https://arxiv.org/pdf/2603.22340
Graphs RAG at Scale: Beyond Retrieval-Augmented Generation With Labeled Property Graphs and Resource Description Framework for Complex and Unknown Search Spaces

传统RAG的瓶颈
大型语言模型(LLM)虽然能力强大,但面临着知识静态化和“幻觉”问题的困扰。检索增强生成(RAG)通过动态地检索外部知识来缓解这一问题,已成为当前主流方案。然而,传统的RAG依赖于密集向量嵌入和相似性搜索,在面对复杂的结构化或半结构化数据时,暴露了其固有的局限性:Dual-Tree Agent RAG:可控、可解释、可验证
- 搜索空间僵化:检索过程必须预先指定返回的文档数量(top-k)。当搜索空间未知或查询意图复杂时(例如“找出某位基金经理管理的所有基金”),很难确定一个合适的K值,导致信息遗漏或引入过多噪声。
- 数据结构限制:在处理深层嵌套的JSON、XML等半结构化数据时表现不佳。将复杂的结构“压平”为文本容易丢失关键的上下文关系和层次信息,进而引发模型幻觉。
- 重排序开销:向量检索返回的结果通常需要额外的重排序模型进行二次过滤,以提升相关性。这不仅增加了系统的复杂度,也带来了额外的延迟和计算成本。
当面对金融、医疗等领域的复杂结构化数据时,传统RAG在检索精度和结果完整性方面往往显得力不从心。
双架构Graph RAG框架
为了突破上述瓶颈,一项新研究提出了名为Graph RAG的框架。其核心创新在于,不是依赖单一的检索范式,而是巧妙地结合了两种主流的图数据库范式,构建了一个强大的双轨检索系统。
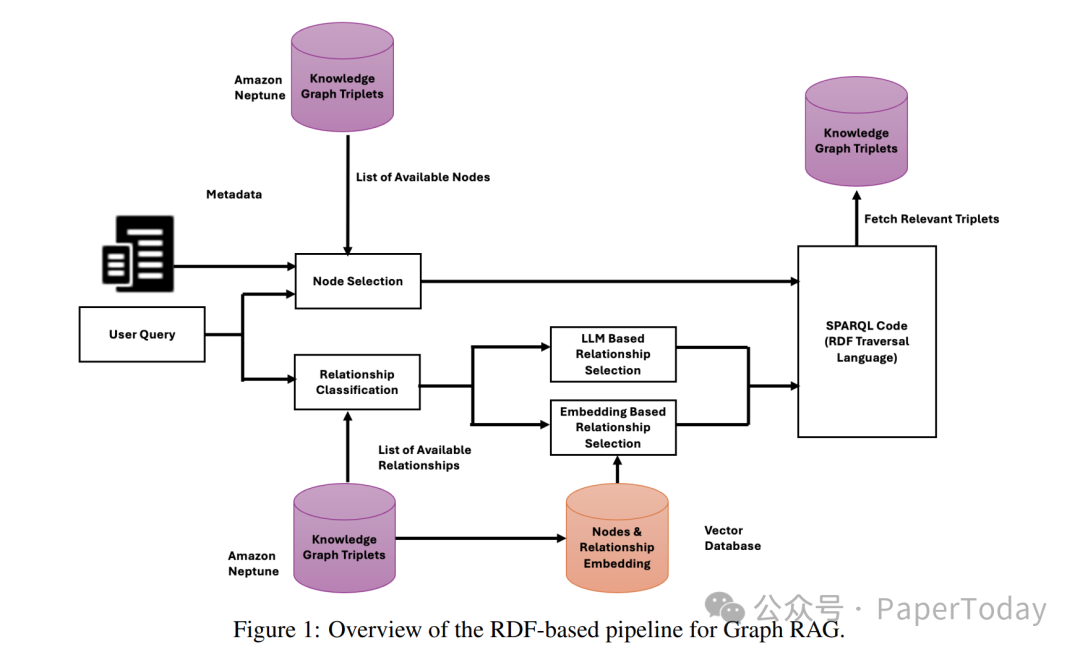
1. RDF三元组方案(RDF Pipeline)
RDF(资源描述框架)是一种用于描述网络资源的通用框架,其基本单元是“主语-谓语-宾语”构成的三元组。在此方案中,研究人员将原始的JSON数据通过键值对递归转换,构建了一个包含超过65万个三元组的知识图谱。
检索过程采用了节点与关系双选策略,这大大提升了查询的精准度:
- 首先,利用监督分类和嵌入相似度计算,从超过8000种预定义的关系类型中筛选出候选关系。
- 然后,结合大型语言模型(LLM)的理解能力和确定性映射规则,选择出与查询最相关的节点。
- 最后,通过SPARQL(RDF的查询语言)或NetworkX库进行灵活的图遍历。这种方法的最大优势在于,无需预先设定返回结果的数量,系统能够根据图的结构动态地找出所有相关节点。
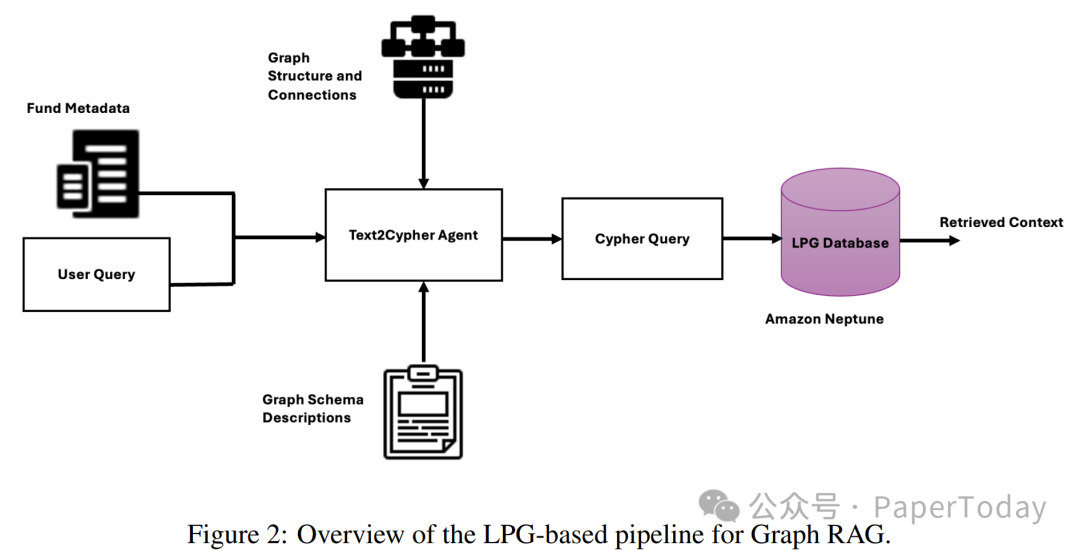
2. 标签属性图方案(LPG Pipeline)
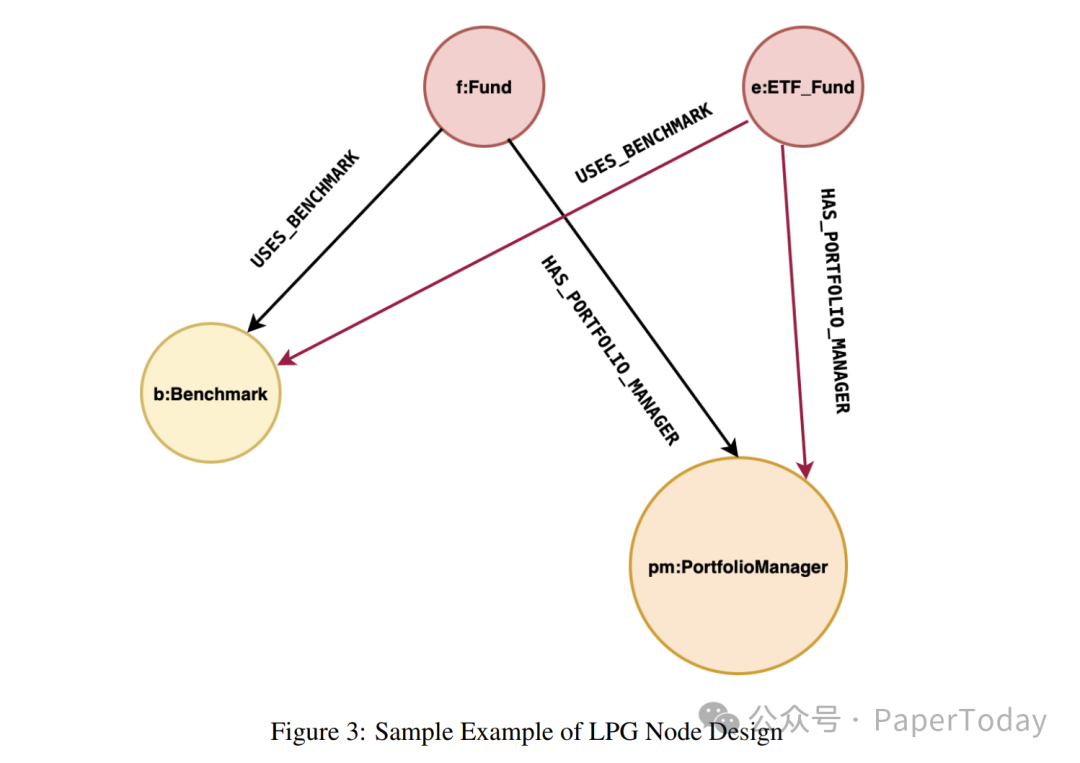
标签属性图是另一种流行的图数据模型,它由带有标签和属性的节点,以及带有类型和属性的关系构成。该方案的核心是Text-to-Cypher技术,能够将用户的自然语言查询实时地转换为图查询语句(Cypher是LPG常用的查询语言)。
其实现要点包括:
- Schema感知:向转换模型(如LLM)提供完整的图结构信息作为上下文,包括79个节点标签和57种关系类型,确保生成的查询语句语法正确且符合业务逻辑。
- 精确的多跳遍历:充分利用图数据库固有的多跳查询能力,轻松处理复杂的关联查询。例如,“查找所有使用标普500指数作为基准的基金”这类查询,可以通过简单的几跳遍历精准完成。
- 高准确率与实时性:在实际测试中,自然语言到Cypher的翻译准确率超过了90%,完全适用于在线实时应用场景。
图检索的显著优势
为了量化评估效果,研究团队设计了一套包含200道测试题的评估集,涵盖了搜索(列表)、对比、详情查询等多种意图。在满分200分的评价体系中,三种方法的总体表现对比如下:
| 方法 |
总分 |
搜索/列表意图得分 |
| LPG |
185.5 |
93/100 |
| RDF |
172.5 |
80/100 |
| Agentic RAG |
116 |
38.5/100 |
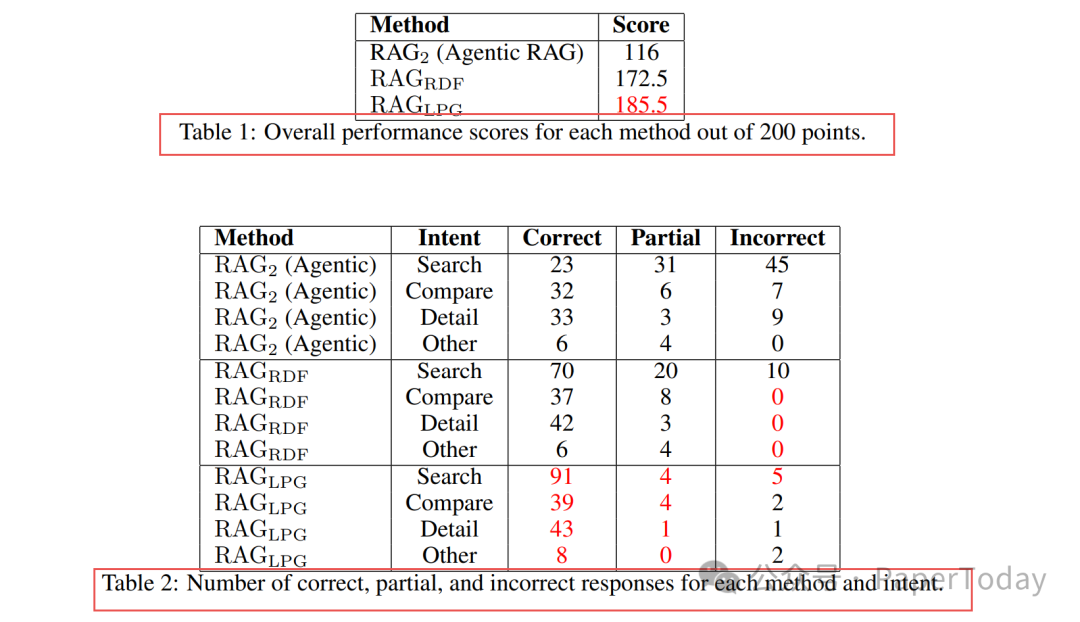
从结果中可以得出几个关键结论:
- LPG在复杂搜索任务上表现卓越:对于“列出某基金经理管理的所有基金”这类无法预先确定返回数量的查询,LPG通过图遍历可以准确返回全部相关结果。而传统RAG因为难以确定K值,往往会遗漏部分信息。
- 彻底消除重排序依赖:图检索直接返回精确匹配的结构化信息片段,天然具备高相关性,完全避免了向量检索后繁杂且耗时的重排序步骤。
- 结构化数据处理的原生优势:相比于将JSON数据转换为叙述性文本(这种方式不仅成本高,且极易因信息丢失而产生幻觉),直接将其建模为图数据,完美保留了数据间的关系和完整性,为LLM提供了最可靠的上下文。
该研究确立了一种思路:Graph RAG,特别是结合了LPG与RDF优势的双架构方案,有望成为下一代检索增强系统的变革性范式。它尤其适用于金融、医疗、法律等涉及海量复杂半结构化数据的知识密集型领域,为实现更精准、更可靠的企业级智能应用铺平了道路。如果你对构建此类知识图谱或探索前沿的RAG技术感兴趣,欢迎到云栈社区的人工智能板块与更多开发者交流讨论。 |  发表于 2026-3-26 01:11:32
|
查看: 128|
回复: 0
发表于 2026-3-26 01:11:32
|
查看: 128|
回复: 0
