凸,通过纹理变化可以感知远近。
但透明物体是这个规则的“bug制造者”。一个玻璃杯的表面本身几乎没有颜色和纹理,你看到的是它背后扭曲变形的桌布、墙壁。对于模型来说,这就像面对一个“隐形人”,你看到的只是他身后不断晃动的背景,根本无法判断“他”的轮廓和位置。
过去解决这个问题的主流思路是:收集大量透明物体的RGB-D(彩色图+深度图)数据,然后去微调(Fine-tune)或者专门训练一个深度模型。但这条路有几个大坑:
- 数据难搞: 大规模、高质量的透明物体真实深度数据极难获取。用传感器(如Kinect)测透明物体,深度值本身就是错的。
- 模型绑定: 训好的模型只适配特定架构。今天Depth Anything V3效果好,我训一个;明天出了V4,难道再从头训一遍?成本太高。
- 顾此失彼: 专门为透明物体优化的模型,在不透明物体上的表现可能反而不如通用模型。
SeeClear的团队换了个角度思考:深度模型在不透明物体上已经很强了,何不把问题从“让模型理解透明”变成“让输入图片没有透明”? 只要我能生成一张图,里面的透明物体被替换成了几何形状完全一致的不透明版本,那么现有的任何深度模型拿过来就能直接用!

图1:SeeClear的核心思想示意图。给定一张含有透明物体(如玻璃瓶)的输入图片,方法首先生成一个几何一致的不透明版本(看起来像个棕色瓶子),然后将这张“处理过”的图片送入现成的深度模型,最终得到准确的深度图。
化“透”为“实”:SeeClear的核心魔法
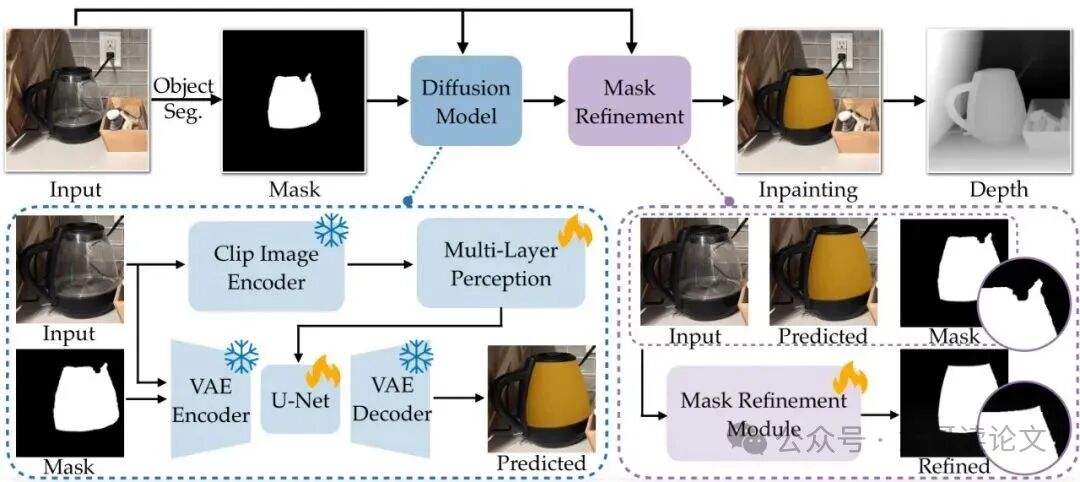
图2清晰地展示了SeeClear的整个工作流程。它像一个精心设计的流水线,主要由三个核心模块组成,我们来逐一拆解:
第一步:定位“隐形人”
要想“处理”透明物体,首先得知道它在哪。SeeClear采用了粗到精的分割策略:先用一个专门分割透明物体的模型Trans4Trans大致框出位置,再用强大的通用分割模型SAM 3(Segment Anything Model 3)进行精细分割,得到一个二值掩膜(Mask),就像给“隐形人”描了个边。
第二步:生成“实体替身”(核心魔法)
这是整个方法最精髓的部分。目标是在掩膜区域内,把原本透明的外观,替换成一个几何形状保持一致、材质变为不透明(如均匀漫反射)的新图像。这本质上是一个条件图像生成任务。
团队选择了潜在扩散模型(Latent Diffusion Model, LDM)来完成这个任务。简单理解,LDM是一种强大的生成模型,它通过在压缩后的图像表示(潜空间)里逐步去噪来生成图像。
为了让生成的不透明物体“长得像”原来的透明物体,需要给模型明确的“条件”:
- 空间条件: 把第一步得到的分割掩膜下采样后,和带噪的潜变量、编码后的原图拼接在一起,输入给去噪网络。这等于告诉模型:“请在这个区域里作画,别画到外面去”。
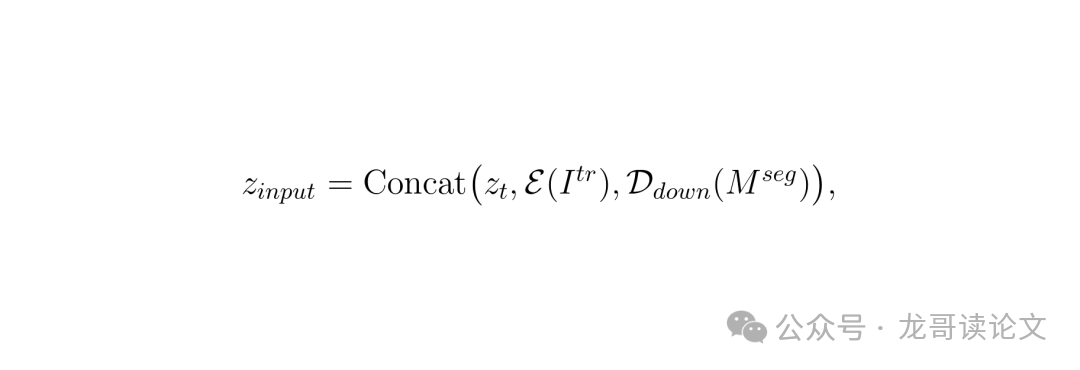
- 语义条件: 需要一个信息来告诉模型“要生成什么物体”。直接用透明物体的深度图或法线图?不行,这些对于透明物体本身就不准。SeeClear用了一个巧招:使用CLIP(Contrastive Language-Image Pre-training)的图像编码器来提取原图的类别标记(class token)作为条件。CLIP的语义理解能力很强,尽管玻璃杯和棕色陶瓷杯外观差异巨大,但CLIP能知道它们都属于“杯子”这个语义类别,从而引导生成正确的形状。
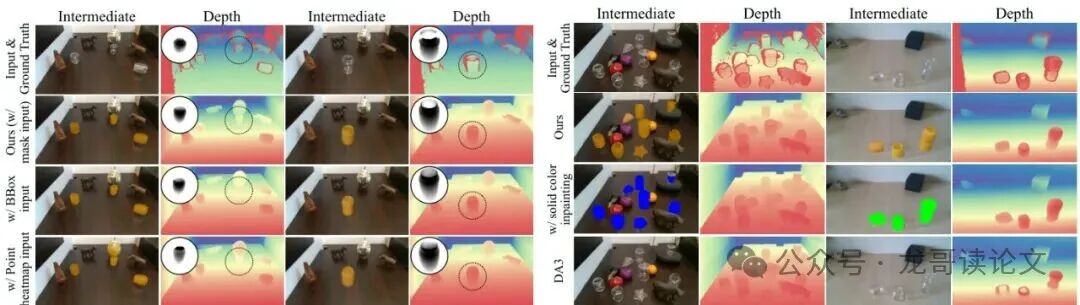
图3:精准的掩膜分割至关重要。如果用简单的边界框(BBox)或者点提示(Point)来替代掩膜,生成的不透明物体形状会走样,导致深度预测失败。

图4:CLIP的语义引导效果更好。相比另一个视觉模型DINOv2,CLIP的类别标记能让生成的不透明物体形状更准确,深度预测误差更小。
第三步:无缝融合与深度推理
扩散模型生成的是不透明物体区域的图像。直接把它“贴”回原图,可能会因为掩膜边界不精确或生成图像的背景色差而产生生硬的接缝。为此,SeeClear设计了一个轻量级的掩膜优化模块(Mask Refinement Module, MRM)。
MRM会预测一个软混合掩膜,在物体边界处是平滑过渡的(值在0到1之间),而不是非0即1。这样,最终合成的图像 = 生成的不透明区域 软掩膜 + 原始图像 (1 - 软掩膜),实现了无缝融合。
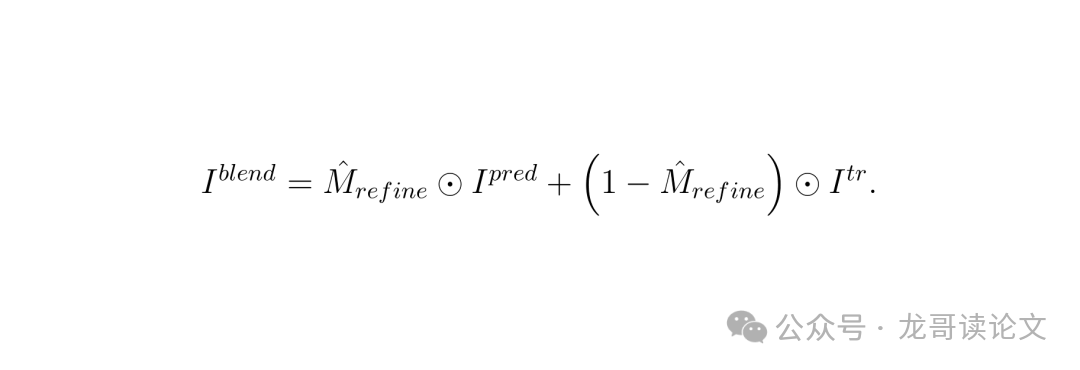
得到这张“修复”后的图片后,任务就完成了最困难的部分。现在,你可以把它直接喂给任何一个现成的、强大的单目深度估计模型(如Depth Anything V3, MoGe-2),像处理普通图片一样,得到准确且稳定的深度图!

数据为基:构建39.6万对透明-不透明图像库
要教会扩散模型完成“透明转不透明”这个魔法,需要大量的“教材”——也就是成对的透明物体图片和它对应的、几何完全相同的不透明物体图片。现实中几乎不可能拍摄到这样的配对数据。
于是,研究团队转向了合成数据。他们利用3D建模软件Blender,精心构建了一个名为SeeClear-396k的大规模数据集。这个名字里的“396k”就代表了数据量:39万6千对渲染图像!
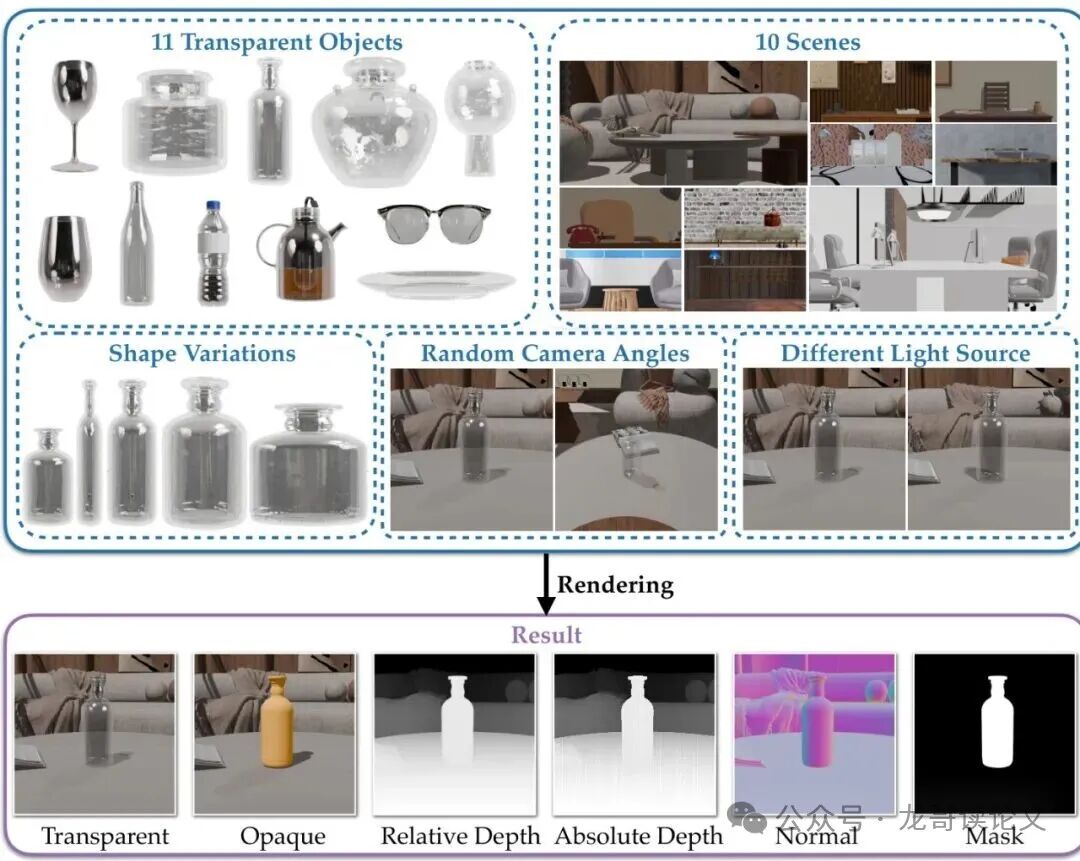
图5:数据集的构建过程。对于同一个物体-场景配置,用完全相同的相机、光照和几何,渲染两次:一次使用玻璃材质(透明,I_tr),一次使用固定的漫反射材质(不透明,I_op)。这样就得到了完美配对的训练数据。
为了覆盖真实世界中的各种挑战,他们不仅收集了常见的玻璃杯、瓶子,还包括了眼镜、透明储物盒等11类物体,放置在10个不同的室内场景中。并通过系统性地采样不同的摄像机角度、光照条件、物体形变,极大地丰富了数据的多样性。这确保了训练出的模型能够泛化到各种未曾见过的透明物体和复杂场景。
实验为证:零样本超越专用模型
理论很美好,效果怎么样?SeeClear在合成(TransPhy3D)和真实世界(ClearGrasp)两个透明物体深度估计标准数据集上进行了全面测试,并对比了各类SOTA方法。
这里有几个关键亮点:
- 零样本 vs. 微调: 大多数专用方法(如DKT)在测试集上进行了微调。而SeeClear没有使用任何测试集数据训练,属于“零样本”评估。即便如此,它在大多数指标上仍然与微调后的DKT打得有来有回,甚至在部分指标上实现超越。
- 即插即用的威力: 论文将SeeClear作为前端,分别接入两个强大的现成深度模型:Depth Anything V3 (DA3) 和 MoGe-2。结果令人振奋:接入SeeClear后,两个模型在透明物体上的深度估计精度都得到了显著提升。例如,在ClearGrasp数据集上,MoGe-2的均方根误差(RMSE)从56.83mm大幅降低到26.62mm,性能翻了一倍还多!
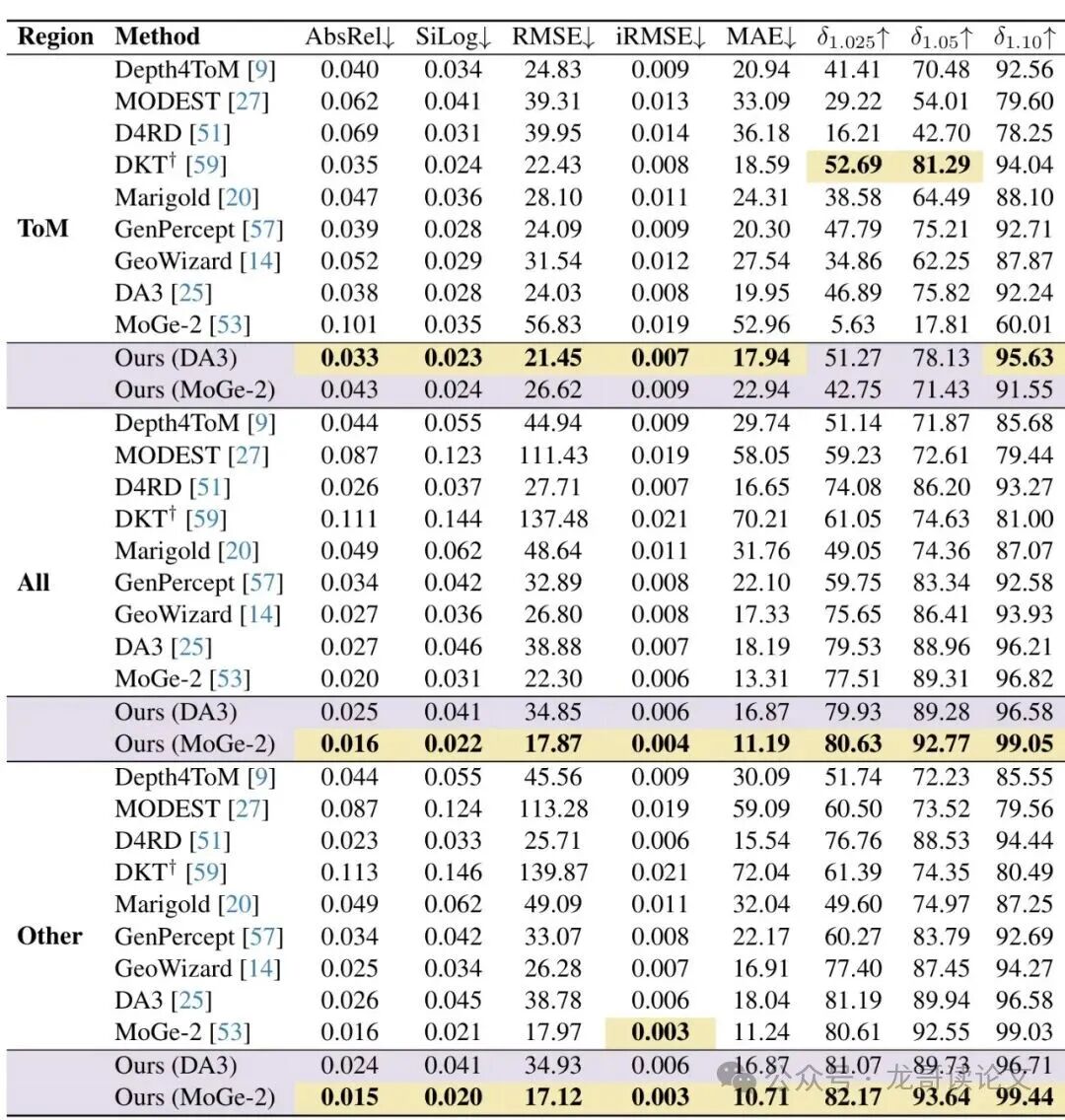
表1:在真实世界ClearGrasp数据集上的定量对比。Ours (DA3) 和 Ours (MoGe-2) 分别代表用SeeClear处理后再用对应深度模型。可以看到,在透明物体区域(ToM),SeeClear结合DA3超越了大多数基线,结合MoGe-2则带来了巨大的性能飞跃。在全图(All)和其他区域(Other),性能也保持领先或相当,说明没有损害对不透明物体的估计。
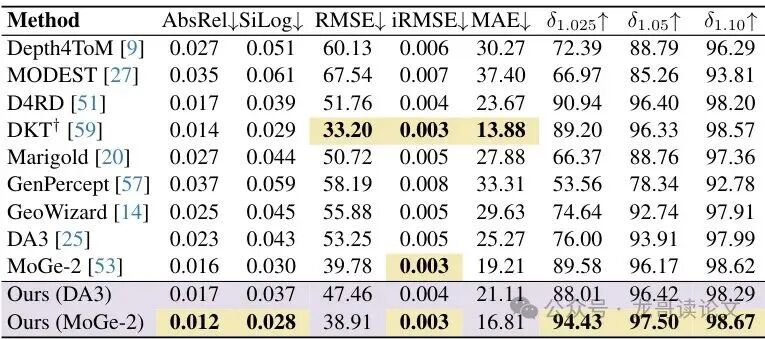
图6:在合成数据集TransPhy3D上的结果,SeeClear同样全面提升了DA3和MoGe-2的性能。
- 完胜通用深度模型: 对比Marigold、GenPercept等同样基于扩散模型的通用深度估计方法,SeeClear(同样是零样本)在透明物体深度估计上展现出了明显优势,证明了其专门为解决透明问题而设计的有效性。
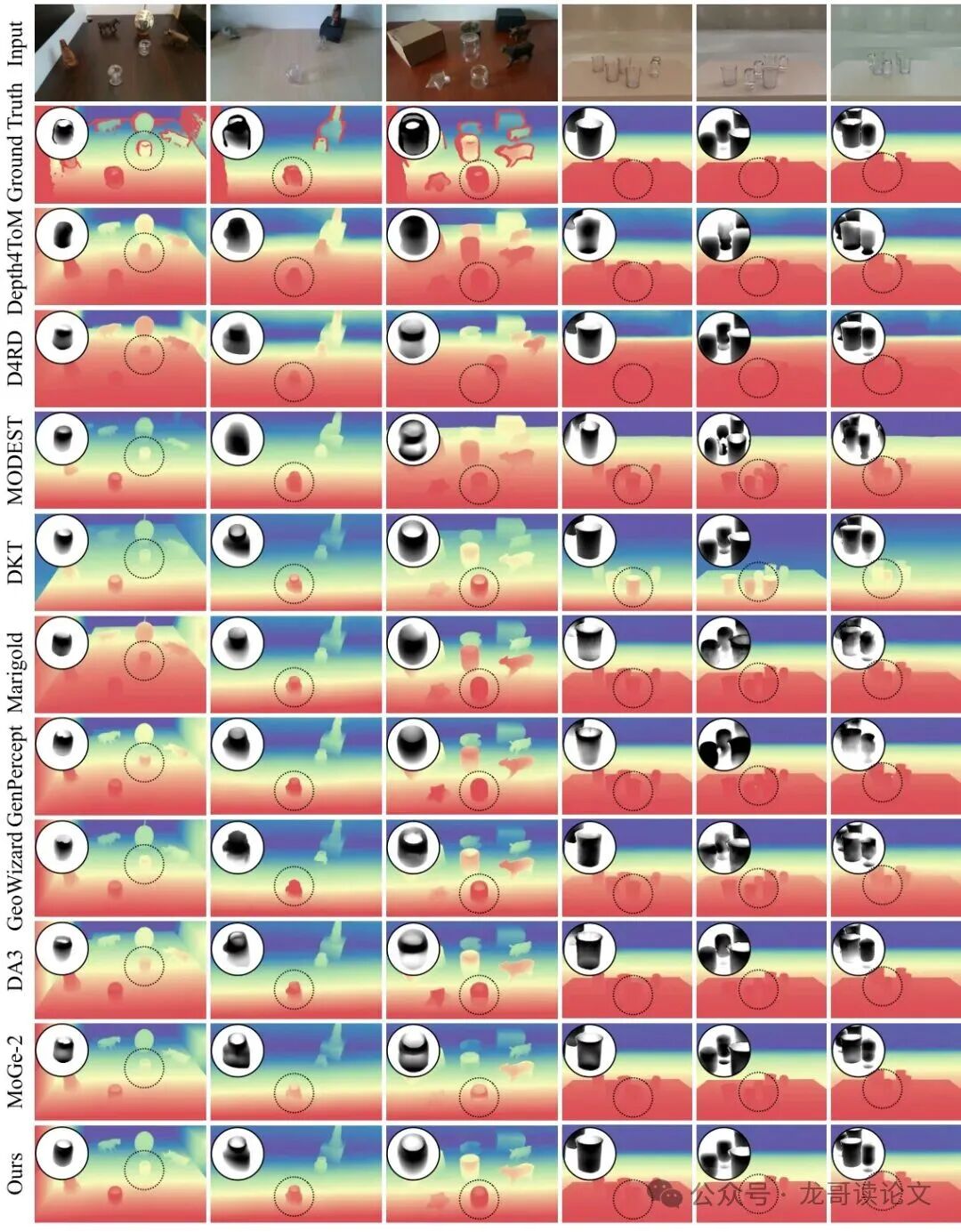
图7:看一眼定性结果就更直观了。左边三列是真实场景,右边三列是合成场景。其他方法预测的深度图在透明物体区域(红圈内)要么是半透明的(颜色深浅不一,像能看到背后),要么形状完全错误。而SeeClear(最后一行)生成的深度图,清晰地勾勒出了杯口、瓶身的轮廓,深度值均匀一致,准确地反映了物体本身的表面。
不只是瓶子:复杂场景下的稳定表现
实验室数据好,不代表在“野外”也行。论文花了大量篇幅展示SeeClear在更加复杂、多样的真实场景(In-the-Wild)下的表现,这些场景包含了更多挑战:
- 多个透明物体相互遮挡
- 内部装有液体或其他不透明物体
- 形状超出训练分布(OOD)
- 透明与不透明材料混合


图8 & 图9:展示了多达14行不同的复杂场景对比。其他方法普遍存在的问题是“半透明性”(Translucency),即深度图在透明物体区域内颜色不均,这反映了模型无法将物体表面作为一个整体来感知。而SeeClear(每张图的最后一行)在所有场景中都成功地将透明物体“实体化”,恢复了清晰的物体边界和连贯的表面深度,即使在遮挡、复杂内部结构的情况下也表现稳定。

展望未来:从静态图像到动态世界
SeeClear为解决透明物体感知这一长期难题提供了一个非常优雅且实用的思路。它的“即插即用”特性意味着,未来任何新的、更强大的深度估计模型出现,都可以几乎无成本地获得处理透明物体的能力。
当然,这项工作也打开了新的想象空间和挑战:
- 视频与动态场景: 目前方法处理单张图片。在视频中,如何保证连续帧之间透明物体深度预测的时空一致性?这对于机器人抓取、自动驾驶等实时应用至关重要。
- 更极端的透明: 对于完全无色、像空气一样几乎不可见的玻璃(如干净的平板玻璃),分割模型可能首先就无法准确定位它。
- 与其他模态结合: 是否可以结合多视角信息、或触觉等传感器,进一步提升在极端情况下的鲁棒性和精度?

常见问题解答
下面是对于一些可能问题的解答:
这篇论文解决的核心问题是什么?
它解决了现有单目深度估计模型在透明物体上失效的问题。通过一个“生成式不透明化”的前端处理模块,将图片中的透明区域转换成几何一致的不透明区域,从而让任何现成的深度模型都能准确估计透明物体的深度,无需重新训练。
透明物体的深度估计为什么这么难?
核心在于光的折射和反射破坏了计算机视觉中的“光度一致性”假设。模型无法从透明物体扭曲、重叠的背景外观中,可靠地推断出其自身表面的几何形状。这好比让你通过一个哈哈镜去看后面物体的位置,很难判断镜子本身在哪里。
文中的扩散模型在这里起什么作用?
扩散模型在这里扮演“材质转换器”的角色。它以原透明图像和物体掩膜为条件,在潜在空间中学习生成一个全新的图像。这个新图像在掩膜区域内,物体的形状和原物体一致,但材质从不透明的漫反射材质(如均匀的陶土)替代了原来的透明玻璃材质,移除了折射干扰。
技术方案评析
论文创新性:★★★★★
将“透明深度估计”问题巧妙地重构为“图像材质编辑”问题,提出了“生成式不透明化”这一核心概念,并设计了一套完整的、即插即用的前端处理流程。思路新颖且非常实用,避开了重新训练深度模型的沉重负担。
实验合理度:★★★★☆
实验设计全面,在合成和真实数据集上与众多SOTA方法进行了详尽的定量和定性对比。消融实验系统地验证了各模块(掩膜、CLIP条件、LPIPS损失、MRM)的必要性。美中不足是部分对比方法(如DKT)在测试集上微调了,而SeeClear是零样本,这种对比虽能体现泛化性,但严格来说不算完全公平的“同一起跑线”比较。好在论文也补充了在其他数据集上的零样本对比。
学术研究价值:★★★★★
为透明物体感知这一经典难题提供了一个全新的解决范式。其“前端适配器”的思路具有很高的启发价值,可推广到其他因材质、光照等导致模型失效的特殊视觉任务中。构建的大规模配对数据集SeeClear-396k也将是该领域的重要资源。
稳定性:★★★★☆
在论文展示的大量复杂真实场景中表现稳定,能较好地处理遮挡、内部物体等复杂情况。但其性能上限依赖于前端分割模型(SAM 3)的准确性,如果无法正确分割出透明物体,整个流程就会失败。对于极难分割的透明物体(如干净玻璃板),稳定性会下降。
适应性以及泛化能力:★★★★☆
方法本身对深度模型骨架无要求,适应性强。在已见的各种透明物体类型和室内场景中泛化能力优秀。但对于野外极端环境(如强反射、雨中车窗)、或非常规透明材质(如透明软胶)的泛化能力还需进一步验证。
硬件需求及成本:★★★☆☆
需要依次运行分割模型、扩散模型(虽然用了10步快速采样)、掩膜优化模块和深度模型。推理链较长,尤其是扩散模型部分计算开销较大,难以在资源有限的边缘设备(如手机、嵌入式机器人)上实时运行。属于“效果好但有点吃硬件”的类型。
复现难度:★★☆☆☆
论文尚未提供完整开源代码。虽然方法框架描述清晰,但涉及多个复杂模块(扩散模型训练、数据集构建)的细节实现,且需要396k的配对数据集进行训练,复现门槛较高。
产品化成熟度:★★★☆☆
在特定场景下(如室内机器人分拣透明容器、AR中虚拟物体与真实玻璃交互)已展现出实用潜力。但受限于推理速度和对分割精度的依赖,离大规模、高鲁棒性的产品化部署(如自动驾驶中感知挡风玻璃和车窗)还有一段距离,需要进一步优化 pipeline 效率和在极端 case 下的稳定性。
可能的问题:
方法性能严重依赖于第一步透明物体分割的准确性。对于难以分割的透明物体,整个系统会失效。此外,目前的“不透明化”是生成一个 diffuse 材质,忽略了透明物体本身可能具有的复杂表面纹理(如磨砂玻璃、印花),这可能会导致深度估计在某些细节上仍有偏差。
参考文献
[1] Wang, Xiaoying, et al. "SeeClear: Reliable Transparent Object Depth Estimation via Generative Opacification." arXiv preprint arXiv:2603.19547 (2026).
[2] 项目主页: https://heyumeng.com/SeeClearweb/
[3] 论文原文: https://arxiv.org/pdf/2603.19547v1.pdf
*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨。
对计算机视觉与AIGC交叉领域感兴趣?想了解更多类似的前沿技术解读和实战资源?欢迎到 云栈社区 的人工智能板块参与讨论,或探索开源实战板块,发现更多有趣的项目和代码。
 发表于 2026-3-25 01:01:24
|
查看: 180|
回复: 0
发表于 2026-3-25 01:01:24
|
查看: 180|
回复: 0
