在 Kubernetes 集群中,绝大多数工作负载设计为“常驻型”服务,例如 Deployment、StatefulSet 和 DaemonSet。这些控制器会确保其管理的 Pod 长期运行,一旦 Pod 意外终止,便会立刻重启新的实例。
然而,实际生产环境中还存在另一类截然不同的工作负载:
- 数据初始化
- 离线计算
- 定时备份
- 批量迁移
- 周期性清理日志
这类任务的共同特点是:它们只需要成功执行一次或按周期执行,完成后即可退出。这正是 Kubernetes 中 Job 与 CronJob 资源所要解决的核心场景。
Job 的核心定义
Job 的设计目标非常明确:确保一个任务成功执行完成。它的关注点并非持续运行或高可用,而是 “运行至成功为止”。
如果 Job 创建的 Pod 执行失败(例如,进程异常退出):
- Job 控制器会自动重新拉起新的 Pod。
- 此过程将持续,直到成功完成的 Pod 数量达到预设值。
- 或者,重试次数达到了设定的失败上限。
Job 的三种典型执行模式
1. 单次任务
这是最常见的模式,适用于数据初始化、执行一次性脚本或手动触发的任务。任务 Pod 成功运行结束后,便不会再次重启。
2. 并行任务
适用于大规模数据处理或批量离线计算等场景。通过配置 parallelism (并行度)和 completions (需完成的总次数)两个参数,可以灵活控制批处理的并发规模与任务总量。
3. 支持失败重试的任务
当任务可能因网络波动、依赖的外部服务暂时不可用或计算逻辑存在非稳定因素而失败时,Job 的重试机制显得尤为重要。只要未成功,Job 就会按照策略进行重试,非常适合此类容错需求较高的场景。
为什么不能用 Deployment 替代 Job?
一个常见的误区是试图用 Deployment 来运行一次性任务,认为“让 Pod 跑完不重启就行”。这混淆了两者的设计哲学:
- Deployment 的逻辑:确保指定数量的 Pod 副本 持续运行。它只关心 Pod 是否“存活”,不关心进程的退出状态。Pod 退出即被视为故障,随即触发重启。
- Job 的逻辑:确保其 Pod 成功执行指定次数后正常结束。它关心的是进程的退出码(
exit code 0 代表成功)。
简而言之,Deployment 没有“任务成功”的概念,只有“存活”与“死亡”的状态;而 Job 则是为“完成任务”而生。在复杂的微服务或后端系统中,清晰地划分常驻服务与临时任务,是保障系统稳定性的重要运维/DevOps实践。
CronJob:为 Job 加上时间表
CronJob 是 Job 的定时控制器,你可以将其理解为 “按照时间规则自动创建 Job 的调度器”。
典型应用场景包括:
- 每日凌晨进行数据库备份。
- 每小时清理一次临时文件。
- 每 5 分钟执行一次数据对账任务。
CronJob 主要管理两件事:
- 根据 Cron 格式的时间表达式创建 Job。
- 控制同时允许运行的历史 Job 数量(并发策略)。
CronJob 的三个关键调度策略
1. 并发策略 (concurrencyPolicy)
Allow(默认):允许新任务与旧任务重叠执行。Forbid:如果上一次的任务尚未执行完毕,则跳过本次调度。Replace:如果旧任务仍在运行,则将其取消并替换为新的任务。
建议:对于涉及数据写入、状态更新的任务,优先使用 Forbid 策略,以避免数据竞争或状态混乱。
2. 启动延迟容忍 (startingDeadlineSeconds)
当集群负载过高或调度器出现延迟时,可能导致任务无法准时启动。此参数设定了任务调度的最后期限。如果超过此时间窗口任务仍未启动,则该次调度将被直接放弃,且 不会补跑。这是生产环境中避免历史任务堆积、减轻系统压力的重要配置项。
3. 历史任务清理
CronJob 每次执行都会创建对应的 Job 对象,长期积累会导致 API Server 中存储大量过期对象,可能引发性能问题。务必通过 successfulJobsHistoryLimit 和 failedJobsHistoryLimit 字段,明确设置成功和失败 Job 的历史记录保留条数。
Job / CronJob 的成功标准
Kubernetes 判断一个 Job 是否成功的唯一标准是:其 Pod 中的主容器是否以 exit code = 0 的状态正常退出。
这与日志内容、输出文件无关。因此,最佳实践是:
- 在任务脚本或应用程序中正确使用
exit 0(成功)和 exit 1 或其他非零值(失败)。
- 不要“吞掉”异常,确保错误能正确地反映在退出码上。
- 尽量在应用层实现明确的返回码逻辑。例如,使用 Go 编写任务时,应利用
os.Exit() 清晰地传递状态。
任务调度的四条最佳实践
1. 确保任务幂等性
Job 可能因重试、被替换(CronJob 的 Replace 策略)而重复执行。因此,任务逻辑必须设计为 幂等,即多次执行与一次执行的效果相同,这是编写可靠 Job 的前提。
2. 合理设置重试上限 (backoffLimit)
默认的重试次数(默认为 6)可能并不适合所有业务。
- 设置过少:偶发性失败(如网络抖动)可能导致任务直接失败。
- 设置过多:对于确实无法恢复的错误(如配置错误),会导致无限无效重试,浪费资源。
必须根据任务的具体性质进行调整。
3. 长任务需配置资源限制
Job 中的 Pod 同样会受到资源限制的影响。CPU Throttle 或 OOM(内存溢出)都可能导致任务进程被系统杀死,进而触发 Job 重试。
- 务必设置合理的
requests 和 limits。
- 避免任务 Pod 过度抢占线上业务 Pod 的资源,影响核心服务稳定性。合理的资源规划是云原生/IaaS应用的基础。
4. 强化清理意识
定时任务本身也会产生需要清理的“垃圾”,包括:
- 保留过多的历史 Job 记录(已通过上述策略控制)。
- 任务 Pod 产生的日志(需配置日志轮转或收集)。
- 任务运行时生成的临时数据。
应建立配套的清理机制,定期“打扫”。
常见误用场景
- ❌ 使用 CronJob 来部署需要常驻运行的服务。
- ❌ 使用 Deployment 来运行一次性脚本或初始化任务。
- ❌ 不配置并发策略,导致周期任务重叠执行,引发“任务叠罗汉”。
- ❌ 忽视历史 Job 的清理,导致 API Server 负载过高。
这些问题在开发和测试阶段可能不明显,但一旦在生产环境爆发,往往影响较大。
适用场景快速对照表
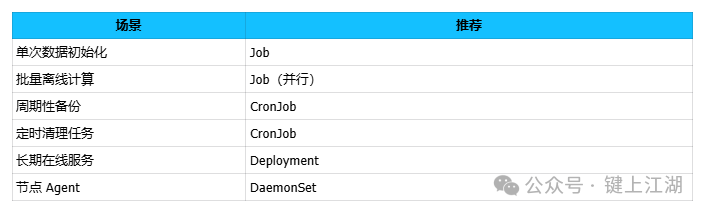
总结
Deployment 关心的是“持续活着”,而 Job 关心的是“成功完成”。CronJob 的本质,只是一个“按时生成 Job 的定时器”。
将适合的任务型工作负载交给 Job 和 CronJob 管理,不仅能更精准地利用 Kubernetes 的调度能力,也能让你的应用架构层次更加清晰、职责更加分明。
 发表于 2025-12-10 03:34:05
|
查看: 203|
回复: 0
发表于 2025-12-10 03:34:05
|
查看: 203|
回复: 0
