如果你经常与 OpenClaw 进行深入的技术对话,可能会对一种情况感到熟悉又烦躁。
明明已经详细讨论过的项目背景、目录结构或命名规则,在多轮对话之后,它似乎“失忆”了。当你让它继续修改某个文件,它可能像初次接触任务一样,重新索要上下文;当你希望它延续之前的思路时,它的回答又容易偏离轨道。最终,最疲惫的往往不是 AI 模型,而是需要不断重复背景信息的开发者。
这种现象并不新奇,根源在于 AI 模型的上下文窗口限制。随着对话轮次增加,旧信息要么被新内容挤出窗口,要么在压缩过程中丢失了关键细节——尤其是那些定义清晰但对后续推理至关重要的“细枝末节”。
OpenClaw 的开发团队显然意识到了这个痛点,最近推荐了一个实用的开源解决方案:lossless-claw。其命名直指核心目标——尽可能“无损”地保留对话上下文。
它的设计思路颇为巧妙,并非简单粗暴地将所有历史聊天记录塞回模型提示词(那样会迅速耗尽 Token 预算),而是采用了另一套策略:先将每条消息持久化存储到 SQLite 数据库中,再将较早的消息逐步整理成结构化的树状摘要。
你可以将其理解为一种项目工作笔记的智能管理方式。
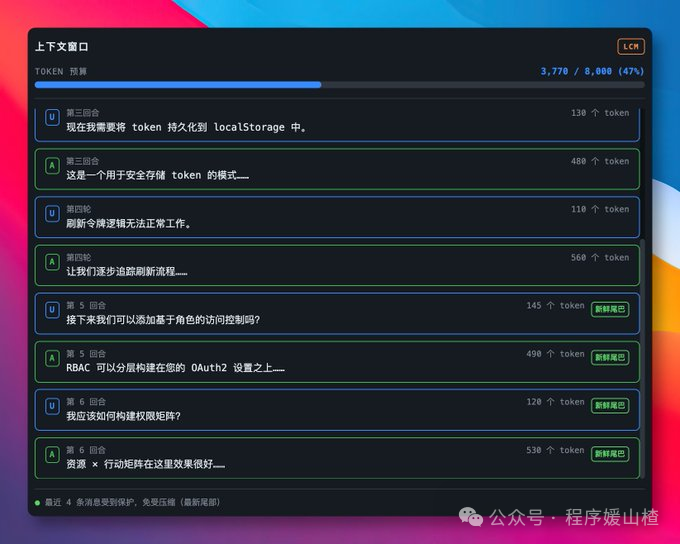
最新的对话内容保持原始状态,便于即时调用;而更早的讨论,则不会被直接丢弃,而是按照主题和逻辑层级进行归纳与折叠。这样,模型既不会被海量的历史记录压垮提示词长度,也不至于彻底遗忘之前达成共识的重要信息。
更有价值的是,这个插件不仅解决了“存储”问题。
为了确保 AI 在需要时能准确找回丢失的上下文细节,lossless-claw 还为其配备了几种专门的检索工具,例如 lcm_grep 和 lcm_describe。前者类似于在聊天历史中进行精准的关键词搜索,后者则适合快速概览某段对话记录的核心内容。简单来说,它在为模型创建摘要以节省空间的同时,又提供了一把可以随时回溯查阅原始档案的钥匙。
这一点至关重要。许多所谓的“记忆增强”方案,最终只是将过往内容压缩成一段模糊的总结。问题在于,过度概括的摘要很容易抹平项目中那些具有实际指导意义的细微约定或经验教训。例如,某个函数为何不能轻易改动、某个接口之前曾遇到过什么兼容性问题,这类信息一旦丢失,AI 在后续协作中很可能会一本正经地重复过去的错误。
相比之下,lossless-claw 的理念更贴近一种可靠的工程实践:用摘要来管理信息流,用原始记录作为回溯查证的保障。
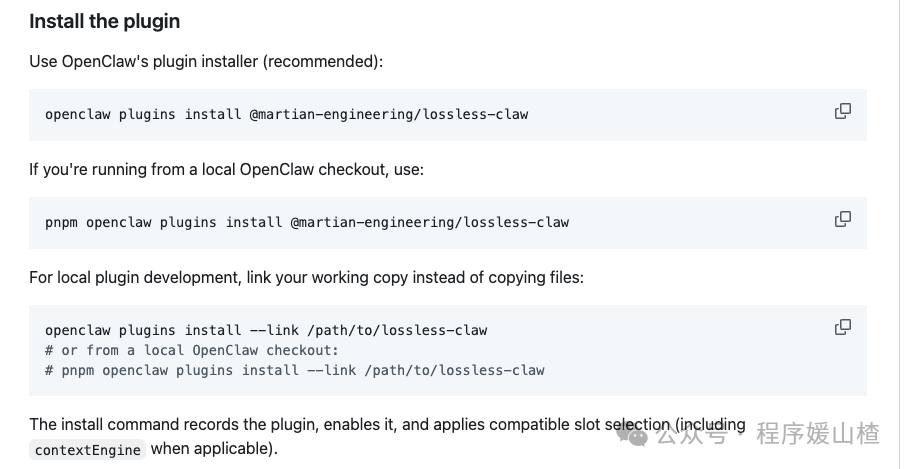
安装过程也足够简便。官方推荐的方式基本通过一条命令即可集成,并且支持参数自定义,例如设置保留最近多少条消息不被压缩、对话长度达到什么阈值时开始触发整理逻辑。这种可调性非常必要,因为不同开发者的工作流差异巨大:有人倾向于短平快的问答,有人则真正依赖 AI 进行长周期的项目开发,对“记忆”的策略需求自然不能一概而论。
实际上,这类工具所应对的,已经不仅仅是“AI 健忘”这个表层问题,它反映了开发者正将 AI 应用于更复杂、更长期的真实任务中。
早期,我们可能只是向 AI 提问或生成一段代码,上下文丢失的影响有限。但现在,越来越多的人开始让 AI 深度参与持续迭代的项目,例如阅读代码仓库、修改功能模块、接着前一天的工作进度继续推进。在这种场景下,持久化的记忆能力就不再是锦上添花的体验优化,而是直接影响工具可用性的基础设施。
一言以蔽之,一个总需要你反复交代背景的 AI,不像一个默契的搭档,更像第一天入职、对一切都很陌生的实习生。
因此,如果你正在使用 OpenClaw,或者正在探索其他 AI 编程助手,并且深受上下文限制的困扰,那么 lossless-claw 这款 开源插件 确实值得尝试。它或许不能彻底根治“遗忘”,但至少提供了一种更工程化、也更贴近现实需求的处理思路:不要指望模型天生拥有完美的记忆力,不如先为它搭建一个可靠的外部记忆系统。
很多时候,AI 能否顺畅地融入你的工作流,不仅取决于它的推理能力,更取决于它“记得”多少。关于该插件的更多安装细节与配置选项,可以参考其项目文档。
GitHub 地址:martian-engineering/lossless-claw
如果你对这类提升开发效率的 AI 工具和实践感兴趣,欢迎来 云栈社区 与更多开发者交流探讨。
 发表于 2026-3-25 00:55:09
|
查看: 313|
回复: 0
发表于 2026-3-25 00:55:09
|
查看: 313|
回复: 0
