关键词: MLIR、HLS、高级综合、Dynamatic、编译器基础设施、数据流电路
LLVM 是当前高级综合(HLS)工具的主流底层框架,但其中间表示(IR)难以定制化表达电路语义,而 MLIR 承诺通过自定义方言解决该问题。

本文基于动态调度 HLS 编译器 Dynamatic 的长期开发实践,系统评估在 MLIR 之上构建 HLS 工具的可行性。
研究确认 MLIR 具备模块化架构、降低定制 IR 开发开销、适配学术团队开发等优势,可支撑数据流电路的表示与优化。但团队在工程落地中发现 MLIR 存在四大核心局限:
- MLIR 数值无法为图边添加属性,难以建模内存依赖与控制流边信息;
- 块参数替代 PHI 节点的设计,增加软件转硬件时多路选择器的转换难度;
- 第三方 MLIR-HLS 项目因 LLVM 版本不兼容,存在严重的集成碎片化问题;
- 现有 C 语言前端优化能力不足,导致项目仍需依赖 LLVM 并采用复杂变通方案。
这些问题并非仅存在于 HLS 领域,对通用 MLIR 编译器开发同样具有参考价值。本文总结工程实践经验,为 MLIR 社区优化与未来 HLS 工具基础设施选型提供关键依据。
一、引言
LLVM 项目[1]是众多开源与商用高级综合(HLS) 项目[2-7]的基础,这类工具负责将软件高级代码编译为寄存器传输级(RTL) 电路。
然而,LLVM 并非 HLS 工具的理想选择[8]:其 IR 无法定制化表示电路结构,迫使 HLS 工具自行开发难以复用的定制化电路 IR。
MLIR [8,9]承诺解决这一问题:它提供了一套标准化方式,用于定义、创建、分析和转换自定义 IR 操作。借助 MLIR,HLS 开发者可以突破 LLVM IR 的刚性限制:既能定义支持高层变换的高级 IR,也能定义具备电路语义的底层IR。对于自定义 IR,MLIR 提供了创建、操作 IR 对象、转储与解析文本格式等默认 C++ 接口,大幅降低实现开销,并促进基于 MLIR 的工具之间的互操作性。
作为 Dynamatic[4,5]——一款基于 MLIR 的 HLS 工具——的核心开发者,我们认可并充分利用了 MLIR 的上述优势。但同时,我们也发现 MLIR 的部分特性为开发带来了阻碍。
本文向社区分享我们在 MLIR(版本 d8eb4ac)中遇到的问题,涵盖 IR 定义、分析、变换,以及不同基于 MLIR 的 HLS 项目间的集成。我们认为这些观察具有普适性,并非仅针对基于 MLIR 的 HLS 项目。希望这些发现能为 MLIR 社区带来新的思考与讨论,帮助开发者为未来的 HLS 工具做出更合理的决策。
二、背景
本节介绍 MLIR 与 Dynamatic 的相关背景知识。
MLIR[9]是一套编译器基础设施,支持定义自定义 IR(称为方言 Dialect ,MLIR 中用于承载领域特定语义的中间表示集合)与变换 Pass。IR 由操作(Operation)构成,操作会消费与产生数值(Value)。
Dynamatic 用于生成数据流电路(Dataflow Circuits,基于数据驱动执行、无需固定时钟调度的硬件电路) [10,11],这类电路由指令粒度的数据流单元通过握手通道连接而成;数据被封装在令牌(Token)中,通过握手通道传输。在数据流电路中,操作只要输入有效就会立即执行。因此,Dynamatic 生成的动态调度电路,在控制流或内存访问模式不可预测的场景下具备性能优势[12-14]。Dynamatic 是基于 MLIR 的编译器:它在专用的握手协议方言(Handshake Dialect) 中,将数据流单元与通道分别表示为 MLIR 的操作与数值。
Dynamatic 已从研究原型逐步成熟:它成为大量学术论文的基础实现[11-37],其中多数成果已整合到主 HLS 流程中[11-13,15-16,21-25,28,32]。我们在多个技术会议上开展了教程与技术分享[5,38]。Dynamatic 主干分支每月合并约 30 个拉取请求(PR),每个 PR 都通过自动化 CI/CD 流水线监控,避免编译错误或性能退化。经验不足的开发者提交的代码贡献,会收到详细的评审与反馈。
三、学术环境下构建基于 MLIR 的 HLS 编译器
我们认可在学术场景中,以 MLIR 为基础开发 HLS 项目具备显著优势。Dynamatic 主要由学生开发者完成,团队成员多为电气工程背景,并非专业软件开发人员,通常不了解软件工程最佳实践。
MLIR 帮助我们克服了这一挑战:它直观展示了复杂面向对象编程架构的实际工作方式,其模块化设计启发我们打造了易理解、模块化的工具。这些优势让我们能将更多开发精力投入到 HLS 专属功能的实现中。
但我们也发现,MLIR 的部分特性为 HLS 工具带来了阻碍,下文将详细展开。
四、MLIR 对开源 HLS 项目的局限及 Dynamatic 中的案例分析
本节讨论在 MLIR 之上构建 Dynamatic HLS 工具时遇到的问题。
4.1 MLIR 数值不适合建模图边
将软件 IR 或电路建模为图是行业通用做法[39]。部分信息天然属于节点,另一部分则属于边。MLIR 允许在操作上添加注解(称为属性(Attribute)),但无法为表示操作间数据交互的 MLIR 数值(Value)附加任何属性。那么,MLIR 的 HLS 框架该如何注解边信息?
案例 1:内存依赖
图 1 展示了一段 C 程序与对应 MLIR 代码的片段。

store3与下一次迭代的load2之间存在潜在的写后读(RAW,Read-After-Write,内存访问的核心依赖关系) 依赖。这类依赖通常由软件 IR 分析得到,会在存储与加载操作间的依赖边上标注依赖距离,并作为 HLS 调度约束保证操作执行顺序正确。由于 MLIR 不允许为边或操作对添加注解,这类信息只能以非标准、不直观的方式表示。
Dynamatic 通过别名分析与多面体分析(Polyhedral Analysis,用于循环优化与内存依赖分析的编译技术) 确定内存访问间的依赖对[13,15]。为在 HLS 流程中保留该信息,Dynamatic 为每个操作分配唯一名称,在整个 HLS 流水线中维护该名称,并以可读性差的格式表示依赖关系。为保证正确性,Dynamatic 还需通过确保所有变换都不破坏操作名称的成对有效性,来验证依赖信息的合法性。
案例 2:软件性能剖析记录
软件性能剖析常用于 HLS 中确定操作执行次数与序列(例如用于早期性能评估或对高频执行代码做针对性优化)。尽管这类信息天然属于基本块间的控制流边,但 MLIR 中没有标准化方式为控制流边添加注解。
Dynamatic 依赖软件性能剖析识别需要优先优化的高频执行循环[16,22]。这类信息本可记录在分支单元的输出边上(见图 2b 中的cond_br节点),但由于 MLIR 不支持数值注解,Dynamatic 只能通过外部 CSV 文件存储该信息。
MLIR 若能完善边注解支持,将有效解决这类问题。
4.2 块参数对 HLS 转换是否便捷?
在 HLS 流程中,需要将软件表示转换为电路,尤其要将静态单赋值(SSA,每个变量仅被赋值一次的 IR 设计) 的 PHI 节点(表示条件赋值)转换为多路选择器。在 MLIR 中,这一转换是否直观?
案例 3:将块参数转换为多路选择器
图 2a 展示了 ControlFlow 方言(MLIR 内置的、用于表示串行程序的方言)中的一个基本块:它以标识bb1开头,携带块参数(%3, %4),以条件分支结尾。MLIR 用这类块参数表示 PHI 节点[40]。这种表示方式在软件转电路的过程中存在以下问题:
(a) 块参数是无生产者的数值;
(b) 分支指令收集输出数值,但这些数值与后继基本块无直接关联。
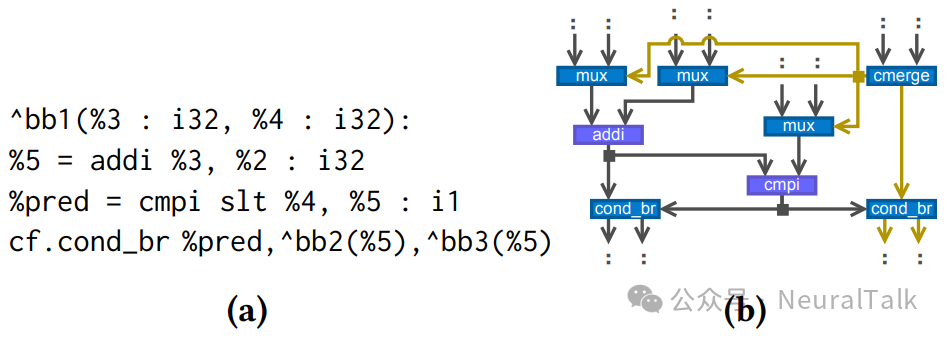
第一个问题导致模式重写(Pattern Rewriting,MLIR 中方言间转换的标准方法) 难以适配该转换——因为没有可匹配的操作。第二个问题让多路选择器输入的定位变得不必要地复杂:与 LLVM 的 PHI 节点(可直接获取其他基本块的输入数值)不同,MLIR 中需要先定位父基本块、分支指令,再获取分支输入的数值。
Dynamatic 使用 MLIR 的模式重写完成该转换,我们承认该方案并非最优——因为重写需要作用于整个函数(违背了局部重写规则的设计初衷)。
4.3 我们解决了软件碎片化问题吗?
MLIR 承诺通过让编译器项目复用彼此的变换 Pass,解决软件碎片化问题。这在 MLIR 官方仓库内或许成立,因为维护者对模块协同方式有统一规划。但大量项目并未合入 MLIR 上游,例如 CIRCT[41]、Polygeist[42]、Dynamatic[4]、MLIRAIE[43]等。我们能否无缝集成这些项目?
案例 4:为两个 GitHub 仓库维护的方言实现变换 Pass
图 3 展示了两个基于 MLIR 项目的简化架构,这些项目分别实现了方言 A 与方言 B。
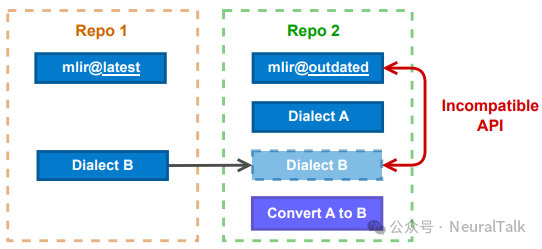
假设我们要实现一个新的 MLIR Pass,将方言 A 转换为方言 B。若方言 A、B 的实现依赖两个 API 不兼容的 LLVM 项目(MLIR 版本不一致导致编译错误),该功能在理论上无法实现。
Dynamatic 实现了一个定制化转换 Pass,将握手协议方言转换为 XLS MLIR 方言[44]。由于我们无法持续将 Dynamatic 的 LLVM 版本与每日更新的 XLS 保持同步,该功能极易过时失效。
4.4 是否有优质的 HLS C 前端助力新型 HLS 工具开发?
HLS 前端负责将 C 代码转换为 IR、执行 IR 优化,并为电路生成标注关键信息。MLIR 是否存在满足所有需求的 C 前端?
案例 5:C 到 MLIR 转换的现状
已有部分项目实现 C 到 MLIR 的转换:
- Polygeist 将 C 抽象语法树(AST)转换为 MLIR 的 SCF 方言;
- Clang 中的 CIR 项目将 C AST 转换为 CIR 方言(建模 C 语言语义的方言)。
这些方案单独使用时,无法提供细粒度的 IR 优化,竞争力弱于基于 LLVM 的 HLS 编译器前端。
案例 6:对 LLVM 的依赖
由于 LLVM 提供了一套成熟、经过充分验证的 IR 优化能力,大多数基于 MLIR 的项目最终会将自定义方言降级为 LLVM IR,以复用 LLVM 的优化能力。
这种复用 LLVM IR 的能力,降低了在 MLIR 中重复实现同类优化的动力。但遗憾的是,这也将 MLIR 原本试图规避的所有 LLVM 局限性重新引入了编译流水线。
由于现有 MLIR C 前端的竞争力不如基于 LLVM 的方案,Dynamatic 仍需依赖 LLVM IR 完成该环节。我们不得不通过定制化方案实现内存分析,并从原始 C 代码中推导数组大小——这类方案在僵化的 LLVM 框架中难以实现,却能在 MLIR 编译流程中自然适配。
五、超越 HLS 的普适性
尽管本文聚焦于 Dynamatic 的特定场景与 HLS 实践,我们认为上述问题具有普适性,并非仅针对基于 MLIR 的 HLS 项目:
- 软件与硬件编译器都会频繁使用边专属信息(如内存依赖、分支概率),都会受 4.1 节所述 MLIR 表达能力限制的影响;
- 4.2 节的 SSA 挑战主要面向硬件领域,但缺少 PHI 节点也会给软件编译器中基于使用-定义链与数据依赖的 IR 优化、分析带来麻烦;
- 4.3 节的软件碎片化问题完全通用,适用于所有 MLIR 项目;
- 所有以 C 为输入语言的编译流程,都会受 4.4 节所述局限性影响。
因此,我们认为解决这些问题将惠及整个 MLIR 社区。
结论
综上,本文基于 Dynamatic 编译器的开发实践,系统总结了在 MLIR 框架上构建高层次综合工具所面临的若干关键挑战。
尽管 MLIR 通过可扩展的方言机制和模块化架构,为硬件编译器提供了相较于 LLVM 更为灵活的中间表示支撑,显著降低了学术环境下复杂编译器项目的开发门槛,但在实际应用中,MLIR 在边信息建模、SSA 表示向硬件语义的转换、跨项目复用与版本同步、以及 C 语言前端生态的成熟度等方面仍存在明显局限。这些问题迫使开发者采用大量非标准且易碎的变通手段,影响了工具的可维护性与可扩展性。
作者指出,上述挑战不仅局限于 HLS 领域,对更广泛的软硬件编译器设计亦具有普遍参考意义。通过分享这些经验,本文旨在引发 MLIR 社区对基础设施设计的深入讨论,推动未来编译器工具链在表达能力、模块协作与前端完备性等方面的持续演进,从而为构建更高效、可复用的开源HLS工具链奠定基础。
参考文献


本文的深度技术探讨与多角度分析,旨在为 云栈社区 的开发者们提供编译器基础设施选型与设计的一手经验参考。
 发表于 2026-3-26 04:25:07
|
查看: 163|
回复: 0
发表于 2026-3-26 04:25:07
|
查看: 163|
回复: 0
