这几天在尝试国产大模型对UEFI开发任务的适配度,结果相差很大。GLM5在BIOS里写打砖块,2.5小时完成,编译一次通过,首次运行成功。MiniMax写俄罗斯方块,几个小时都不能正常运行,最终翻车。Kimi写贪吃蛇,踩了几个坑,但最终还是完成了任务,游戏效果还不错。
我用Claude Code + GLM5花2.5小时,在BIOS里写了个中文打砖块游戏
我让 MiniMax 写 UEFI 俄罗斯方块游戏,翻车了
用Kimi-K2.5写个BIOS里运行的贪吃蛇,踩了这些坑
这一次,轮到Qwen了。
这是本系列的第四篇文章。模型选择 qwen3.5-plus,任务是开发一个 UEFI Shell 下的打飞机游戏。同样的规则:Windows 环境仅安装 Visual Studio 2019,本地代码库为零,专业指导基本不提供,让 AI 全程自主完成。
说实话,我对Qwen是有期待的。作为阿里云的拳头产品,在多项评测中表现不俗。然而这次实验的结果,却让人失望。
第一坑:编译困局

第一条指令发出后,Qwen开始干活。
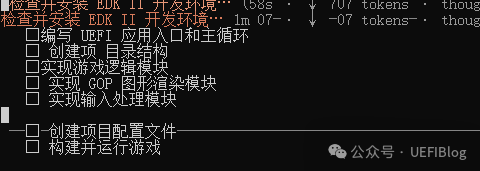
环境搭建出乎意料地顺利。下载 EDK2 源码、配置编译环境、创建项目结构,一切井然有序。这一点与 GLM5 相当,比 MiniMax 和 Kimi 都要好——后两者都在目录创建上“自作主张”,把项目结构搞得乱糟糟的。
Qwen提供的任务清单功能还不错(前面Kimi好像也有)。它会创建一个进度列表,完成一项打一个勾。开发进度一目了然。
但问题很快出现了。
四个小时过去了,应用程序竟然编译不出来。
我查看它在干啥,发现还是中文注释的问题。VS 编译器在地区选择不对的时候,不接受非 ASCII 字符,代码里加了中文注释就会报错。这个问题,GLM5 遇到了,MiniMax 遇到了,Kimi 也遇到了。
但处理方式却天差地别。
GLM5看到出错信息后,会尝试用拼音代替。MiniMax和Kimi会改回英文注释。而Qwen呢?它不会改变代码,一直在尝试修改编译参数。它在编译参数这边反复较劲,各种尝试,各种修改,却始终不得其法。四个小时过去了,编译依然失败。
我终于忍不住,Ctrl-c停了下来,提示了一句:用 /wd 参数绕过中文字符问题。

经过这次人工“抢救”,Qwen才终于迈过了这道坎。
差距确实明显。
第二坑:图形灾难
编译通过后,我满怀期待地运行程序。屏幕上出现的画面,让我愣了几秒。
初看还以为是花屏了——杂乱的色块,模糊的轮廓,根本分辨不出是什么东西。仔细端详后才反应过来:这居然就是飞机?
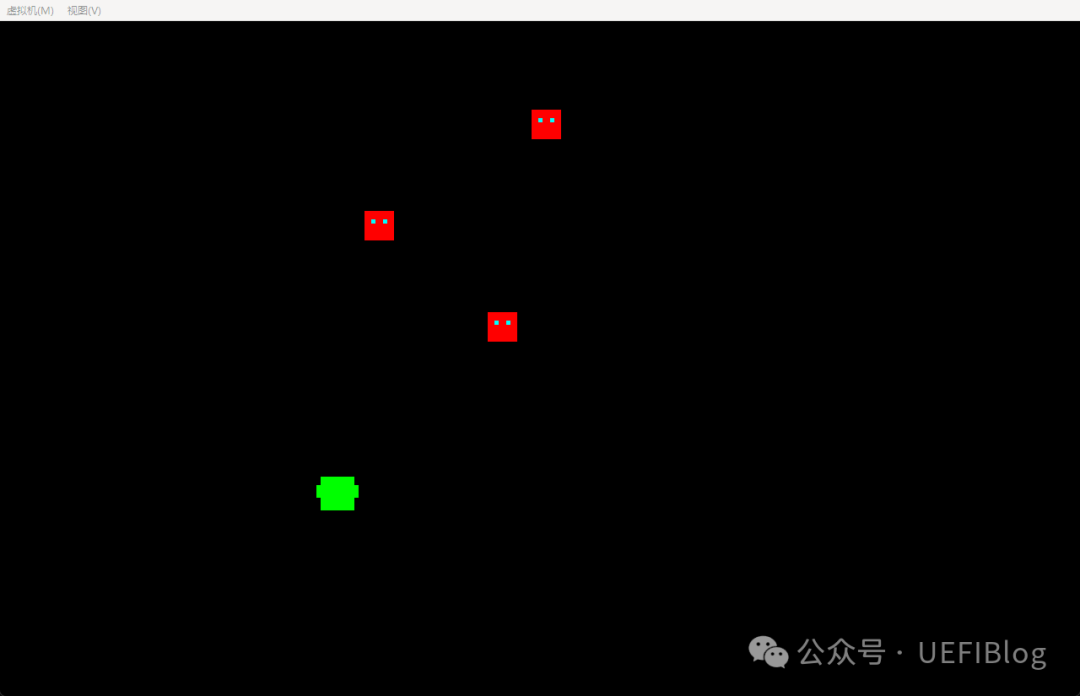
我见过不少AI生成的游戏界面。GLM5的打砖块,虽然代码结构不够规范,但图形质量是体面的。Kimi的贪吃蛇,界面简洁但清晰,至少能看出是一条蛇在屏幕上移动。
而Qwen生成的这个打飞机游戏,比上世纪80年代的游戏还要粗糙。那可是将近四十年前的水平。
我尝试给它一些改善的建议。它修改了几轮,界面确实有了一点变化。但说实话,改善有限——从“80年代游戏”进化到了“90年代初游戏”的水平。这种进步,说实话很有限。
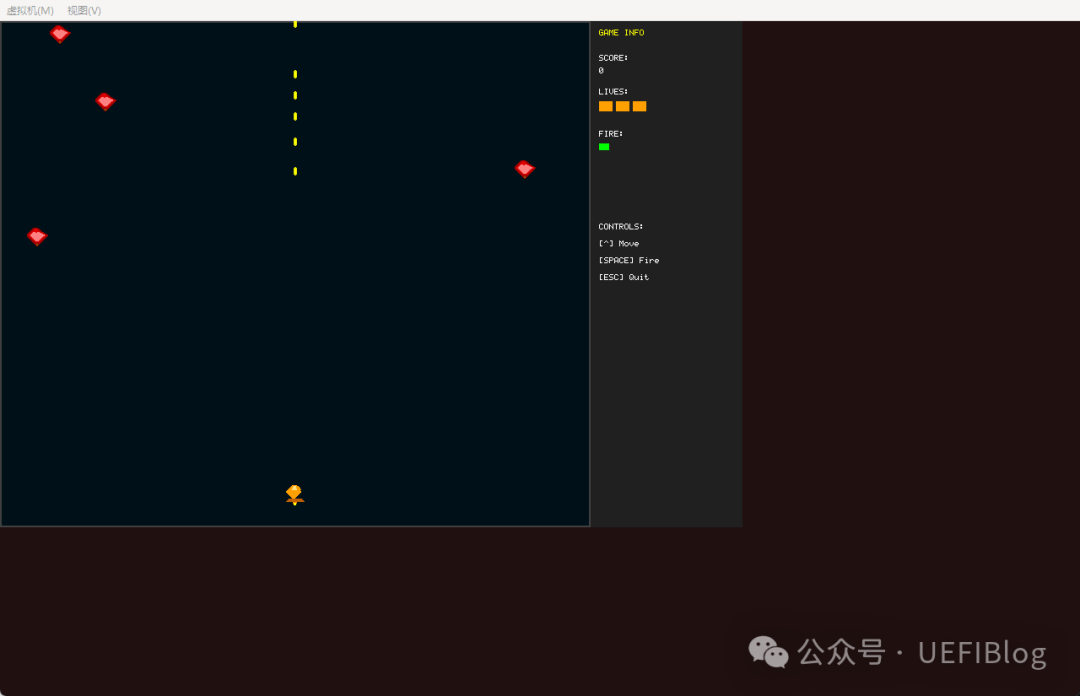
我又尝试提供一些透明背景的 PNG 图片,希望它能用素材改善画面。结果呢?仍然很丑。
最终,我放弃了图形方面的期待。
第三坑:字体问题
界面丑也就罢了,至少能跑。但问题远不止于此。
英文字符开始就是一堆色块。

我贴图给它,它试了几轮,才改成了乱码的英文!

这是前面几个模型都踩过的坑。UEFI环境默认不支持TrueType字体,需要手动处理字模数据。GLM5遇到这个问题时,自己写了一个TrueType字模提取脚本,从字体文件中抠出字符数据,全程自主完成。
Qwen呢?它自己尝试了很久,各种调整字体空间、修改渲染参数,但问题依旧。
无奈之下,我再次提示:自己写脚本去Windows里面取字模。
它这才反应过来,按照我的建议完成了英文显示的修复。
但中文显示的问题,却始终无法解决。
让它去处理中文字体乱码,它折腾了许久,最终还是失败。相比之下,GLM5全程自主完成了中文支持,Kimi在被提示后也顺利解决。Qwen在这一点上,又落了下风。
亮点与反思
说了这么多问题,也应该客观地指出一些正面表现。
亮点一:耐心尝试的精神可嘉。
四个小时编译问题,Qwen一直在尝试解决。虽然最终没能自己搞定,但这种不放弃的态度值得肯定。相比之下,MiniMax每干上半个小时,就直接躺平。在这一点上,Qwen比MiniMax强。
亮点二:多模态能力不错。
Qwen具备图形理解能力,可以看截图分析问题。这一点与Kimi类似。在实际开发中,有时候我可以直接丢一张截图给它,让它自己判断问题所在。这个功能在某些场景下还是挺实用的。
但这些亮点改变不了整体评价。耐心尝试是好事,但光有耐心没有能力,终究解决不了问题。多模态能力确实有,但解决问题的能力与Kimi相比,差距明显。
Kimi遇到字体问题时,我提示一次,它就能找到正确方向并执行。Qwen呢?提示一次不够,还得继续摸索。同样具备多模态能力,但实际产出却相去甚远。
四模型对比
对比完四款模型,结论已经很明显。下表展示了它们在 UEFI 开发场景下的表现:
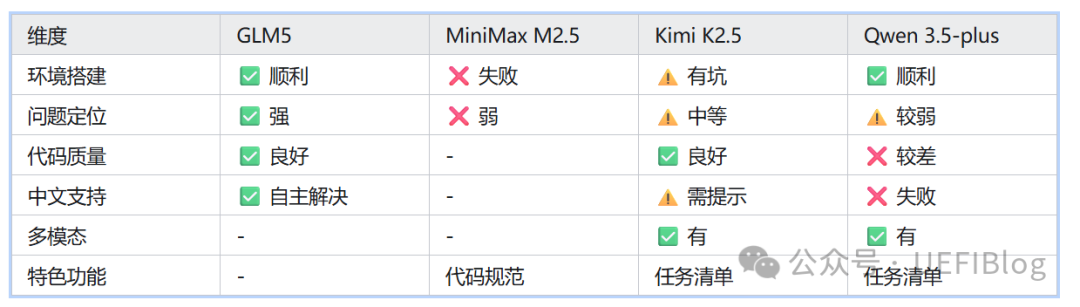
最终排名:GLM5 > Kimi K2.5> Qwen 3.5-plus > MiniMax M2.5
选型建议:
如果追求效率和成功率,GLM5是首选。它在环境搭建、问题定位、代码质量等核心维度上都表现出色,2.5小时完成打砖块开发的成绩目前没有被超越。
如果需要视觉辅助功能,可以考虑Kimi。它的图形识别和Check List功能实用,虽然需要一些人工提示,但最终能完成任务。
Qwen和MiniMax最新版本,目前不太适合于BIOS开发。
结语
Qwen在UEFI开发场景下的表现,不及预期。
环境搭建顺利,任务清单功能实用,这些是加分项。但编译问题卡了4小时、图形质量极差、中文显示失败,这些硬伤难以忽视。因为最后显示结果比较糟糕,源代码也没有什么参考价值,源码我就不共享出来了。
还有豆包模型尚未测试,后续会继续这个系列的评测。如果你想了解更多AI编程的实战经验和避坑指南,欢迎来 云栈社区 交流探讨。
 发表于 2026-3-27 03:31:38
|
查看: 207|
回复: 0
发表于 2026-3-27 03:31:38
|
查看: 207|
回复: 0
