做推荐系统,向量数据库就是整条业务链路的命根子。线上高并发场景下,它但凡抖一下,接口超时、用户流失、营收跳水,全是分分钟的事。
但最近,我们就踩了个连环坑:高并发查询场景下,planparserv2.HandleCompare 函数出现空指针异常,直接导致 Proxy 组件频繁 panic 重启。升级后 bug 没了,查询性能却直接腰斩,延迟飙升,晚高峰线上告警直接炸穿。
最后,我们从监控到慢查询,再到源码级根因定位,终于把服务拉回了满血状态,稳定性和并发能力也提了一个量级。以下是完整复盘经历。
空指针异常影响推荐表现
先给大家报一下我们的业务背景。我们用 Milvus 作为向量检索引擎,主要用于承载线上推荐系统的实时相似性搜索。向量规模为 千万级,平均每个向量维度是 768,使用 16 个 QueryNode 承载数据,每个 Pod 的 CPU/内存 Limit 为 16核/48G。
在使用 Milvus 2.2.16 版本期间,我们遇到了一个严重的稳定性问题:并发查询时 planparserv2.HandleCompare 出现空指针异常(nil pointer),导致 Proxy 组件频繁 panic 重启。这个 Bug 在高并发场景下极易触发,严重影响了线上推荐服务的可用性。
以下是线上 Proxy 组件 panic 时的实际错误日志:
[2025/12/23 10:43:13.581 +00:00] [ERROR] [concurrency/pool_option.go:53] ["Conc pool panicked"]
[panic="runtime error: invalid memory address or nil pointer dereference"]
[stack="...
github.com/milvus-io/milvus/internal/parser/planparserv2.HandleCompare
/go/src/github.com/milvus-io/milvus/internal/parser/planparserv2/utils.go:331
github.com/milvus-io/milvus/internal/parser/planparserv2.(*ParserVisitor).VisitEquality
/go/src/github.com/milvus-io/milvus/internal/parser/planparserv2/parser_visitor.go:345
...
github.com/milvus-io/milvus/internal/proxy.(*queryTask).PreExecute
/go/src/github.com/milvus-io/milvus/internal/proxy/task_query.go:271
github.com/milvus-io/milvus/internal/proxy.(*taskScheduler).processTask
/go/src/github.com/milvus-io/milvus/internal/proxy/task_scheduler.go:455
..."]
panic: runtime error: invalid memory address or nil pointer dereference [recovered]
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x8 pc=0x2f1a02a]
goroutine 989 [running]:
github.com/milvus-io/milvus/internal/parser/planparserv2.HandleCompare(...)
/go/src/github.com/milvus-io/milvus/internal/parser/planparserv2/utils.go:331 +0x2a
github.com/milvus-io/milvus/internal/parser/planparserv2.(*ParserVisitor).VisitEquality(...)
/go/src/github.com/milvus-io/milvus/internal/parser/planparserv2/parser_visitor.go:345 +0x7e5
从堆栈可以清晰看到,panic 发生在 Proxy 组件执行查询任务(queryTask.PreExecute)时,调用链路为 taskScheduler.processTask → queryTask.PreExecute → planparserv2.CreateRetrievePlan → planparserv2.HandleCompare,最终在 HandleCompare 函数中触发了空指针解引用(SIGSEGV)。该问题在并发查询场景下随机出现,导致 Proxy Pod 反复崩溃重启。
为了从根本上解决这一问题并获得新版本的性能优化,我们决定将 Milvus 升级到 2.5.16 版本。
升级前的备份 —— 使用 Milvus-Backup
在执行任何升级操作之前,数据备份是第一要务。我们选择了官方推荐的 milvus-backup 工具进行数据备份,其支持同 Milvus 实例、跨 Milvus 实例、跨版本间的备份还原。
使用 milvus-backup 前需要仔细阅读对 milvus 各版本的兼容情况:
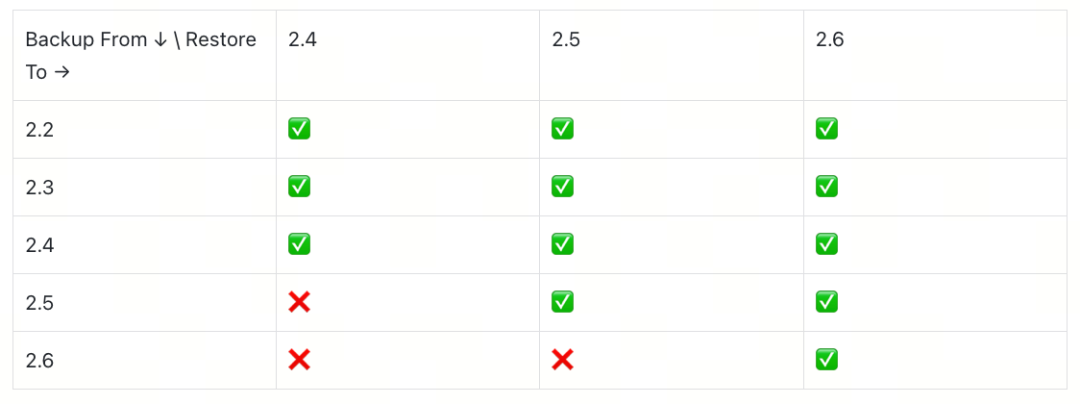
✅ = Supported ❌ = Not supported
Rules:
- Backup is supported from Milvus 2.2+
- Restore is supported to Milvus 2.4+
- A backup can only be restored to the same or newer Milvus versions
- For example, backups created in Milvus 2.5 cannot be restored to 2.4
Milvus-Backup 架构与工作原理
根据 Milvus 官方文档,Milvus Backup 便于跨 Milvus 实例备份和恢复元数据、Segment 和数据。它提供 CLI、API 和基于 gRPC 的 Go 模块等北向接口,以便灵活操作备份和还原过程。
备份流程:
Milvus Backup 从源 Milvus 实例读取 Collection 元数据和 Segment 信息以创建备份,然后从源 Milvus 实例的根路径(Root Path)复制 Collection 数据,并将复制的数据保存到备份根路径(Backup Root Path)。
还原流程:
从备份中还原时,Milvus Backup 根据备份中的 Collection 元数据和 Segment 信息,在目标 Milvus 实例中创建一个新的 Collection,然后将备份数据从备份根路径复制到目标实例的根路径。
简而言之,备份和还原的核心数据包含两部分:
- 对象存储中的数据文件:包括向量数据、标量数据等 Segment 文件(存储在 MinIO/S3 中)
- 元数据信息:Collection Schema、Partition 信息、Segment 元数据等
执行备份
备份配置文件(configs/backup.yaml)核心配置
milvus:
address: 1.1.1.1 # 源milvus的地址
port: 19530 # 源milvus的端口
user: root # 源milvus用户名(需要有备份权限)
password: <PASS> # 源milvus用户密码
etcd:
endpoints: "2.2.2.1:2379,2.2.2.2:2379,2.2.2.3:2379" # milvus连接的etcd集群端点
rootPath: "by-dev" # milvus元数据在etcd中的前缀,如没修改默认为by-dev,建议操作前查看etcd确认
minio:
# 源milvus对象存储桶配置
storageType: "aliyun" # support storage type: local, minio, s3, aws, gcp, ali(aliyun), azure, tc(tencent), gcpnative
address: ks3-cn-beijing-internal.ksyuncs.com # Address of MinIO/S3
port: 443 # Port of MinIO/S3
accessKeyID: <源对象存储AK>
secretAccessKey: <源对象存储SK>
useSSL: true
bucketName: "<源对象存储桶名>"
rootPath: "file" # 源对象存储桶下保存当前MILVUS数据的根目录前缀,如milvus是使用helm chart安装,默认前缀为file, 建议操作前登陆对象存储查看确认
# 保存备份数据的对象存储桶配置
backupStorageType: "aliyun" # support storage type: local, minio, s3, aws, gcp, ali(aliyun), azure, tc(tencent)
backupAddress: ks3-cn-beijing-internal.ksyuncs.com # Address of MinIO/S3
backupPort: 443 # Port of MinIO/S3
backupAccessKeyID: <备份桶AK>
backupSecretAccessKey: <备份桶SK>
backupBucketName: <备份桶名称>
backupRootPath: "backup" # Rootpath to store backup data. Backup data will store to backupBucketName/backupRootPath
backupUseSSL: true # Access to MinIO/S3 with SSL
crossStorage: "true" # 当跨存储备份需要设置为true
# 使用 milvus-backup 创建备份
./milvus-backup create --config configs/backup.yaml -n backup_v2216
Tips:Milvus-Backup 支持热备份,对线上集群的运行影响极小,可以在业务运行期间执行。但建议在业务低峰期进行,以减少对查询性能的影响。
备份验证
备份完成后,务必验证备份数据的完整性:
# 查看备份列表
./milvus-backup list --config configs/backup.yaml
# 查看备份详情,确认 Collection 和 Segment 数量
./milvus-backup get --config configs/backup.yaml -n backup_v2216
Milvus 升级 —— 使用 Helm
考虑到 2.2 到 2.5 跨越了多个大版本,且我们的数据量较大,我们采用了新建集群 + 数据迁移的方式,而非原地升级。
部署新版本集群
使用 Helm Chart 部署 Milvus 2.5.16 集群:
# 添加 Milvus Helm 仓库
helm repo add milvus https://zilliztech.github.io/milvus-helm/
helm repo update
# 查看目标milvus版本对应的helm chart version
helm search repo milvus/milvus -l | grep 2.5.16
milvus/milvus 4.2.58 2.5.16 Milvus is an open-source vector database built ...
# 部署新版本集群(关闭 mmap)
helm install milvus-v25 milvus/milvus \
--namespace milvus-new \
--values values-v25.yaml \
--version 4.2.58 \
--wait
关键配置调整
在新集群的 values.yaml 中,我们做了以下关键配置:
- 关闭 mmap:由于我们的场景对延时敏感,关闭 mmap 确保数据全部加载到内存中,避免磁盘 I/O 带来的延迟抖动
- QueryNode 副本数:保持与旧集群一致,16 个 QueryNode
- 资源配置:每个 QueryNode Pod CPU Limit 16 核
升级注意事项
- 跨大版本升级建议采用新建集群方式,降低风险
- 版本升级后无法回退,务必确保备份完整
- 升级过程中旧集群保持运行,确保业务不中断
升级后的数据迁移 —— 使用 Milvus-Backup Restore
新集群部署完成后,使用 milvus-backup 将数据从旧集群迁移到新集群。
执行数据恢复
还原配置文件(configs/restore.yaml)核心配置
# 还原目标milvus连接信息
milvus:
address: 1.1.1.1 # milvus的地址
port: 19530 # milvus的端口
user: root # milvus用户名(需要有还原权限)
password: <PASS> # milvus用户密码
etcd:
endpoints: "2.2.2.1:2379,2.2.2.2:2379,2.2.2.3:2379" # 目标milvus连接的etcd集群端点
rootPath: "by-dev" # milvus元数据在etcd中的前缀,如没修改默认为by-dev,建议操作前查看etcd确认
minio:
# 目标milvus对象存储桶配置
storageType: "aliyun" # support storage type: local, minio, s3, aws, gcp, ali(aliyun), azure, tc(tencent), gcpnative
address: ks3-cn-beijing-internal.ksyuncs.com # Address of MinIO/S3
port: 443 # Port of MinIO/S3
accessKeyID: <对象存储AK>
secretAccessKey: <对象存储SK>
useSSL: true
bucketName: "<对象存储桶名>"
rootPath: "file" # 对象存储桶下保存当前MILVUS数据的根目录前缀,如milvus是使用helm chart安装,默认前缀为file, 建议操作前登陆对象存储查看确认
# 保存备份数据的对象存储桶配置
backupStorageType: "aliyun" # support storage type: local, minio, s3, aws, gcp, ali(aliyun), azure, tc(tencent)
backupAddress: ks3-cn-beijing-internal.ksyuncs.com # Address of MinIO/S3
backupPort: 443 # Port of MinIO/S3
backupAccessKeyID: <备份桶AK>
backupSecretAccessKey: <备份桶SK>
backupBucketName: <备份桶名称>
backupRootPath: "backup" # Rootpath to store backup data. Backup data will store to backupBucketName/backupRootPath
backupUseSSL: true # Access to MinIO/S3 with SSL
crossStorage: "true" # 当跨存储备份需要设置为true
./milvus-backup restore --config configs/restore.yaml -n backup_v2216 --rebuild_index
restore.yaml 中需要配置新集群的 Milvus 和 MinIO 连接信息,确保数据写入到新集群的存储中。
恢复后的验证
恢复完成后,需要验证:
- Collection 的 Schema 是否完整
- 数据总行数是否与旧集群一致
- 索引是否正确构建
- 执行几组测试查询,对比结果的准确性
灰度切量
数据迁移完成后,我们采用分阶段灰度切量策略,逐步将流量从旧集群切换到新集群:
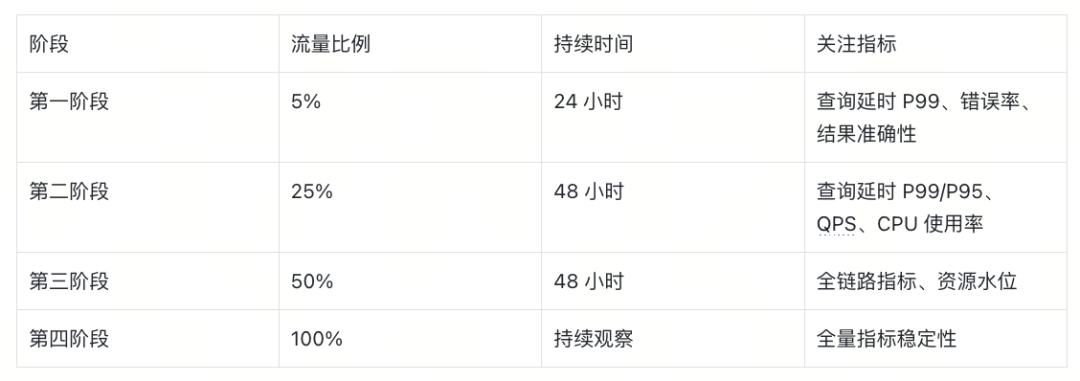
在每个阶段,旧集群保持待命状态,一旦发现异常可以快速回切。
正是在灰度切量阶段,我们发现了新集群的 search 延时异常——相比旧集群增加了 3~5 倍。
排查升级后查询性能变差
现象描述
灰度切量后,监控显示新集群(v2.5.16)的 search 延时相比旧集群(v2.2.16)增加了3~5 倍,这是不可接受的性能退化。
排查第一步:资源使用率分析
首先查看了各组件的 CPU 使用情况:
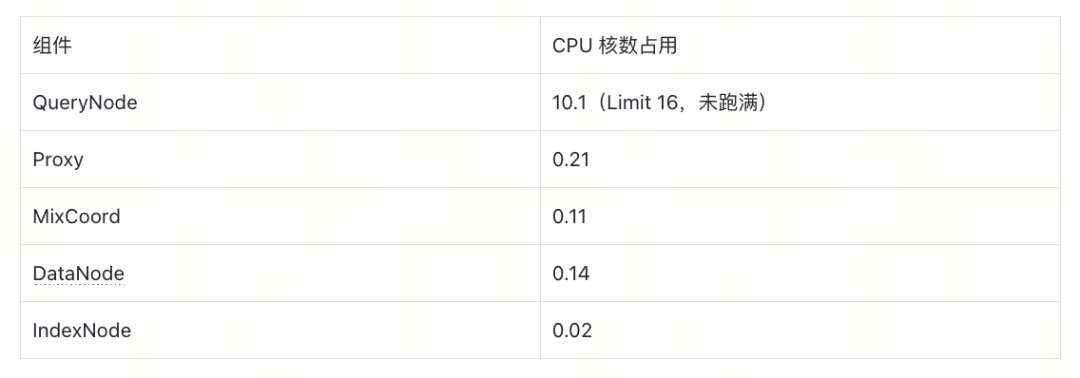
QueryNode 的 CPU 使用率仅约 63%(10.1/16),远未达到瓶颈。
排查第二步:QueryNode Pod 级别 CPU 分析
进一步查看各 QueryNode Pod 的 CPU 使用率(POD CPU Usage / CPU Limits),发现了明显的不均衡现象:
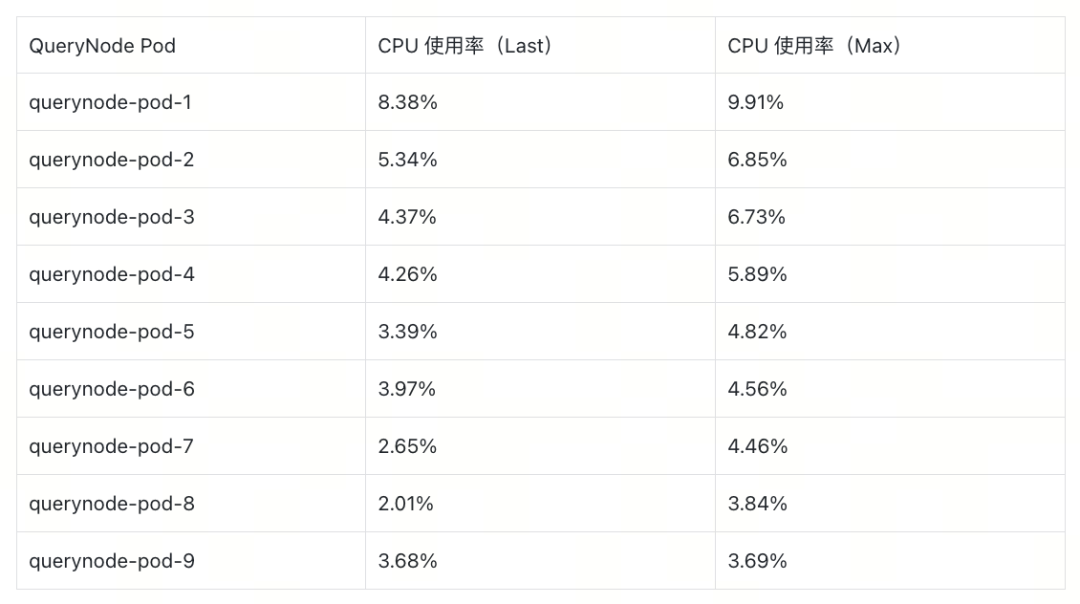
最高的 Pod CPU 使用率是最低的近 5 倍,这说明负载分布严重不均。
排查第三步:Segment 分布对比
这是定位问题的关键一步。我们对比了新旧集群中同一个 Collection 的 Segment 分布情况。
v2.2.16 的 Segment 分布(共 13 个 Segment)

特点:Segment 数量少,每个 Segment 的行数基本均衡(约 74 万行),数据分布均匀。
v2.5.16 的 Segment 分布(共 21 个 Segment)
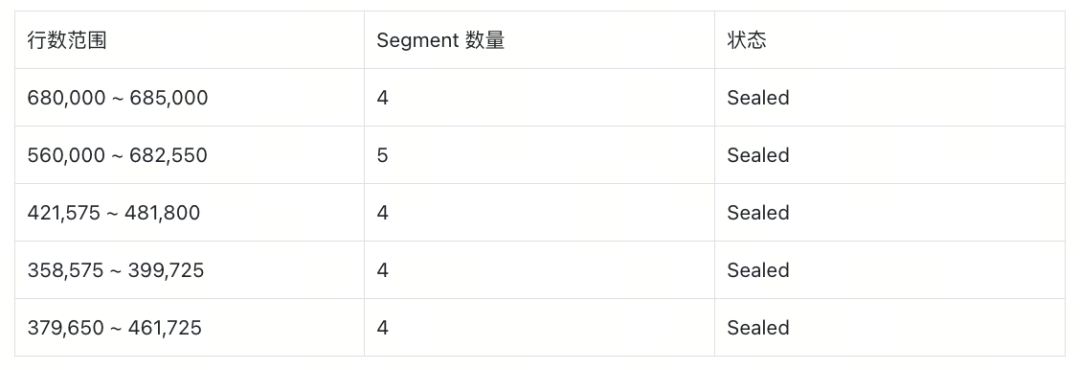
特点:Segment 数量增加到 21 个(比旧集群多了 60%),每个 Segment 的行数差异巨大(从 35 万到 68 万),分布极度不均衡。
根因定位
经过深入排查,我们发现问题的根因在于 milvus-backup restore 时使用了 --use_v2_restore 参数。
完整的 restore 命令如下:
./milvus-backup restore --config configs/restore.yaml -n backup_v2216 \
--rebuild_index \
--use_v2_restore \
--drop_exist_collection \
--drop_exist_index
--use_v2_restore 参数会使用 v2 版本的恢复逻辑,该逻辑在跨版本恢复时会导致 Segment 的重新组织方式与原集群不同,造成 Segment 数量增多且行数分布不均。
Segment 不均衡导致性能下降的原因:
- 部分 QueryNode 加载了更多或更大的 Segment,成为热点节点
- 查询时各 QueryNode 的计算量不均,整体查询延时取决于最慢的节点(木桶效应)
- Segment 数量增多导致查询时需要合并更多的子结果,增加了额外开销
解决方案
清除数据,不使用 --use_v2_restore 参数重新恢复:
./milvus-backup restore --config configs/restore.yaml -n backup_v2216
去掉 --use_v2_restore 后重新恢复,Segment 的分布恢复正常,search 延时回归到预期水平。
反思:如何提升此类性能问题的排查效率
回顾整个排查过程,发现 Segment 不均衡这一现象花费了较长时间。这类性能问题的排查效率可以从以下几个方面优化:
建立完善的可观测性体系
Segment 分布监控是目前 Milvus 监控中容易被忽视的一环。建议:
- 增加 Segment 维度的 Grafana Dashboard:展示各 QueryNode 上 Segment 的数量、行数分布、大小分布等
- 设置 Segment 均衡度告警:当各 QueryNode 之间的 Segment 行数标准差超过阈值时触发告警
- 对比面板:在升级/迁移场景下,提供新旧集群 Segment 分布的对比视图
PS: 当前 Milvus 并未提供 collection 维度的 Segment 的数量、行数分布、大小分布等监控指标,只能从 attu 或 etcd 获取,希望社区后续能优化一下监控指标。
制定标准化的迁移验证 Checklist
每次执行数据迁移后,应按照标准 Checklist 进行验证:
- Collection Schema 一致性
- 数据总行数一致性
- Segment 数量对比(新旧集群)
- Segment 行数分布对比(新旧集群)
- 索引构建状态
- 查询延时基准测试(P50/P95/P99)
- QueryNode CPU 使用率均衡度
自动化诊断工具
建议开发或引入自动化诊断脚本,在迁移完成后自动检测潜在问题:
from pymilvus import connections, utility, Collection
def check_segment_balance(collection_name: str):
"""检查 Segment 分布均衡度"""
collection = Collection(collection_name)
# 获取所有 segment 信息
segments = utility.get_query_segment_info(collection_name)
# 按 QueryNode 分组统计
node_stats = {}
for seg in segments:
node_id = seg.nodeID
if node_id not in node_stats:
node_stats[node_id] = {"count": 0, "rows": 0}
node_stats[node_id]["count"] += 1
node_stats[node_id]["rows"] += seg.num_rows
# 计算均衡度
row_counts = [v["rows"] for v in node_stats.values()]
avg_rows = sum(row_counts) / len(row_counts)
max_deviation = max(abs(r - avg_rows) / avg_rows for r in row_counts)
print(f"节点数: {len(node_stats)}")
print(f"平均行数: {avg_rows:.0f}")
print(f"最大偏差: {max_deviation:.2%}")
if max_deviation > 0.2: # 偏差超过 20% 告警
print("⚠️ 警告: Segment 分布不均衡,可能影响查询性能!")
for node_id, stats in sorted(node_stats.items()):
print(f" Node {node_id}: {stats['count']} segments, {stats['rows']} rows")
# 使用示例
connections.connect(host="localhost", port="19530")
check_segment_balance("your_collection_name")
利用社区工具辅助排查
- Birdwatcher:Milvus 官方的诊断工具,可以直接查看 etcd 中的元数据,包括 Segment 分布、Channel 分配等信息
- Milvus Web UI(v2.5+ 内置):提供可视化的 Segment 信息查看界面
- Grafana + Prometheus:利用 Milvus 暴露的 metrics 构建自定义监控面板
对社区的建议
基于这次排查经验,我们向 Milvus 社区提出以下建议:
- milvus-backup 跨版本恢复的兼容性测试:建议在文档中明确标注各恢复参数在跨版本场景下的行为差异,特别是
--use_v2_restore 参数
- 增强迁移后的自动健康检查:在 restore 完成后自动输出 Segment 分布摘要,帮助用户快速发现异常
- Segment 均衡度指标:在 Milvus 的 metrics 中增加 Segment 均衡度相关的指标,方便用户监控
- 查询执行计划: 支持类似 MySQL 的“explain select sql“分析查询语句的执行性能,方便性能问题分析
总结
这次升级排查给我们最大的教训是:数据迁移不仅要关注数据的正确性,还要关注数据的分布特征。Segment 的数量和行数分布直接影响查询性能,这在跨版本迁移时尤其需要注意。
以下是我们梳理的一些升级中的小技巧:

希望这篇文章能帮助到有类似升级需求的 Milvus 用户。如果你也遇到了类似的问题,欢迎在 云栈社区 等技术论坛中交流讨论。本文由 WPS 软件工程师 will 基于实战经验撰写。
 发表于 2026-3-25 02:26:20
|
查看: 103|
回复: 0
发表于 2026-3-25 02:26:20
|
查看: 103|
回复: 0
