很多人认为 KafkaConsumer.poll() 就是消费的全部。你写代码时,是不是也觉得消费流程就是简单的 poll → 处理 → commit 循环?
其实,你写的只是“入口函数”,真正驱动整个消费流程的,是一套复杂的后台系统。许多线上问题,比如 Rebalance 频繁、消费卡顿、Offset 异常,其根源往往不是业务逻辑错误,而是对 Consumer 内部架构的理解偏差。
一、核心架构总览:不只是 poll()
让我们先建立起宏观的认知。一个 Kafka Consumer 实例,远不止一个 poll() 方法那么简单,它内部由多个协同工作的核心组件构成。
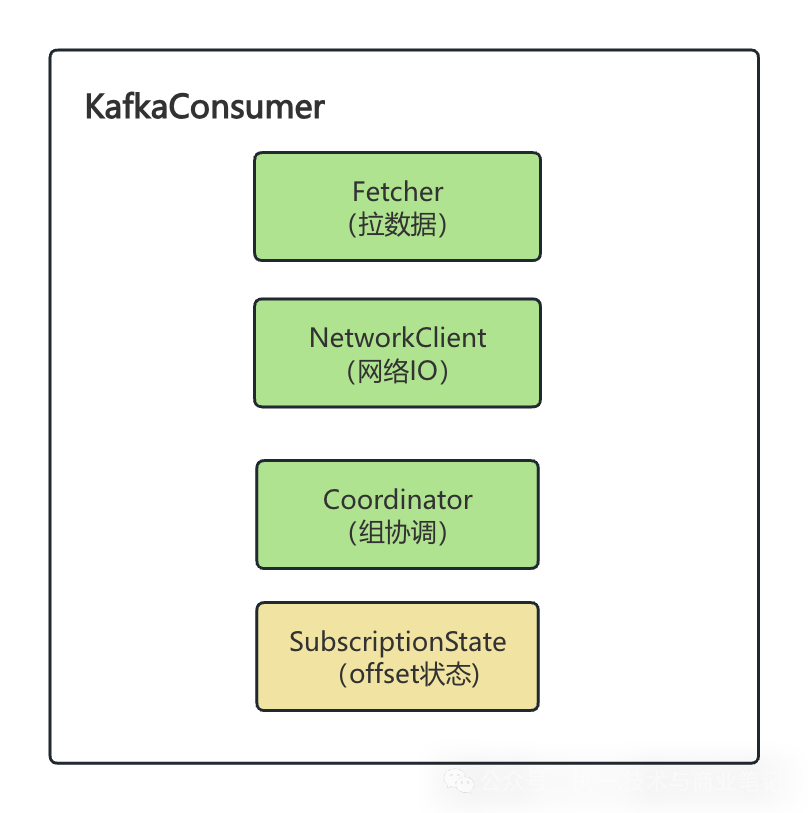
上图清晰地展示了 KafkaConsumer 的主要内部模块:
- Fetcher(拉数据):负责从 Broker 拉取消息的真正“苦力”。
- NetworkClient(网络IO):所有网络通信(心跳、提交Offset、加入组等)的发动机。
- Coordinator(组协调):管理 Consumer Group 成员关系与分区分配的“大脑”。
- SubscriptionState(Offset状态):维护本地消费状态(如分区分配、消费进度)的存储器。
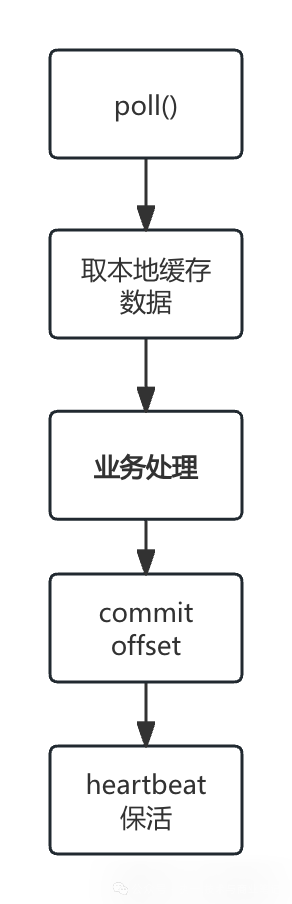
而你调用的 poll() 方法,其主要工作就是从 Fetcher 填充好的本地缓存中取出数据,并驱动后台的协调与心跳任务。下面这张流程图直观地展示了这一循环过程。
二、底层四大核心机制拆解
理解了总体结构,我们来深入看看每个核心组件是如何工作的。
1. Fetcher:真正的“数据搬运工”
这是最大的一个误解:poll() 并不直接向 Broker 拉取数据。
- 真相:
poll() 仅仅是消费的触发器,它从本地缓存(由 Fetcher 维护)中取出数据。真正负责与 Broker 通信、持续发送 FetchRequest 来拉取消息的,是一个或多个后台的 Fetcher 线程。
- 工作流程:Fetcher 线程在后台独立运行,不断向已分配的分区 Leader Broker 发送拉取请求,将获取到的数据存入客户端内存的缓存队列中。当你的业务代码调用
poll() 时,它只是从这个本地缓存队列里取出批量的消息。
- 比喻:
poll() 不是“点外卖”,它只是“开门取外卖”。而 Fetcher 才是那个风雨无阻、持续往返的“外卖小哥”。
2. NetworkClient:统一的网络引擎
无论是 Fetcher 拉数据、Coordinator 发心跳、还是提交 Offset,所有与 Kafka Broker 的网络通信都通过 NetworkClient 进行。
它本质上是一个事件驱动的高性能网络客户端,类似于 Java NIO 的 Reactor 模式,负责管理连接、发送请求和接收响应,是保证通信效率与可靠性的基石。
3. Coordinator:Consumer Group 的“指挥官”
这个组件专门负责管理 Consumer Group 的元数据与协调工作,是 分布式系统 协同的核心体现。它主要处理三件事:
- JoinGroup:Consumer 启动时向 Coordinator 注册,加入消费组。
- SyncGroup:Group Leader(由Coordinator指定)完成分区分配方案后,通过 Coordinator 同步给所有成员。
- Rebalance:当有 Consumer 加入或离开组时,Coordinator 组织所有成员进行分区重平衡。
可以说,Coordinator 决定了“谁”来消费“哪些”数据。
4. SubscriptionState:本地状态记录器
它维护着 Consumer 的本地状态,包括:
- 当前订阅的主题(Topic)和分配到的分区(Partition)。
- 每个分区的消费进度(Offset)。
- Group 的订阅状态(如是否正在 Rebalance)。
本质上,它是一个内存状态机,是 Fetcher、Coordinator 和你的业务代码之间进行状态同步的枢纽。
三、从案例看问题本质
理解了架构,我们就能更精准地定位和解决线上问题。下面这些案例,你是否遇到过?
案例一:消费突然变慢,消息积压(Lag)暴涨
- 现象:监控显示消费滞后(Lag)持续增长,但 Consumer 所在服务器的 CPU 和网络利用率却很低。
- 排查与真相:Fetcher 和 Network 本身无异常。问题可能出在参数配置上,例如
max.poll.records(一次 poll() 最多返回的记录数)设置过小,同时 fetch.min.bytes(服务器收到请求后返回的最小数据量)也设置得很低。
- 结果:这导致 Fetcher 频繁发起网络请求,但每次拉回的数据量很少,网络往返开销占比过高,吞吐量急剧下降。而
poll() 一次能拿到的消息数也有限,业务处理批次太小。
- 解决:根据实际网络和消息大小,调优参数。例如:
fetch.min.bytes=1048576 (1MB),max.poll.records=2000,让每次请求和处理的批量更大,提升效率。
案例二:频繁 Rebalance,导致消费抖动
- 现象:Consumer Group 频繁发生 Rebalance,消费时断时续,监控曲线呈锯齿状。
- 原因:业务处理一批消息的时间超过了
max.poll.interval.ms 参数配置的值。
- 过程:Coordinator 在超过这个时间间隔后仍未收到下次
poll() 调用,会判定该 Consumer 已失效,从而将其踢出消费组,触发 Rebalance,其负责的分区被重新分配给其他活跃成员。
- 解决:
- 适当调大
max.poll.interval.ms 参数,给业务处理留足时间。
- 优化业务逻辑,缩短单批消息的处理耗时。
- 减少
max.poll.records,让单次 poll() 返回的数据量变小,从而缩短处理时间。
案例三:消息被重复消费,数据错乱
- 现象:同一条消息被业务系统处理了多次。
- 原因:在消息处理成功后,提交 Offset(
commitSync/commitAsync)的动作发生延迟或失败。随后,如果发生了 Rebalance,当这个分区被重新分配给另一个 Consumer(甚至是原Consumer重启后)时,它将从上次提交的 Offset 处开始消费,导致已处理但未提交 Offset 的消息被再次消费。
- 本质:这是 Coordinator 的 Rebalance 机制与 Offset 提交机制在协同上出现“间隙”的典型表现。需要确保处理完成与提交 Offset 这两个动作的原子性或更强的一致性。
- 建议:根据业务对“精确一次”语义的要求,选择合适的提交策略(如手动同步提交),并处理好提交异常。
四、必须警惕的边界条件
除了案例,一些特定的边界条件也极易引发问题:
- 边界1:处理时间 >
max.poll.interval.ms
- 后果:Consumer 被踢出 Group,触发 Rebalance,可能导致重复消费(如案例二)。
- 边界2:心跳中断 >
session.timeout.ms
- 后果:Coordinator 判定 Consumer 死亡,触发 Rebalance。确保
heartbeat.interval.ms 设置合理,且网络稳定。
- 边界3:Fetcher 拉取速度过慢
- 原因:网络延迟高,或
fetch.min.bytes/fetch.max.wait.ms 参数设置不合理,导致数据无法快速填充本地缓存。
- 后果:
poll() 调用可能返回空数据,造成消费“假停顿”。
- 边界4:Offset 提交失败
- 原因:提交时发生网络抖动,或在 Rebalance 期间提交。
- 后果:Broker 记录的 Offset 与 Consumer 实际消费进度不一致,引发重复消费或消息丢失(如果提交了未处理的消息的Offset)。
五、回归本质:工程真相
所以,不要再把 Kafka Consumer 简单看作一个“消息读取工具”。它的工程本质是:
一个由“分布式协调系统(Coordinator) + 本地缓存系统(Fetcher + SubscriptionState) + 高性能网络引擎(NetworkClient)”精密耦合而成的复杂客户端。
你调优的每一个参数,都不只是在调整一个“客户端选项”,而是在调整这个微缩分布式系统的运行时行为。这也解释了为什么理解其内部架构如此重要。

六、核心总结
最后,我们用三句话来总结全文精髓:
poll() 仅是入口:它负责从本地缓存取数据和驱动后台任务,真正的数据拉取由独立的 Fetcher 线程完成。- 核心是协同:Fetch(拉取)、Coordinator(协调)、Offset(进度) 三者构成的闭环,才是保障稳定、高效消费的系统核心。
- 调参即调系统:每一个配置参数都在影响这个内嵌的“微缩分布式系统”的行为,理解架构是合理调参的前提。
希望这篇深入的架构拆解,能帮助你从“API调用者”转变为“系统理解者”,从而更好地驾驭 Kafka 这一强大的 消息队列 工具。如果你在实践中有更多心得或疑问,欢迎在 云栈社区 与更多开发者交流探讨。 |  发表于 2026-3-26 17:58:32
|
查看: 138|
回复: 0
发表于 2026-3-26 17:58:32
|
查看: 138|
回复: 0
