数据库服务器的内存是否越大越好?数据库的内存参数设置是否越大越好?
面对这个问题,很多人的第一反应可能是否定的,但实际场景却更为复杂。确实存在一些情况,即便服务器内存充足,性能也可能出现剧烈抖动。其中一个常见原因是刷脏(Flushing Dirty Pages)调度未配置好,导致大量脏页瞬间被挤出内存并写入磁盘,引发IO带宽被临时占满,从而影响了数据库处理实时用户请求的性能。这类问题通常需要通过调整操作系统内核参数以及数据库自身的调度参数来解决。
另一种情况是,当内存过大且数据库长时间连接过多时,每个连接可能访问大量内存页面,导致内存哈希表、码表等内部数据结构变得庞大,反而挤压了实际可用内存,甚至引发OOM(内存溢出)。使用大页(Huge Page)技术通常可以缓解此类问题。
更令人意外的是,某些工作内存参数(如maintenance_work_mem)设置过高,超过了CPU的L3缓存大小,也可能导致数据库处理效率下降。这篇文章将深入探讨这一现象背后的原理。
不要给PostgreSQL过多的内存
在日常运维和性能调优中,我时常遇到一些批处理任务出现问题。这些任务越来越普遍地使用了极高的内存限制参数,特别是maintenance_work_mem和work_mem。我猜测,一些数据库管理员遵循着“越多越好”的简单逻辑,而没有意识到这可能会对性能造成严重的损害。
让我用一个具体的测试案例来证明这一点。这个案例源于我在测试GIN索引并行构建的一个修复程序时遇到的。该bug本身并不复杂,但复现它需要一个相当高的maintenance_work_mem值(最初的报告使用了20GB)。
为了验证修复是否有效,我针对一系列不同的maintenance_work_mem值和不同数量的并行工作进程,运行了CREATE INDEX命令。本意是检查是否仍有组合会导致失败,但我也顺便记录了构建索引的耗时。最终,我得到了下面这张图表:
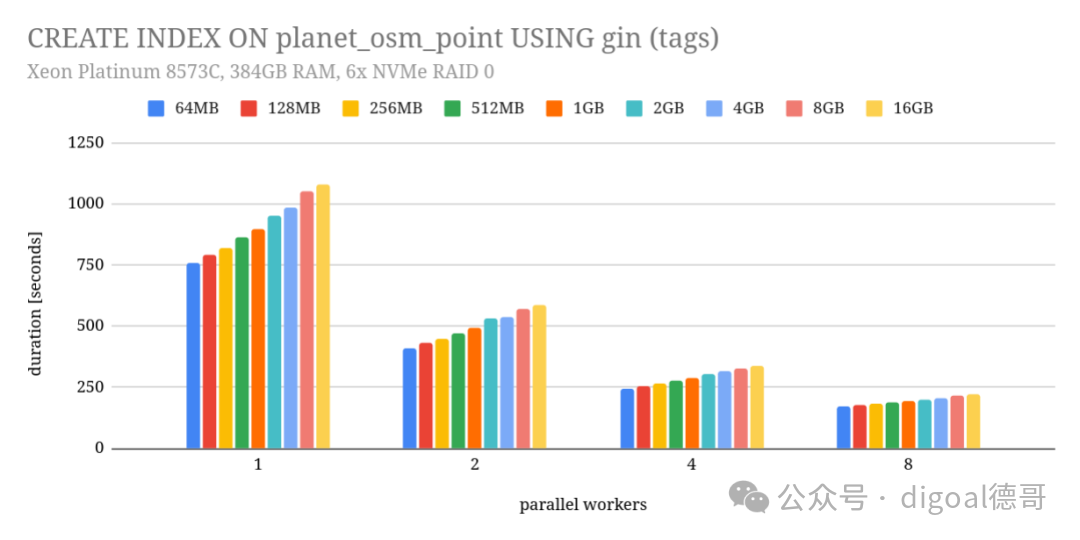
测试环境是Azure上的D96v4实例,配备Xeon Platinum 8573C CPU、384GB RAM,以及6块NVMe硬盘组成的RAID0阵列。这使得测试完全在内存缓存中进行,瓶颈在于CPU。
从图表中可以看出,并行化确实带来了显著的性能提升。使用2个工作进程(领导者也算一个)时,速度提升了约1.8倍,这几乎是理想的线性加速,因为索引构建的最后阶段仍然是串行的。随着工作进程数增加,加速比会有所下降(例如8个进程时加速约4.5倍),这在预期之内。
然而,图表还揭示了一个关键现象:增加maintenance_work_mem的值,反而使索引创建变慢了! 从64MB增加到16GB,耗时增加了约30%,并且这一趋势不受工作进程数量的影响。
性能下降的原因分析
导致这种反直觉现象的原因可能有多个,以下是我认为最重要的两点。
1. L3缓存大小的限制
系统内的所有RAM并非速度均等,而是存在多个性能差异显著的层级。一部分高速RAM集成在CPU内部(即L1、L2、L3缓存),延迟极低。大多数CPU的L3缓存容量大约在32-128MB,虽然容量小,但其访问速度比主内存快一个数量级。
在构建GIN索引时,数据通常会被累积到一个哈希表缓冲区中。当缓冲区“填满”后,再对其进行处理并合并到最终的索引结构里。哈希表的访问模式是随机的。一旦哈希表的大小超过了CPU的L3缓存容量,系统就不得不更频繁地访问速度慢得多的主内存。访问L3缓存可能只需要约20个CPU周期,而访问主内存则可能需要200个周期,性能差距巨大。
因此,以更小的、能够放入L3缓存的块来处理数据通常是更优的选择。虽然这会导致处理更多批次,但整体上可能依然能获得性能胜利。
2. 操作系统页缓存与脏页刷写压力
第二个原因与操作系统内核管理内存的方式有关,这正是前文提到的可能引起性能抖动的刷脏问题。
当哈希表的大小超过maintenance_work_mem设置的限制时,多出的数据会被写入磁盘上的临时文件。由于这些是临时文件,没有持久化要求,所以可以只写入操作系统的页缓存。
然而,内核通过两个阈值(vm.dirty_background_ratio和vm.dirty_ratio)来控制内存中脏数据的总量。当脏数据量达到第一个阈值时,内核开始在后台异步地将数据写入磁盘,此时用户进程的写入操作仍然可以进入页缓存。如果脏数据量持续增长并触及第二个更高的阈值,所有后续写入都将被迫变为同步操作,即进程必须等待数据落盘,这会引发严重的IO延迟和性能骤降。
理想情况下,后台刷写机制能够有效控制脏数据量,避免触及同步刷写的阈值。但这种主动刷写机制的效果,取决于内核是否有足够的时间进行响应。如果以较小、更频繁的块写入数据,内核就能获得更多、更均匀的时间窗口来分批刷新脏页,从而维持系统的平稳运行。
举个例子,假设累积8GB数据到哈希表需要1分钟。一种策略是等待1分钟,然后将8GB数据一次性写出。这期间大部分时间没有写操作,随后是一个巨大的写突发。另一种策略是每累积64MB就写出一次。这样,写操作会均匀分布在整段时间内,给内核充分的反应时间。
当然,在某些特定场景下,累积更多数据可能是有益的,比如提高压缩率。但这需要具体场景具体分析。
总结与建议
上述所有原理同样适用于work_mem参数。work_mem与maintenance_work_mem的唯一区别在于应用场景:前者用于常规查询(如哈希连接、哈希聚合、排序等),后者用于维护操作(如创建索引)。但其背后的内存使用逻辑是完全相同的——它们都控制着特定操作可以使用的内存量,一旦超出CPU缓存的最佳工作范围,就可能引入性能瓶颈。
我无法给出一个适用于所有场景的“最佳”maintenance_work_mem或work_mem值。本文的重点也不在于此。我的核心观点是:盲目地将这些参数设置为极高的值,可能会对性能产生显著的负面影响。
我的建议是:首先坚持使用适度的默认值或较低的值(例如64MB)。然后,通过实际的基准测试和监控,仅在能够明确证明提高该值能带来可测量的性能收益时,才谨慎地进行调整。数据库的性能调优是一门精细的科学,而非简单的资源堆砌。
扩展思考:
需要打开眼界,具体问题具体分析。例如,在创建某些特殊类型的索引(如用于向量搜索的HNSW图索引)时,情况可能完全相反。maintenance_work_mem可能是越大越好,因为完全在内存中构建图结构(in-memory build)与超出内存后转为增量插入(insertion-based build)是两套完全不同的算法逻辑,后者的速度可能慢几个数量级。这再次强调了基于工作负载特性进行针对性调优的重要性。
 发表于 2025-12-10 03:27:22
|
查看: 197|
回复: 0
发表于 2025-12-10 03:27:22
|
查看: 197|
回复: 0
