当我们团队费尽心力完成了数字人形象的克隆与实时渲染引擎的对接,以为将渲染画面接入客户端、推上APP就能大功告成时,现实给了我们一记重击。测试中的直播延迟高达10秒、画面卡顿掉帧,并且几小时后就会中断。更糟糕的是,当我们试图同时开启50个直播间时,推流服务直接崩溃了。
这让我们清醒地认识到:让一个数字人动起来是技术演示,让一百个数字人7×24小时稳定“工作”则是庞大的系统工程。 数字人直播的后端,远比想象中复杂。
与真人直播不同,数字人直播有几个非常棘手的特点:
- 直播超过10小时必断流。
- 用户打开首屏,必定会卡顿5秒以上。
- 端到端的延迟稳定在10秒以上。
- 日志里满是内存泄漏和推流超时的错误。
一、数字人直播架构设计与技术选型
一个典型的直播系统包含三个核心环节:推流(内容生产端将音视频数据上传)、直播服务(服务器接收、处理并分发流)、拉流(观众端请求并播放流)。下面将详细介绍我们是如何为数字人场景进行技术选型的。
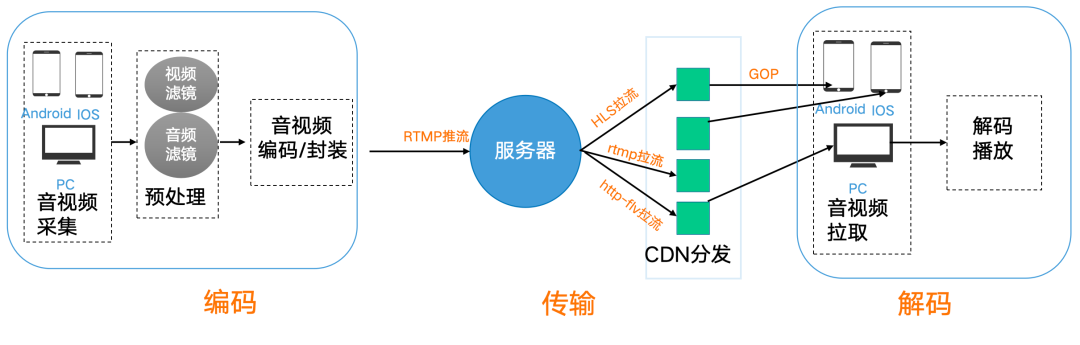
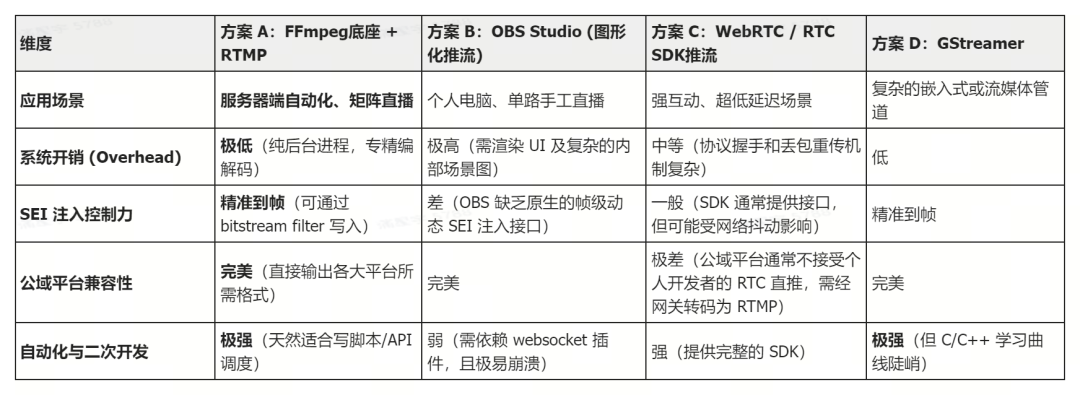
1.1 编码推流选型:为什么是FFmpeg + RTMP?
对于真人直播,带图形界面的OBS Studio是常用工具。但面对需要7×24小时运行的数百个数字人直播间,OBS高昂的资源开销和极差的自动化支持简直是灾难。
我们需要的是无头化、无需人工干预的底层进程。因此,我们果断选择了 FFmpeg + RTMP 方案。它就像一个高效的“后台工人”,资源占用极低,天生适合通过脚本进行批量调度。更重要的是,它能像手术刀一样精准,将商品弹窗等动态信息通过SEI(Supplemental Enhancement Information)精准注入到视频流的每一帧,完美满足数字人自动化直播的严苛要求。
以下是几种常见方案的对比:
1.2 直播服务选型:为什么选择SRS?
如果直接采购大厂的云直播服务,500个直播间全天候运行的账单堪称天价。而使用老牌的开源方案Nginx-RTMP,其并发能力和对多协议(特别是WebRTC)的原生支持又显得力不从心。
经过综合评估,我们锁定了开源流媒体服务器—— SRS。它不仅是免费的,更是一个单进程就能承载数千路并发的“性能怪兽”,完美契合我们低成本、云原生部署的需求。最关键的是它强大的协议“转换”能力:可以稳定接收推流,并瞬间分发为RTMP、HLS、WebRTC等多种格式,成为我们直播架构的基石。
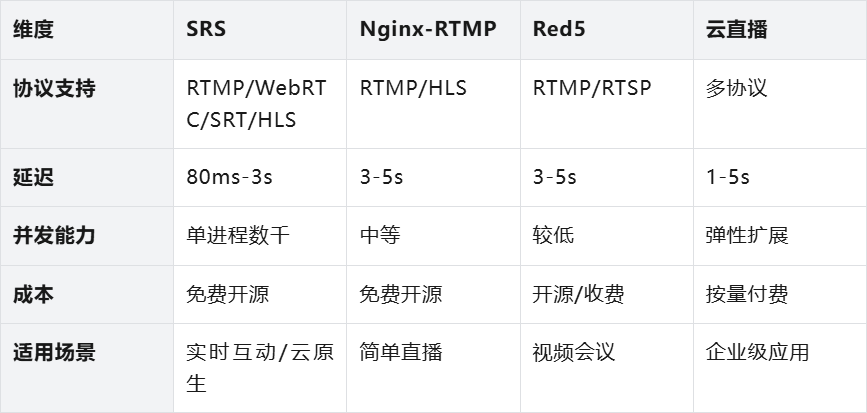
结论:SRS是当前开源流媒体服务器的首选方案,特别适合需要低延迟、多协议、云原生部署且预算有限的场景。
1.3 拉流协议栈选型:分场景组合拳
谈到拉流,技术圈常言必称WebRTC的毫秒级延迟。但我们的数字人是按照预制脚本进行单向播报的,不存在真人直播的实时互动需求,延迟两三秒观众完全无感。
因此我们没有盲从,而是根据实际场景打出了一套 组合拳:
- 对外观众:主推稳定成熟的 RTMP,并搭配兼容性极佳的 HLS,确保在各种终端上都能流畅播放。
- 对内监控:将 WebRTC 作为内部运营监控的“特供通道”。运营人员需要同屏监看数十个直播间,利用WebRTC原生
<video> 标签拉流,可以节省大量浏览器内存,直接避免了监控大屏的崩溃风险。

关键决策:
- 推流用RTMP:数字人画面是程序化生成,不存在“摄像头采集延迟”,RTMP约1-3秒的延迟完全可以接受,且稳定性远超WebRTC。
- WebRTC仅用于监看:运营同时观看多个直播间时,WebRTC的
<video> 标签比传统的FLV方案更节省浏览器资源。
- HLS用于终端拉流:直播脚本本身是基于产品介绍,需要完整播放,本身就会有延迟。HLS结合CDN适配性好,能保证最终用户的观看体验。
1.2 落地架构拓扑设计
基于以上选型,我们设计了如下分层架构:
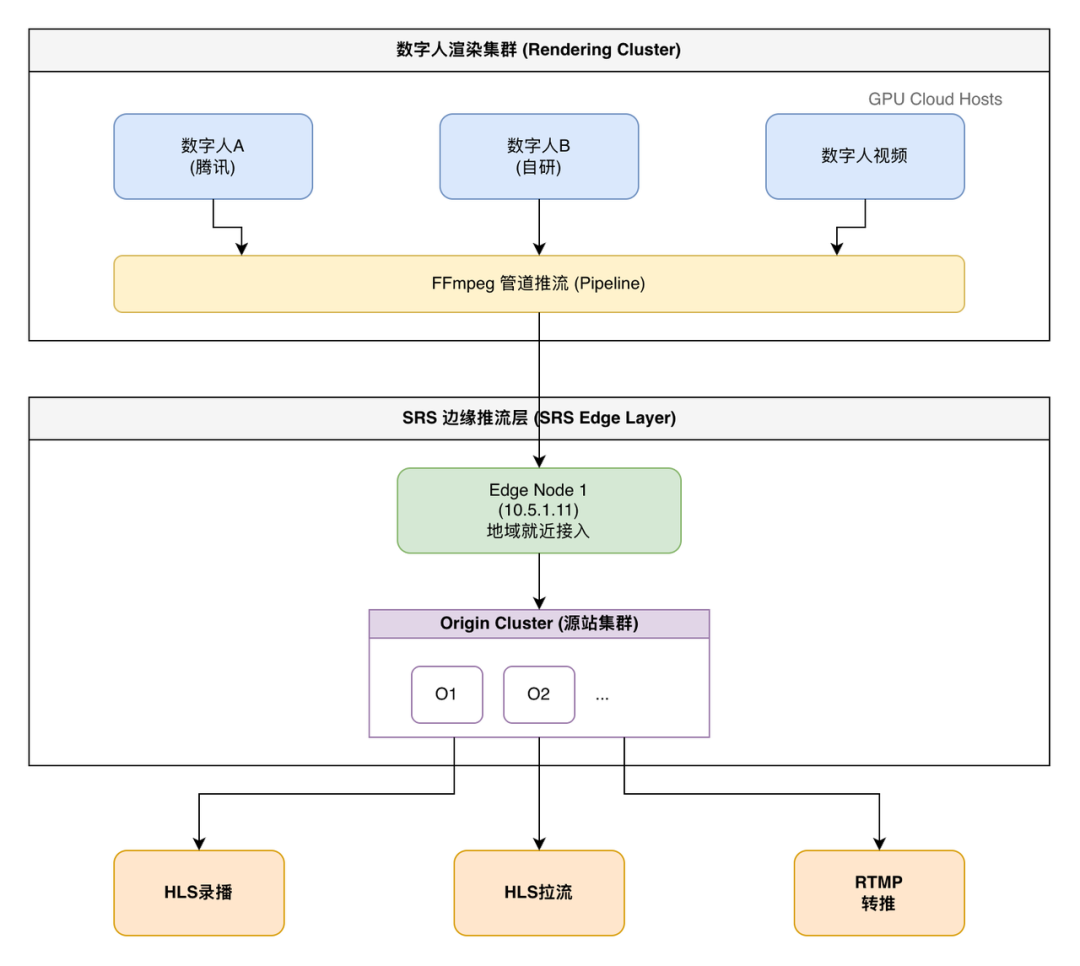
分层逻辑:
- 源 (Source):数字人渲染引擎进行推流。
- 边缘层 (Edge Layer):部署在多地域,实现推流端就近接入,降低公网传输延迟。
- 源站层 (Origin Layer):集群汇聚来自各边缘节点的流,进行统一处理、录制和转推。
- 分发层 (Distribution Layer):通过SRS的Forward等功能,将流转推到CDN或第三方平台。
二、数字人推流端对接实战
2.1 编码推流配置
数字人渲染引擎需要通过FFmpeg将画面推送到SRS服务器。
- 编码器选择:
libx264:CPU软编码,画质好,适合云主机(将GPU算力留给渲染任务)。h264_nvenc:如果渲染节点的GPU有剩余算力,可以使用NVENC硬件编码以降低CPU负载。
- GOP设置:
- 数字人画面变化较小,我们设置
-g 50(假设帧率25fps,即2秒一个关键帧)。
- 大多数直播平台要求2-4秒的GOP,设置太短浪费带宽,太长则首屏打开延迟高。
- 断线重连:
- FFmpeg进程遇到网络抖动可能会直接退出,需要在外部用脚本监控并自动重启。
2.2 实时信息嵌入 (SEI)
直播中常需要实时显示商品信息、合规声明等,要求准确且及时。我们通过SEI技术实现动态信息的帧级嵌入。
SEI实现动态信息嵌入
SRS支持在流中插入SEI信息。推流时可通过FFmpeg注入:
ffmpeg ... -c:v libx264 -sei_side_data on -metadata comment="ProductId=12345" -f flv rtmp://srs-server/live/stream1
直播商品信息嵌入
为了更精准地控制,我们通过JavaCV等库在编码阶段动态插入SEI信息,确保当前播放的视频帧与需要显示的商品信息强一致。
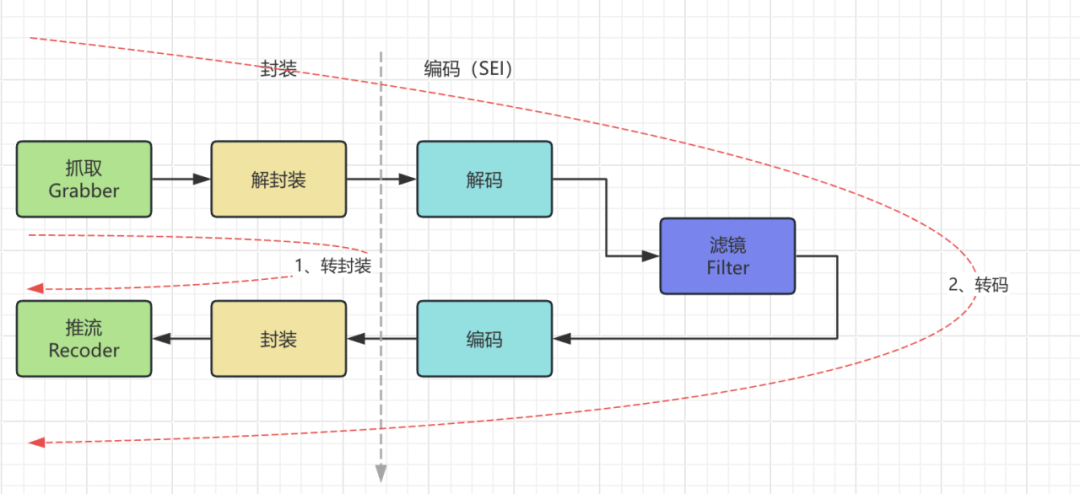
三、SRS生产环境搭建与性能调优
搭建SRS集群远不是“复制粘贴配置文件”那么简单。我们经历了从高延迟、易崩溃到稳定高性能的优化过程。
3.1 基础环境与服务器配置
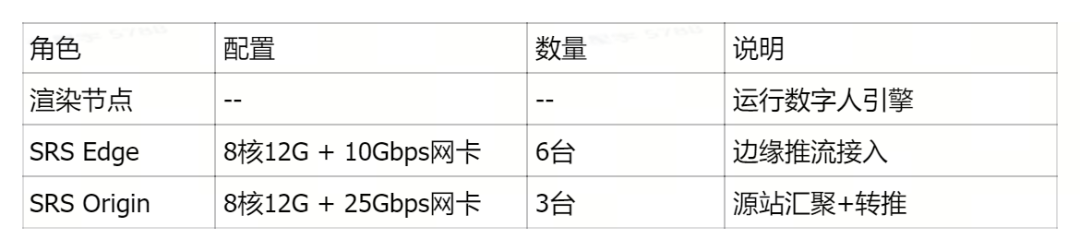
针对I/O密集型且大流量的场景,需要对系统内核参数进行专项优化 (/etc/sysctl.conf):
- 高吞吐量:增大网络缓冲区。
- 实时性:启用BBR拥塞控制算法。
- 应对突发流量:调高连接队列长度,避免丢包。
- 高并发:大幅提升系统及进程的文件句柄数限制。
# 网络缓冲区大小(针对高吞吐量)
net.core.rmem_max = 134217728
net.core.wmem_max = 134217728
# 为单个TCP连接设置内存范围,最大128MB
net.ipv4.tcp_rmem = 4096 87380 134217728
net.ipv4.tcp_wmem = 4096 65536 134217728
net.core.netdev_max_backlog = 5000
# 启用BBR拥塞控制,提升弱网下的稳定性和降低延迟
net.ipv4.tcp_congestion_control = bbr
# 文件句柄限制(应对高并发连接)
fs.file-max = 2097152
fs.nr_open = 2097152
3.2 SRS Edge节点配置 (边缘推流接入)
Edge节点负责就近接收推流,并转发到Origin集群。
- 核心能力:配置上游Origin集群地址。
- 实时监控:启用FLV和WebRTC输出,供内部监控台使用。
- 可用性:设置较短的转发超时时间,防止因Origin故障导致阻塞。
# edge.conf
vhost __defaultVhost__ {
mode remote;
origin *:1935 *:1935; # Origin集群地址
# 快速失败,防止阻塞
forward_timeout 5s;
# 启用HTTP-FLV,用于监控播放
http_remux {
enabled on;
mount [vhost]/[app]/[stream].flv;
hstrs on;
}
# 启用WebRTC播放
rtc {
enabled on;
rtmp_to_rtc on;
}
}
3.3 SRS Origin节点配置 (源站汇聚+转推)
Origin节点是核心,负责流的汇聚、录制、分发和转推。
- 低延迟播放:优化
play配置,关闭GOP缓存,控制队列长度。
- HLS录制与分发:配置HLS切片,作为主要的拉流协议之一。
- 多平台分发:使用
forward模块将流转推到抖音、视频号等第三方平台。
# origin.conf
listen 1935;
max_connections 5000;
worker_threads 8; # 绑定8核CPU
play {
# 关闭GOP缓存,降低延迟
gop_cache off;
# 队列长度控制(缓冲约10帧)
queue_length 10;
}
vhost __defaultVhost__ {
# HLS配置
hls {
enabled on;
hls_path /data/recordings;
hls_fragment 2; # 2秒切片
hls_window 3600; # 保留1小时
}
# 转推其他平台
forward {
enabled on;
destination rtmp://platform-a.com/live/stream_key;
destination rtmp://platform-b.com/live/stream_key;
}
}
3.4 SRS性能调优实战:从10秒延迟到3秒
3.4.1 延迟优化三板斧
- 第一斧:推流端GOP设置
- 问题:GOP设置不合理(如默认10秒),播放器需要等待下一个关键帧才能开始播放,导致首屏打开极慢。
- 解决:将GOP设置为2秒(
-g 50 @25fps)。效果:首屏加载从10秒降至毫秒级,基本实现“秒开”。
- 第二斧:SRS启用低延迟模式
- 第三斧:前端播放器配合
- 在用户进入直播页面之前,就提前预加载拉流地址,进入后直接开始拉流,避免页面加载后再去请求地址带来的延迟。
3.4.2 高并发优化
# srs.conf
listen 1935;
max_connections 10000; # 提高最大连接数
worker_threads 8; # 等于CPU核心数
# 高并发时日志是性能杀手,调整为WARN级别或输出到控制台
srs_log_level warn;
srs_log_tank console;
3.4.3 监控与告警
SRS自带统计API:
# 查看当前推流统计
curl http://srs-origin:1985/api/v1/summaries
# 关键指标:CPU占用、内存、连接数、出入带宽
集成Prometheus + Grafana + 飞书报警:
通过srs-exporter采集指标,并配置告警规则。
scrape_configs:
- job_name: 'srs'
static_configs:
- targets: ['srs-origin:1985']
metrics_path: '/api/v1/metrics'
关键告警规则:
- 推流断开:某路流的
active 状态变为 false。
- 延迟过高:帧率持续低于20fps超过30秒。
- 带宽打满:出网流量超过预设阈值(如8Gbps)。
四、多平台分发与合规接入
4.1 SRS Forward多路转推
核心需求:将一路数字人流,同时推送到抖音、视频号、淘宝等多个平台。
我们对比了多种方案:
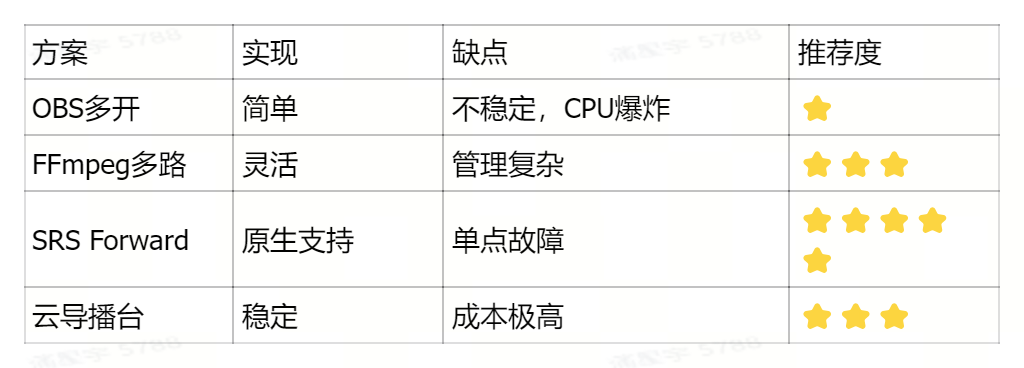
最终选择 SRS Forward,因其原生支持、稳定且易于管理。
4.2 动态推流码管理
各平台的推流地址和密钥通常具有有效期,需要一个中间服务来动态获取和更新SRS的转发目标。
# Python示例:获取平台推流地址后通过SRS API动态更新转发配置
import requests
def update_srs_forward(stream_key, platform_urls):
"""
通过SRS HTTP API动态添加转推目标
"""
srs_api = "http://srs-origin:1985/api/v1/clients"
# 1. 查询当前流ID
r = requests.get(f"{srs_api}?count=100")
clients = r.json()['clients']
# 2. 找到对应stream_key的客户端,发送forward命令
for client in clients:
if client['name'] == stream_key:
# 通过API触发forward(SRS 6.0+支持)
requests.post(f"{srs_api}/{client['id']}/forward", json={"destinations": platform_urls})
break
五、容灾架构与成本控制
5.1 高可用设计
- 推流端双活:数字人渲染端同时向两个不同的Edge节点推流,Origin层通过健康检查自动切换主源。
- SRS热升级:利用
SIGUSR2 信号实现不中断连接的服务重启与升级。
- 降级预案:当SRS集群整体故障时,主动关闭直播入口,引导用户,避免体验雪崩。
5.2 成本优化

节省关键点:
- 带宽成本:利用CDN进行分发,回源流量集中,极大降低了机房出口带宽费用。
- 计算成本:在Kubernetes上部署,利用HPA(水平Pod自动伸缩)根据推流数自动扩缩容SRS实例。
- 存储成本:直播录制文件直接转存至对象存储的低频访问层,显著降低存储费用。
六、避坑指南
6.1 离线视频动态切换推流
目标:实现7*24小时直播,并能根据用户问答或商品切换动态插播不同的视频片段。
挑战:使用FFmpeg的concat滤镜基于本地文件列表进行动态插入非常复杂,需要精确监控推流进度。
解决方案:化被动为主动。我们基于JavaCV,实现了一个HTTP协议的视频源。推流进程通过请求本地HTTP接口来获取下一个应该播放的视频链接,从而实现精准、灵活的动态视频切换。
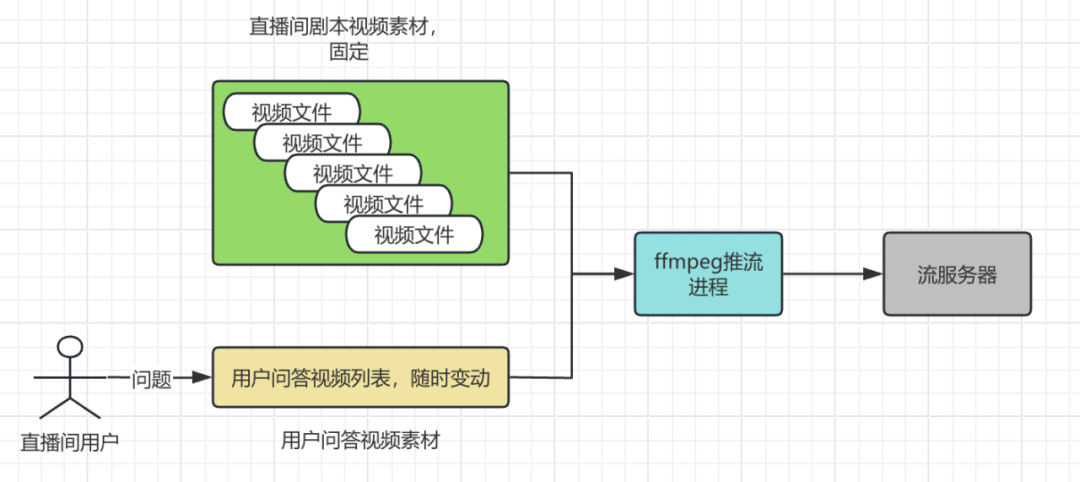
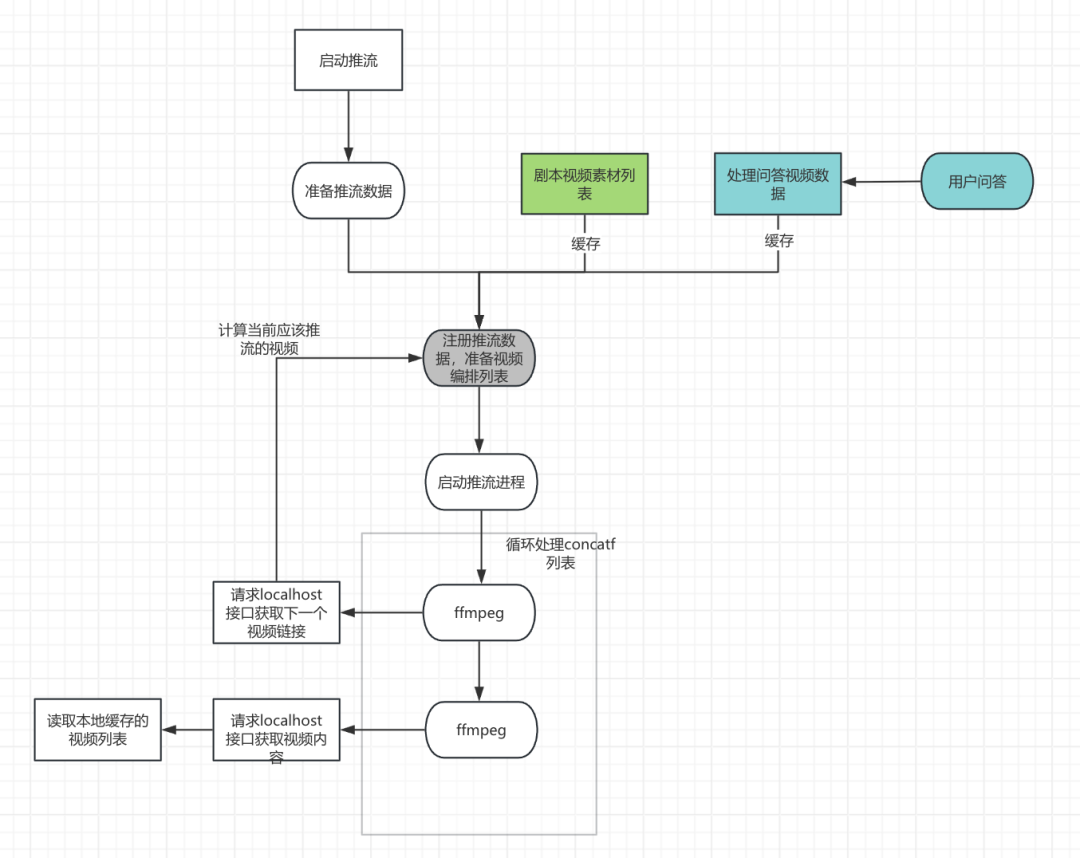
结果:用相对简单的方案实现了稳定的动态推流,能够感知上一个视频是否播放完毕,并能监控异常视频,及时报警。
6.2 SRS流服务器常见坑点
-
坑1:WebRTC播放黑屏
- 现象:数字人画面在WebRTC播放器中黑屏,但RTMP/FLV播放正常。
- 原因:FFmpeg编码的Profile级别(如High)过高,某些浏览器解码器不支持。
- 解决:推流时强制使用基线配置
-profile:v baseline -level 3.1。
-
坑2:长时间推流内存泄漏
- 现象:SRS运行数日后内存占用从2G暴涨到20G。
- 原因:早期版本(如5.0以下)的DVR(录制)模块可能存在内存泄漏。
- 解决:升级到最新稳定版,或设置每日定时通过
SIGUSR2 信号优雅重启SRS进程。
-
坑3:多路推流卡顿
- 现象:单SRS节点推流路数较多(如50路)时,后半部分流出现卡顿。
- 原因:SRS默认
chunk_size (60000) 较小,在高并发下可能导致TCP包过于碎片化。
- 解决:在
srs.conf 中适当调大 chunk_size 128000。
-
坑4:音视频不同步
- 现象:数字人说话口型对不上音频。
- 原因:Unity等渲染引擎输出帧率不稳定,而音频采样率固定。
- 解决:在SRS端配置
aac_sync on,或在FFmpeg推流时使用 -async 1 参数进行强制同步。
结语:数字人直播的下一站
基于SRS自建直播服务体系,让我们在数字人直播赛道上获得了成本、延迟和可控性的三重优势。但这并非终点,技术仍在快速演进:
- 协议层:SRT正逐渐替代RTMP成为新的推流标准,SRS 6.0已提供原生支持。
- 编码层:AV1编码相比H.264可节省约30%带宽,但编解码延迟仍需进一步优化。
- 架构层:基于HTTP/3的WebTransport协议可能重塑未来的超低延迟直播架构。
我们的技术栈清单:
- 流媒体服务器:SRS 6.0
- 容器编排:Kubernetes
- 监控体系:Prometheus + Grafana
- 推流工具:FFmpeg 6.0
- 平台接入:SRS Forward + 动态推流码服务
从Demo到真正能扛住生产环境流量的系统,每一步都充满了挑战与权衡。希望我们这套基于SRS和FFmpeg的实战经验,能为正在探索数字人直播或其他大规模流媒体应用的开发者提供一份有价值的参考。技术之路,常备不懈,欢迎在云栈社区交流更多实战心得。
 发表于 2026-4-9 01:40:25
|
查看: 217|
回复: 0
发表于 2026-4-9 01:40:25
|
查看: 217|
回复: 0
