当前 AI 编程工具的发展,似乎都聚焦在如何“写得更快”上。然而,在实际的团队协作中,更大的效率瓶颈往往出现在“如何看懂”已有的、复杂的代码库上。
Understand-Anything 所做的,正是试图填补这个空白。它首先将整个代码库扫描、分析,转化为一张可搜索、可对话、可交互浏览的知识图谱,然后将这层结构化的“理解”作为中间层,交付给开发者和 AI 共同使用。
起初,你可能以为这只是 Claude Code 平台上的一个小插件。但仔细阅读其 README 和源码后,你会发现它的野心更大——它瞄准的是 AI 编程工具链中长期缺失的一环:代码理解层。
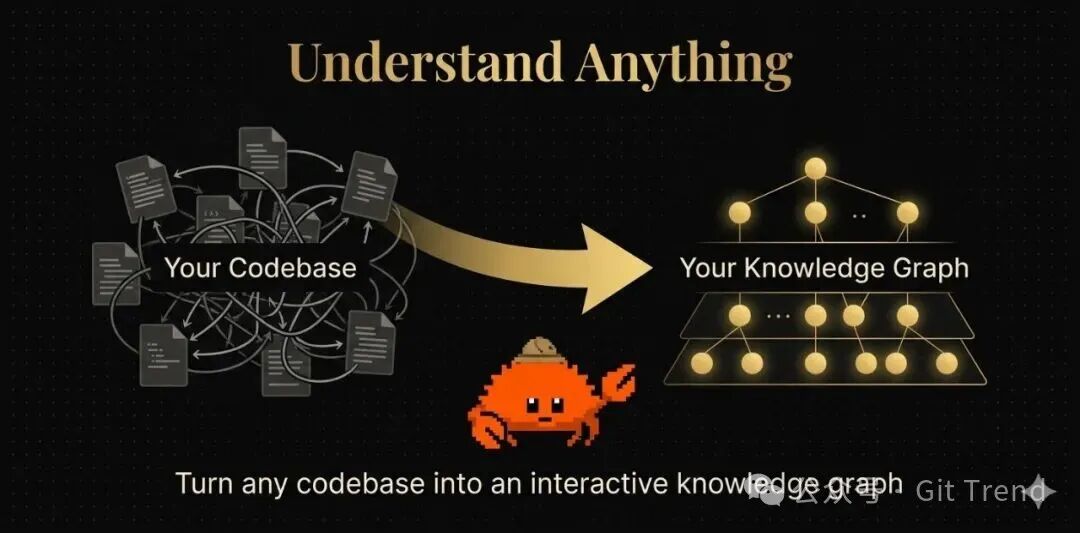
项目首页主视觉:将任意代码库转化为可探索、可搜索、可提问的交互式知识图谱。
它到底做了什么?
简单来说,Understand-Anything 并非简单地为源代码包上一层文本摘要,而是在尝试构建一个独立于具体实现的“代码库理解层”。
1. 扫描项目,生成知识图谱
根据 README,其核心启动命令是 /understand。运行后,工具会从项目文件中提取文件、函数、类以及它们之间的依赖关系,最终生成一个结构化的 JSON 文件:.understand-anything/knowledge-graph.json。
这不是空谈,源码可以印证这一点:GraphBuilder 模块负责组织文件节点、函数节点、类节点,并用 contains、imports、calls 等关系边将它们连接起来,形成一个完整的知识图谱结构。
这一步的直接价值在于,它将原本散落在目录树、import 语句和函数调用中的信息,首次整理成一个机器和人(尤其是新加入的开发者)都能更容易消化的中间表示。很多 AI 工具之所以表现不佳,正是因为其上下文窗口只能看到局部,理解天生是碎片化的。而生成知识图谱这一步,本质是在为系统补全“全局视角”。
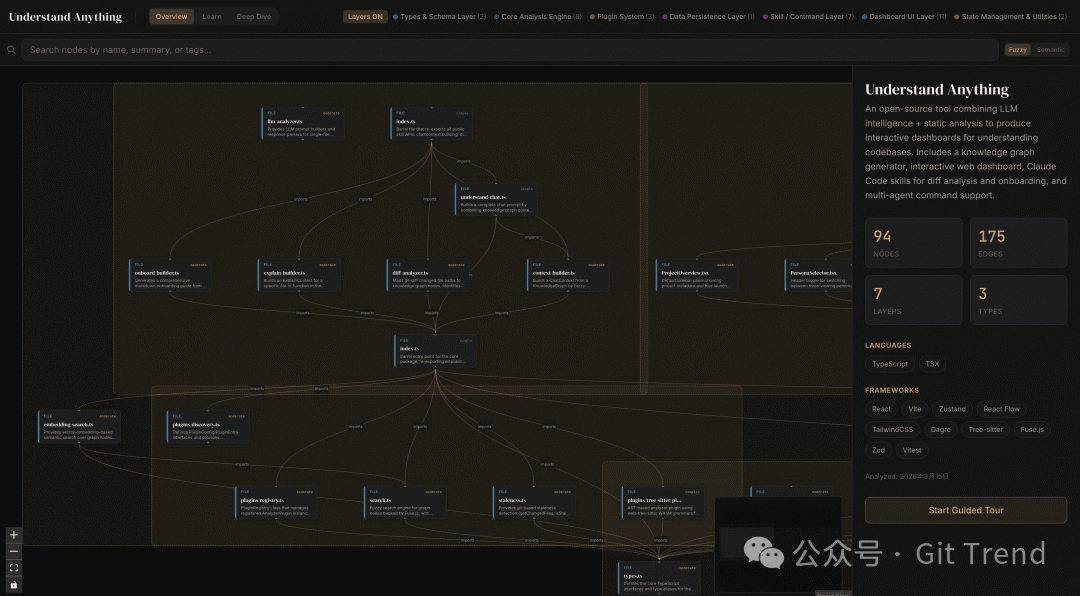
README 中展示的关系图预览,揭示了其想交付的核心体验:不是一段文字解释,而是一张可供导航的系统地图。
2. 提供可交互的图形化看板
它并未止步于“分析完成,生成一个 JSON 文件”。
通过 /understand-dashboard 命令,它会启动一个图形化的 Web 界面。在这个看板中,你可以点击节点、查看关联关系、进行搜索,并可以按照架构层级来分组展示代码元素。从仓库结构也能看到,它专门拆分了 packages/dashboard 目录,技术栈采用了 React、Vite、React Flow、Zustand 和 Dagre。
这一步至关重要。许多“代码理解工具”最终被困在命令行中,空有能力却难以融入日常开发工作流。而一个直观的图形化界面,更贴近人类探索复杂系统的真实路径:先纵览全局,再决定向哪一层级深入。
3. 将“理解”接入 AI 工作流
README 中列出的一系列命令,比任何口号都更能说明它的定位:
/understand/understand-chat/understand-diff/understand-explain/understand-onboard
其中,/understand-diff 尤其值得关注。它并非泛泛地允许你“提问”,而是将“改动影响分析”这个非常工程化的具体任务做成了标准能力。查看 diff-analyzer.ts 源码可以发现,它会将改动的文件映射到知识图谱中的对应节点,然后沿着关系边查找受影响的节点、层级和连带关系,最终输出风险评估。
这意味着它不再是一个只会总结的工具,而是开始尝试回答更实际的问题:这次提交会波及哪些模块?是否存在跨层级的意外影响?当前的知识图谱是否覆盖了所有相关文件?
为什么这个方向值得关注?
因为随着 AI 编程能力不断进化,“理解已有复杂系统”这件事的成本将会越来越高,甚至会逐渐成为瓶颈。
生成新代码的成本会越来越低,但团队中沉淀的老项目、复杂的依赖关系以及历史债务并不会自动消失。今天你可以让 AI 快速生成数百行代码,明天就需要有人(或另一个 AI)去理解这些新代码如何嵌入现有的、可能错综复杂的系统中。
因此,关键的看点并非它能否集成更多大模型,而在于它瞄准的问题是否足够“硬核”。Understand-Anything 抓住了一个真实痛点:让人类开发者和 AI 助理首先站在同一份结构化的项目认知基础上,然后再谈生成、修改和自动化执行。
项目的两个聪明之处
1. 早早布局多平台支持
它最初看起来像是 Claude Code 生态内的一个插件,但 README 现已明确支持多平台:Claude Code、Codex、OpenCode、OpenClaw、Cursor、Antigravity。
这不仅是“适配面广”。更关键的是,它将自己定位为一种可迁移的能力层,而非绑定在某个特定 AI 智能体上的附属功能。无论你今天使用 Claude Code,明天切换到 Codex,后天在 OpenClaw 中操作,代码理解这层基础设施最好不需要推倒重来。
2. 扎实的工程化骨架
该项目没有停留在概念阶段,仓库已经拆分出比较完整的产品架构:
packages/core:负责图谱构建、静态分析、搜索和增量更新。packages/dashboard:负责可视化交互界面。skills/ 和 agents/:负责将核心能力接入具体的工作流。
核心包内的实现也并非空壳。例如:
staleness.ts:利用 git diff 来判断知识图谱是否过期,并支持增量合并更新。embedding-search.ts:已经具备了语义检索引擎的雏形。layer-detector 和 tour-generator 等模块,表明它正在向“分层架构理解”和“引导式项目导览”方向延伸。

其真正聪明之处不仅在于支持多平台,更在于把“代码理解”做成了一层可迁移的基础能力。
这意味着它的愿景并非一句“未来可期”,而是已经在朝着“代码理解基础设施”的方向搭建初步骨架。
最短上手路径
根据 README 的描述,最小的使用闭环其实并不复杂。
第一步:安装插件
/plugin marketplace add Lum1104/Understand-Anything
/plugin install understand-anything
第二步:在目标项目中执行分析
/understand
第三步:打开图谱交互看板
/understand-dashboard
第四步:根据需要深入使用
/understand-chat:询问关于项目架构的普遍性问题。/understand-explain:深入探究某个特定文件。/understand-diff:分析某次代码改动的影响范围。/understand-onboard:为新成员生成项目导览指南。
如果是初次尝试,建议不必立即研究所有命令。可以先运行 /understand 和 /understand-dashboard,看看生成的知识图谱是否准确、直观。能否首先得到一张可靠且有用的系统地图,基本决定了这个工具是否值得被纳入你的日常工作流。
真正的挑战在于准确性
这类项目的终极挑战,从来不是功能命令的数量,而是分析结果的准确性和可靠性。
评估一个代码理解工具,通常需要重点关注以下几点:
- 大代码库下的性能:分析速度是否可接受?内存占用是否稳定?
- 图谱质量:提取的依赖关系是否存在明显的错误链接或遗漏?
- 解释的根基:基于图谱生成的解释(如 LLM 的回答)是否真正基于代码结构逻辑,而不仅仅是听起来合理的“套话”?
Understand-Anything 目前的思路和方向是正确的,但它若想真正成为团队信赖的工具,还需要在后续发展中持续证明三件事:在大规模项目中的可用性、增量更新的可靠性,以及 diff 影响分析的准确度。
这类工具的最终成败,不取决于宣传口号,而取决于它能否在真实的复杂项目中持续输出可信赖的结构化认知。
最后的判断
如果仅将 Understand-Anything 视为一个新颖的 Claude Code 技能,可能会低估它的潜力。
它更有价值的地方在于,开始系统性地将“理解代码库”这个模糊的、依赖个人经验的脑力活动,拆解为图谱构建、语义搜索、架构分层、可视化导览、变更影响分析等一系列可复用、可迭代的技术能力。
因此,这个项目值得被归入“值得持续关注”的类别。因为随着人工智能编程的竞争日趋白热化,未来真正的稀缺资源可能不再是“谁更擅长生成代码”,而会越来越倾向于“谁更深入、准确地理解你的代码库”。对于热衷于开源实战的开发者而言,观察这类项目如何演进,本身也是一种学习。
项目信息卡
想了解更多类似的深度工具解析与开发者实践,欢迎在 云栈社区 交流探讨。
 发表于 2026-3-26 02:59:42
|
查看: 915|
回复: 0
发表于 2026-3-26 02:59:42
|
查看: 915|
回复: 0
