继续探讨GraphRAG的相关技术。本文将回顾大模型构建知识图谱的常规流程,并重点分析GraphRAG中一个颇具技巧性的设计点:基于查询复杂度的双通道召回动态融合策略。
一、大模型构建知识图谱:ERC-KG方法回顾
谈到图谱构建,我们可以结合论文《ERC-KG: A Method for Constructing Domain Knowledge Graphs by Integrating Large Language Models》来回顾大模型用于抽取、检索和纠错的知识图谱构建方法。论文地址:http://joces.nudt.edu.cn/CN/abstract/abstract18359.shtml。
该方法架构清晰,其核心流程可分为四个阶段,如下图所示:
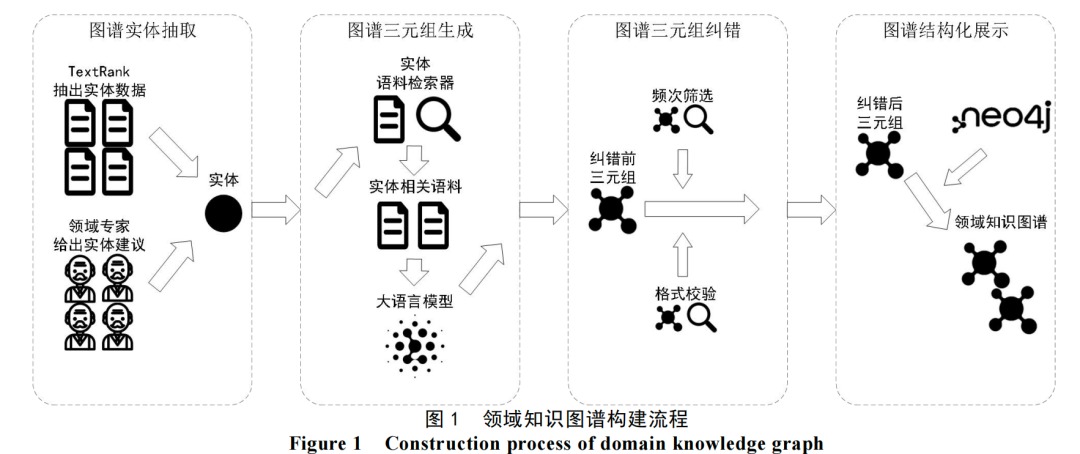
第一阶段:图谱实体抽取
该方法首先采用TextRank算法从文本中自动抽取实体,并结合领域专家知识(例如用户提供的实体词表)来共同识别核心实体。这种混合方式旨在平衡自动化与领域准确性。
第二阶段:图谱三元组生成
为提升大语言模型(LLM)抽取三元组的准确率,该方法构建了一个实体语料检索器。其核心思想是基于语义相似度,从原始语料库中筛选出与目标实体最相关的若干语句,组合成上下文文本后再输入给LLM。这本质上是一种RAG式的召回思路,旨在为LLM提供更精准的上下文。
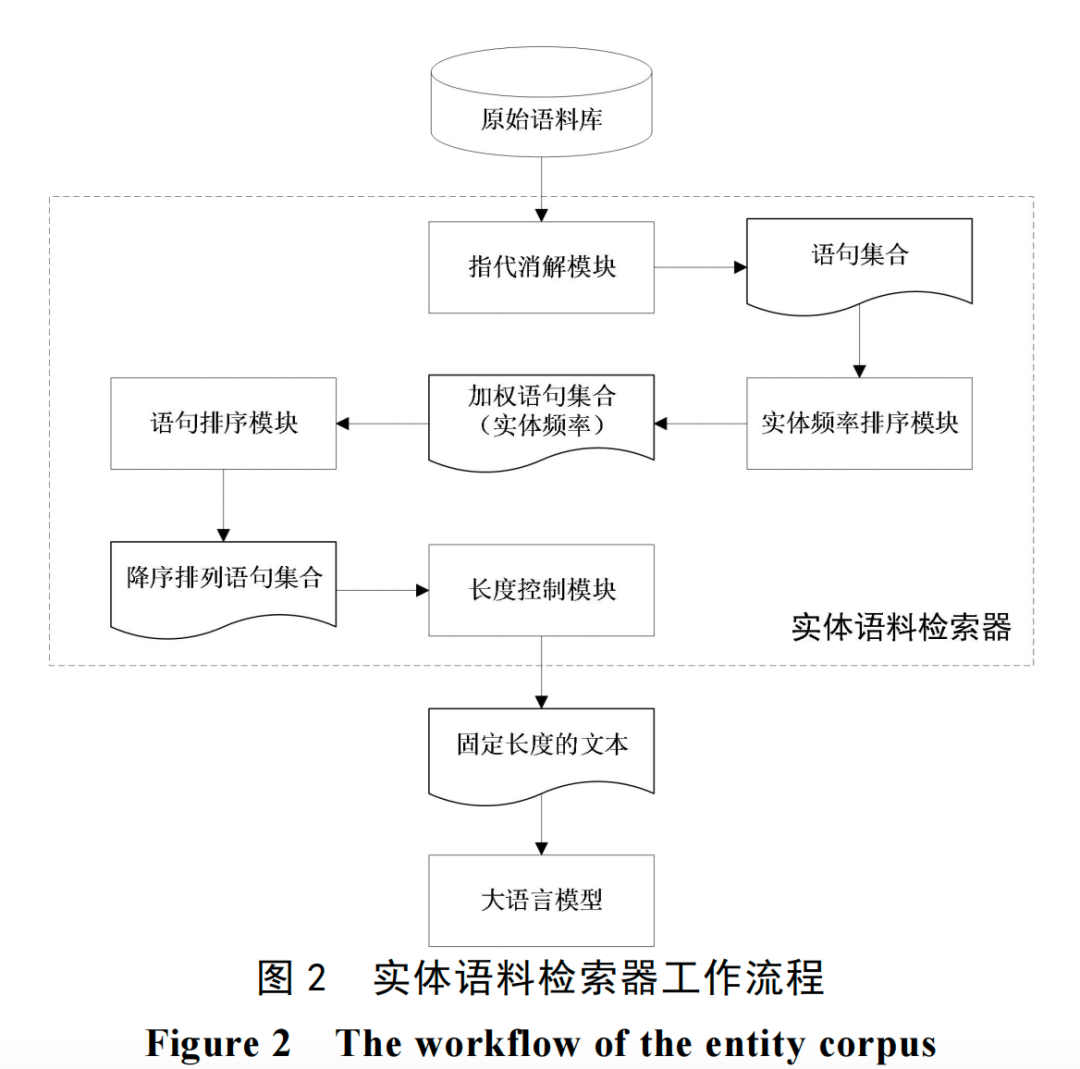
第三阶段:LLM提示工程
准备好相关语料后,通过精心设计的提示词模板引导LLM进行结构化信息抽取。下图展示了一个针对“超短波通信”领域的三元组抽取提示模板示例:

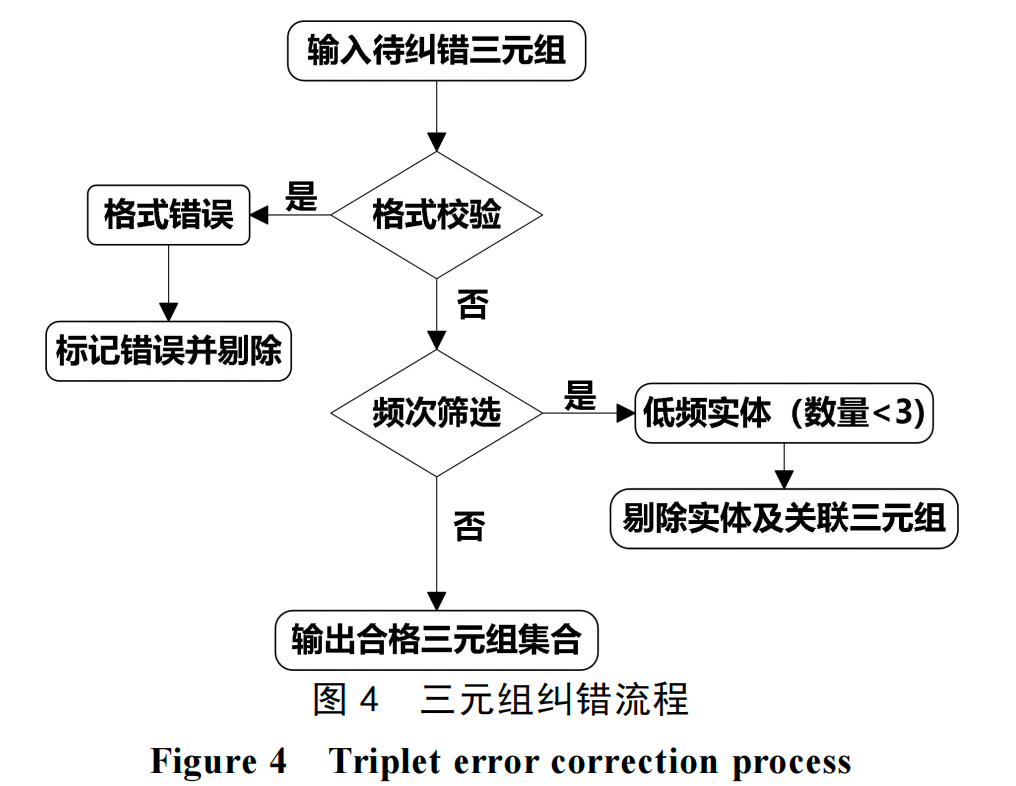
第四阶段:图谱三元组纠错
直接由LLM生成的三元组可能存在格式错误或低频噪声实体。因此,该方法设计了包含“格式校验”和“频次筛选”的两步纠错流程,以输出高质量的三元组集合。
二、GraphRAG新进展:双通道量化融合思路
接下来,我们聚焦于GraphRAG的实现与优化思路。论文《UniAI-GraphRAG: Synergizing Ontology-Guided Extraction, Multi-Dimensional Clustering, and Dual-Channel Fusion for Robust Multi-Hop Reasoning》提出了一个系统性的框架,其代码已开源:https://github.com/UnicomAI/wanwu/tree/main/rag/rag_open_source/rag_core/graph。
该工作的整体架构如下图所示,融合了文本解析、图谱构建与双通道检索:
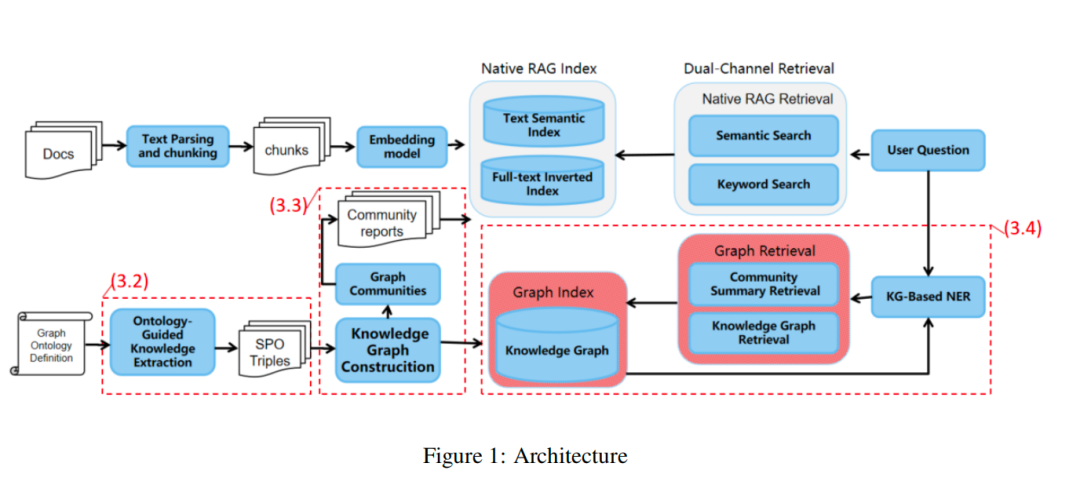
其核心思路包含以下几个关键部分:
1. 本体引导的知识提取
一个常见问题是,若不使用预定义的模式(本体)进行约束,LLM自由抽取的三元组会引入大量噪声。虽然定义模式(Schema)可能导致图谱变稀疏,但能显著提升准确性。这一思路在之前的项目(如youtu-graphrag)中也有体现。
该工作的流程是:由领域专家定义图谱模式(Schema),将其作为提示词输入LLM,从而引导LLM提取规范化的SPO(主体-谓词-客体)三元组。

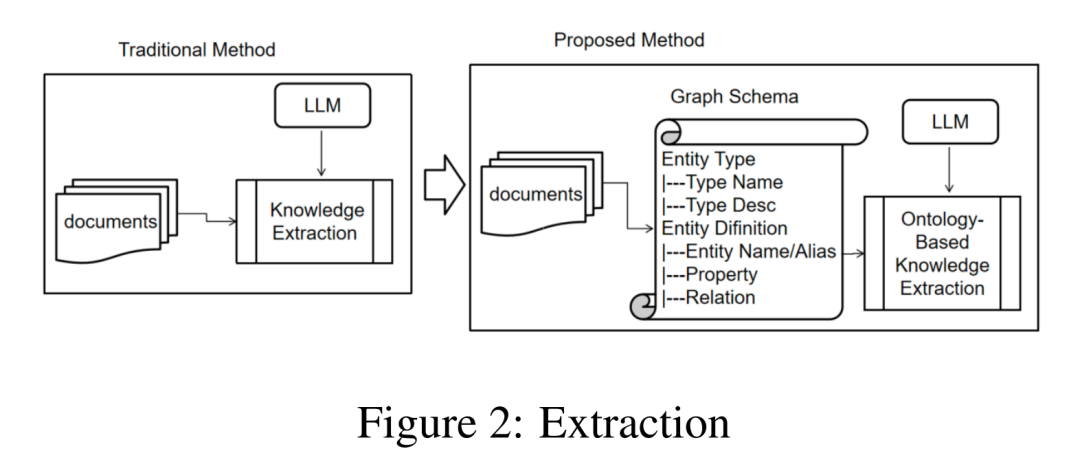
其中,图谱模式在数学上被定义为一个约束空间 S = (E, R, Φ),以此规范实体和关系的类型。

对应的提示词(Prompt)模板则明确要求LLM严格遵循预定义的模式进行信息抽取,确保输出的结构化和准确性。如果你对如何设计高效的提示词模板感兴趣,可以参考云栈社区技术文档板块中的相关讨论。

2. 多路召回与动态融合策略
在检索侧,GraphRAG系统通常采用多路召回机制。本工作设计了一种双通道图检索方案,并引入了查询复杂度感知的动态融合权重,这是其一大亮点。
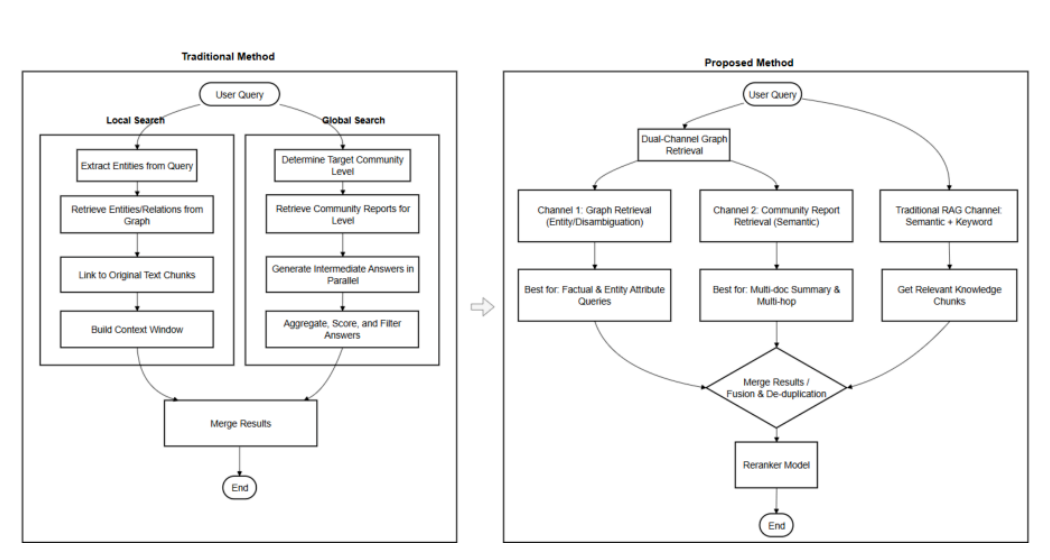
- 通道一:图谱检索。基于字典树匹配实现实体消歧和属性遍历,适用于事实性、实体属性类查询。其检索得分由实体链接置信度和图遍历相关性共同决定。
- 通道二:社区报告检索。将查询语义与通过多维聚类生成的社区主题摘要进行匹配,适用于需要全局上下文的多文档摘要、复杂关系或多跳推理类查询。检索得分基于语义向量相似度计算。
检索完成后,系统并非简单地将两路结果拼接,而是通过一个可学习的查询复杂度感知权重 β(q) 对双通道结果进行动态加权融合,最后再经由Cross-Encoder重排序模型进行精排。
这个权重 β(q) 的计算方式颇具巧思,它综合了以下两个指标:

- 实体密度:统计用户查询
q 中实体的数量与占比,并进行长度归一化处理,以消除查询字数差异的影响。该值越高,表明查询是实体密集的事实型查询。
- 语义抽象分数:以查询中非实体token的熵值为指标,量化查询的语义抽象程度。该值越高,表明查询更偏向于需要进行全局推理的总结或多跳类问题。
动态融合机制:
- 当
β(q) 趋近于1时,表明查询实体密度高、语义简单,系统会赋予图谱检索通道更高的权重,侧重于通过实体遍历获取精准事实。
- 当
β(q) 趋近于0时,表明查询实体稀少、语义抽象,系统则更侧重社区报告检索通道,通过匹配全局主题来获取推理路径和上下文信息。
这种基于查询本身特征进行自适应路由的机制,相比固定权重的融合策略,能更智能地调配资源,提升复杂问答场景下的整体效果。对于希望深入实现此类RAG系统或研究LLM应用的开源爱好者来说,这份研究提供了很好的借鉴思路。
参考文献
- UniAI-GraphRAG 论文:https://arxiv.org/pdf/2603.25152
本文由云栈社区编辑整理,旨在分享前沿技术思路,更多关于人工智能与知识工程的实战讨论,欢迎访问社区交流。
 发表于 2026-3-28 03:00:39
|
查看: 205|
回复: 0
发表于 2026-3-28 03:00:39
|
查看: 205|
回复: 0
