RGB-A 视频在普通的彩色(RGB)视频之外,增加了一个透明度(Alpha)通道。这一特性为游戏设计、影视后期以及交互界面开发等创意领域打开了新的想象空间。然而,现有的技术方案常常面临一个核心难题:RGB色彩信息与Alpha透明度信息在生成过程中容易相互干扰,导致最终效果在画面质量和透明感上都差强人意。问题的关键在于,如何将二者的数据分布有效解耦,并让模型学会协同生成它们。
近日,一项由天津大学等机构的研究者提出的工作给出了出色的解决方案。他们开源了名为 Wan-Alpha 的高质量 RGB-A 视频生成模型。该方法通过在潜空间与噪声空间中巧妙地“平移”透明度分布,同时严格保持 RGB 信息的保真度,从而实现了稳定且可控的透明效果生成。

生成视频示例:泡泡内的动态光效

Alpha通道可视化:球体内部的动态结构
借助独创的透明度感知双向扩散损失与均值平移噪声采样器,该方法在复杂边缘和半透明特效的渲染上表现优异。实验表明,该模型在文本对齐度、视觉美感、画面自然度、运动平滑性以及时序一致性等多个关键指标上,均显著超越了现有的SOTA方法。目前,Wan-Alpha的模型、代码均已开源,相关论文也已被顶级会议CVPR 2026接收。

论文标题:Video Generation with Stable Transparency via Shiftable RGB-A Distribution Learner
方法
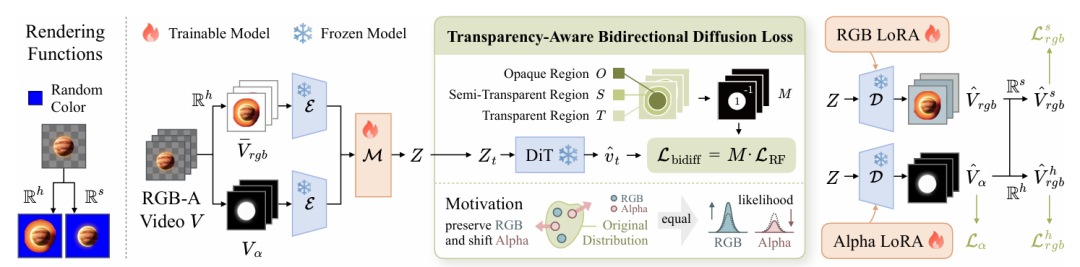
图1:RGB-A VAE的训练框架。
1. 可区分的 RGB-A 潜空间学习
Wan-Alpha的整体架构如图1所示。它以强大的文本到视频基础模型 Wan2.1-T2V-14B 为基底,并将其中的VAE(变分自编码器)扩展为能够同时编码RGB和Alpha信息的共享潜空间。然而,简单的直接编码容易导致两种特征耦合,从而在生成时引入空洞或伪影。
透明度感知双向扩散损失:为了提升潜空间的质量,研究团队的目标是在保持RGB分布不变的前提下,“平移”Alpha的分布。他们引入了一个冻结的DiT(扩散变换器),并利用一种双向扩散损失。该损失通过掩码反转透明区域的梯度符号,引导VAE学习到更具区分性的RGB-A潜在表示。
渲染损失:为了进一步增强重建质量,论文定义了两种渲染函数:
- 软渲染:模拟真实的半透明叠加效果。
- 硬渲染:产生清晰的、不透明的轮廓。
训练时,会从一个预定义的颜色集合中随机选取背景色进行渲染。
$$
R^s(V_{rgb}, V_{\alpha}, c) = V_{rgb} \cdot V_{\alpha} + c \cdot (1 - V_{\alpha}),
$$
$$
R^h(V_{rgb}, V_{\alpha}, c) = V_{rgb} \cdot 1_{V_{\alpha}>0} + c \cdot (1 - 1_{V_{\alpha}>0})
$$
为了使模型能差异化地关注不透明、半透明和完全透明的区域,他们将一个复合重建损失分别应用于Alpha视频、软渲染视频和硬渲染视频这三种模态。该复合损失结合了像素级重建误差、感知损失和边缘一致性约束。
$$
\mathcal{L}_{\Phi} = ||\Phi(\hat{W}) - \Phi(V)||_2,
$$
$$
\mathcal{L}_s = ||S(\hat{W}) - S(V)||,
$$
$$
\mathcal{L}_{recon}(\hat{W}, V) = ||\hat{W} - V|| + \mathcal{L}_{\Phi} + \mathcal{L}_s,
$$
这三种损失共同构成了VAE的最终训练目标。
2. 可控的 RGB-A 生成
当我们将一个预训练好的纯RGB模型适配到RGB-A生成任务时,保留基础模型强大的生成能力对效果提升至关重要,但这也会带来一个副作用:模型可能倾向于生成我们不希望的背景内容。
研究团队提出,将透明度先验信息直接“注入”到初始的高斯噪声中。这一策略促使视频生成模型更好地区分前景(不透明/半透明)与背景(透明)区域,同时也为透明度的生成提供了一个可控的“开关”。
透明度引导的均值采样器:在修正流框架下,该方法根据输入Alpha视频的信息来平移噪声的均值,并引入一个高斯椭圆掩码来精细控制透明区域的噪声分布。
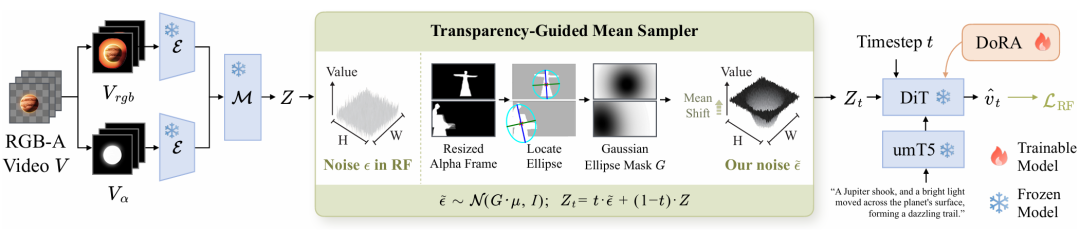
图2:RGB-A视频生成的训练框架。
架构设计如图2所示。采用预训练好的RGB-A VAE编码器获取潜变量,与平移后的噪声结合形成含噪潜变量。其中的DiT部分采用DoRA(权重分解的低秩适应)方式进行训练,以提升语义对齐与生成质量。
在推理阶段,仅需修改初始噪声的生成方式和解码器配置,所有参数均可合并,不引入任何额外计算开销。得益于LightX2V加速技术,仅需4步采样即可生成高质量结果,推理速度比现有最优方法提升了15倍。这项技术在开源实战社区中引起了广泛关注,为高效视频生成提供了新的思路。
数据集
VAE的训练数据涵盖了10个图像抠图和3个视频抠图数据集。对于图像数据,通过将其转换为静态视频并在时间轴上进行滑动窗口采样,来模拟动态效果。数据集按95:5的比例划分为训练集和验证集,分别包含77,237和4,066个视频片段。
RGB-A视频生成模型的训练数据来源于同批次采集的数据,并经过筛选,重点关注包含复杂运动、半透明物体(如纱、烟雾)以及特殊光照效果的样本。利用Qwen2.5-VL-72B模型为这些样本生成详细的文字描述,并标注了动作速度、艺术风格等属性标签。最终的数据集包含301个视频抠图视频、43幅图像抠图图像以及85个从互联网收集的特效视频,这些高质量的数据对训练强大的人工智能模型至关重要。

图3:数据集中复杂边缘与多种半透明特效的样本示例。
评估
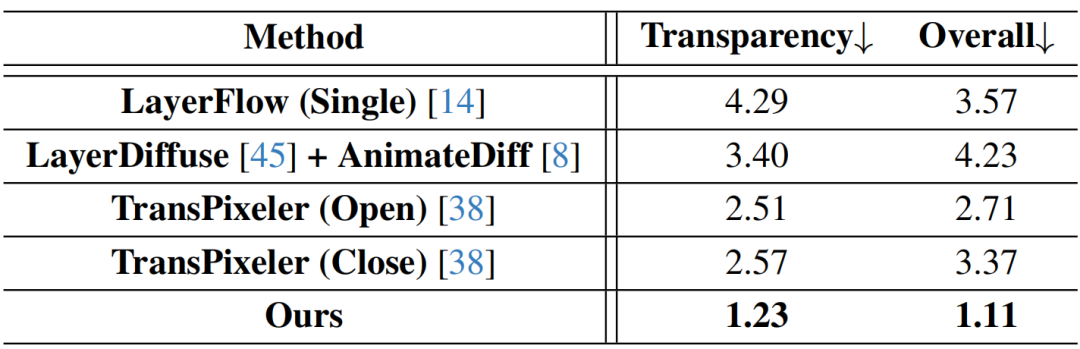
RGB-A视频生成是一个新兴任务,目前仅有TransPixeler和LayerFlow能够直接生成RGB-A视频。对于TransPixeler,除了评估其开源版本,还在Adobe Firefly上评估了其闭源版本。为了进行更全面的对比,研究者还将LayerDiffuse(一个图像层生成模型)集成到了文本到视频模型AnimateDiff中。
定量结果如表1所示。得益于“保持RGB分布以维持基础模型能力,同时平移透明度分布以更好区分透明区域”的框架设计,Wan-Alpha在表1的所有定量指标上均取得了最优结果。
表1:与现有RGB-A视频生成方法的定量对比结果。

定性结果如图4所示。可以看到,Wan-Alpha模型能够生成极为细腻的发丝、自然连贯的人物动作、逼真的火焰与烟雾动态,以及准确的透明玻璃与眼镜反光效果。用户研究(表2)进一步验证了该模型在透明度正确性和整体质量上的优越性。

图4:与现有RGB-A视频生成方法的定性对比(人物、动物、透明物体)。
表2:用户对透明度正确性与整体质量的偏好排名结果(数值越低越好)。
Wan-Alpha的成功标志着在智能 & 数据 & 云驱动的AIGC领域,对于复杂多通道视觉内容的生成控制达到了新的高度。其开源的特性也将推动相关研究和应用在社区的快速发展。想了解更多前沿技术解析和实战讨论,欢迎访问云栈社区与广大开发者交流。
 发表于 2026-3-25 23:33:43
|
查看: 174|
回复: 0
发表于 2026-3-25 23:33:43
|
查看: 174|
回复: 0
