在高并发、异步化处理的业务场景中,线程池的应用几乎无处不在。从本质上讲,线程池是一种通过空间换取时间的策略。因为线程的创建和销毁都需要消耗系统资源和时间,在对线程使用密集的场景下,通过池化管理延迟线程销毁,可以极大地提高单个线程的复用能力,从而提升整体性能。
今天分享的这个线上案例就与线程池紧密相关,它不仅涉及典型的死锁问题,还关联到jstack命令的使用、JDK内置线程池的适用场景分析等知识点。整个排查思路具有很好的借鉴意义,特此记录。
01 业务背景描述
这次线上问题发生在广告系统的核心“扣费服务”中。为了便于理解,先简单描述一下大致的业务流程。
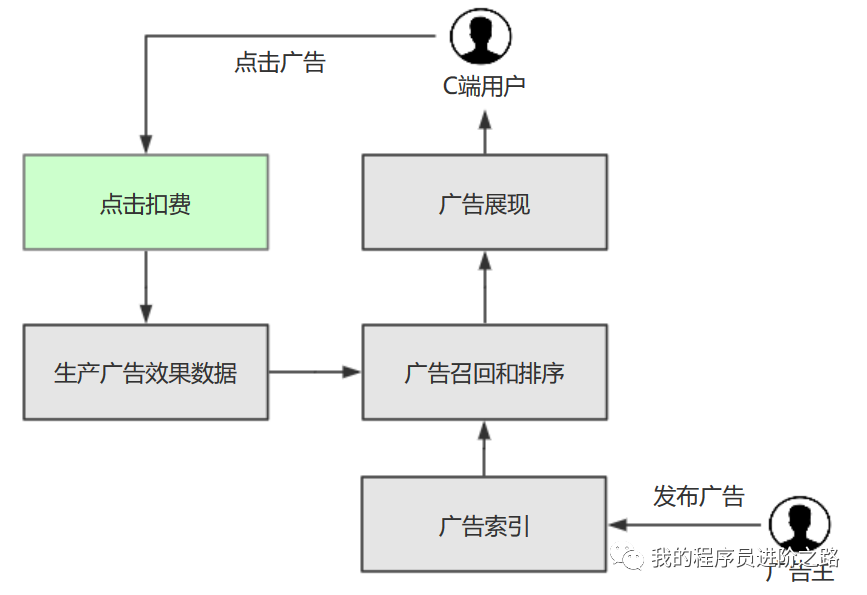
图中绿色方框部分就是扣费服务在广告点击扣费流程中的位置。简单来说:当用户点击一个广告后,会从客户端发起一次实时扣费请求(CPC,按点击付费模式)。扣费服务则承接了这个动作的核心业务逻辑,包括执行反作弊策略、创建扣费订单、记录点击日志等。
02 问题现象和业务影响
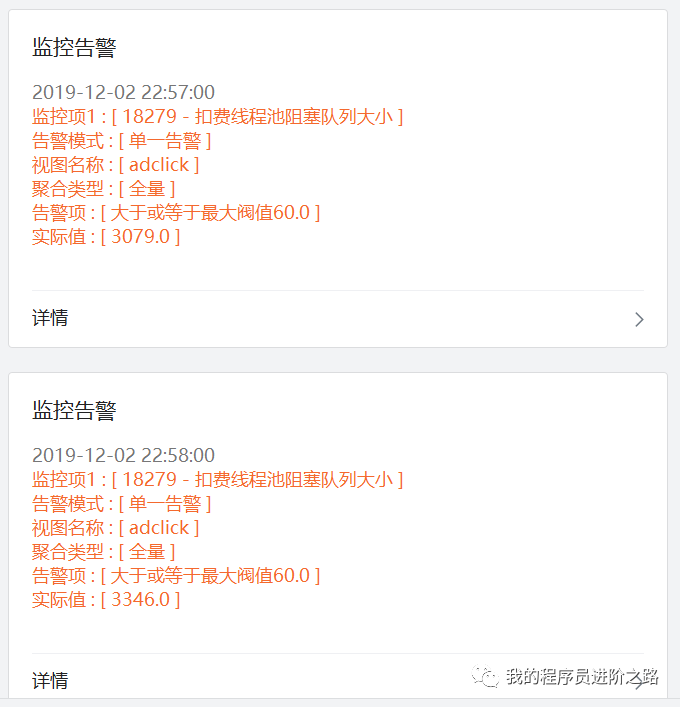
12月2日晚上11点左右,我们收到了一条线上告警:扣费服务的线程池任务队列大小远远超出了预设的阈值,并且队列大小随着时间推移还在持续增长。详细的告警内容如下:
几乎是同时,我们的核心业务指标——广告点击数和收入也出现了非常明显的下滑,触发了业务告警。其中,点击数的监控曲线表现如下:
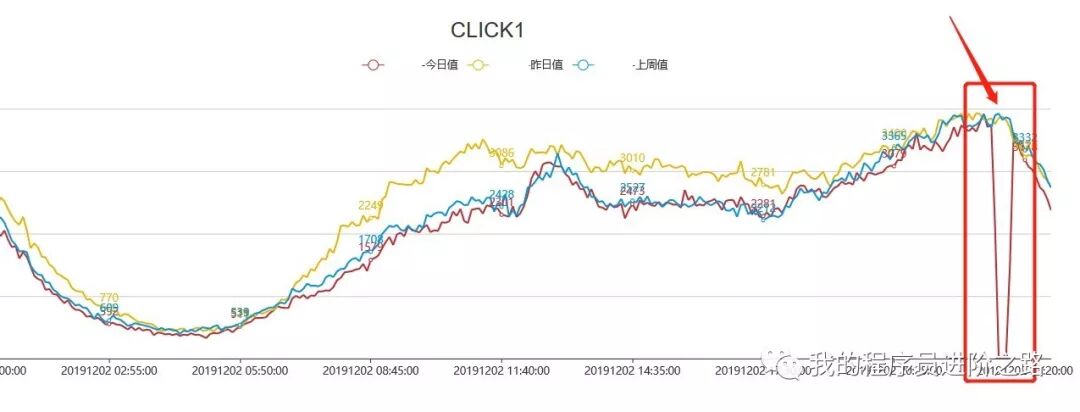
这次线上故障发生在流量高峰期,持续了将近30分钟才恢复正常。
03 问题调查和事故解决过程
下面详细回顾整个事故的调查和解决过程。
第1步:收到线程池队列告警后,我们第一时间查看了扣费服务的各项实时数据:服务调用量、超时量、错误日志、JVM监控等,均未发现明显异常。
第2步:进一步排查扣费服务所依赖的存储资源(MySQL、Redis、MQ)和外部服务。这时我们发现,事故期间存在大量的数据库慢查询。
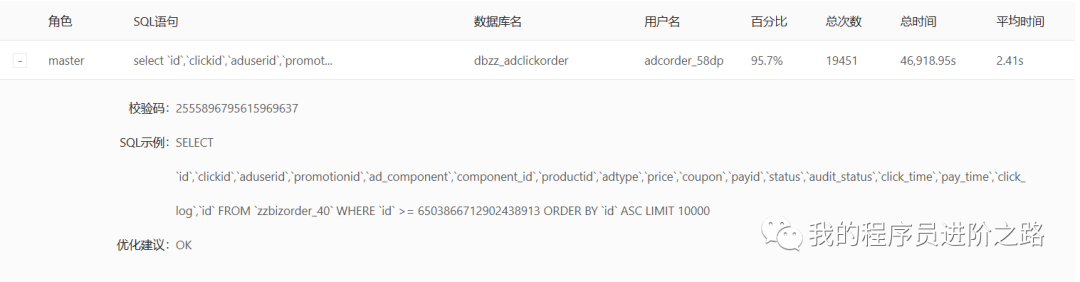
这些慢查询来自于一个刚上线的大数据抽取任务,它正在从扣费服务的MySQL库中大批量并发抽取数据到Hive表。由于扣费流程本身也涉及写入MySQL,我们猜测这个任务影响了数据库的整体读写性能。果然,进一步查看发现INSERT操作的耗时也远高于正常水平。
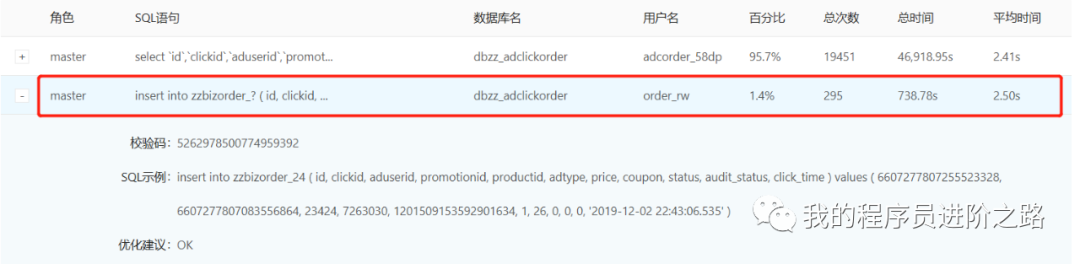
第3步:我们初步判断是数据库慢查询拖慢了扣费流程,导致任务在队列中积压。于是立即暂停了那个大数据抽取任务。但奇怪的是,停止后数据库的INSERT性能恢复了,可线程池的阻塞队列大小仍在持续增长,告警并未消失。
第4步:考虑到广告收入仍在持续下跌,而深入分析代码需要时间,我们决定先重启服务以快速恢复业务。为了保留事故现场,我们特意保留了一台服务器不做重启,只是将其从负载均衡中摘除,使其不再接收新的扣费请求。
重启的“杀手锏”果然有效,各项业务指标迅速恢复正常,告警也不再出现。至此,线上故障得到解决,整个过程持续了约30分钟。
04 问题根本原因的分析过程
故障虽然恢复,但根本原因尚未找到。以下是后续的详细分析过程。
第1步:第二天,我们推测那台被保留的服务器,其队列中积压的任务应该已经被线程池处理掉了。于是尝试将它重新挂载回集群进行验证。结果与预期完全相反,积压的任务依然存在,并且随着新请求进入,系统告警立刻再次出现,我们只好马上又将其摘除。
第2步:线程池中积压的几千个任务,经过一整夜都没有被处理掉,这强烈暗示可能存在死锁。我们决定使用jstack命令dump线程快照进行分析。
# 找到扣费服务的进程号
$ jstack pid > /tmp/stack.txt
# 通过进程号dump线程快照,输出到文件中
$ jstack pid > /tmp/stack.txt
在jstack的日志文件中,我们立即发现了一个关键线索:用于扣费的业务线程池的所有线程都处于WAITING状态。它们全部卡在了下图红框标识的代码行上,即调用了CountDownLatch.await()方法,在等待计数器归零。
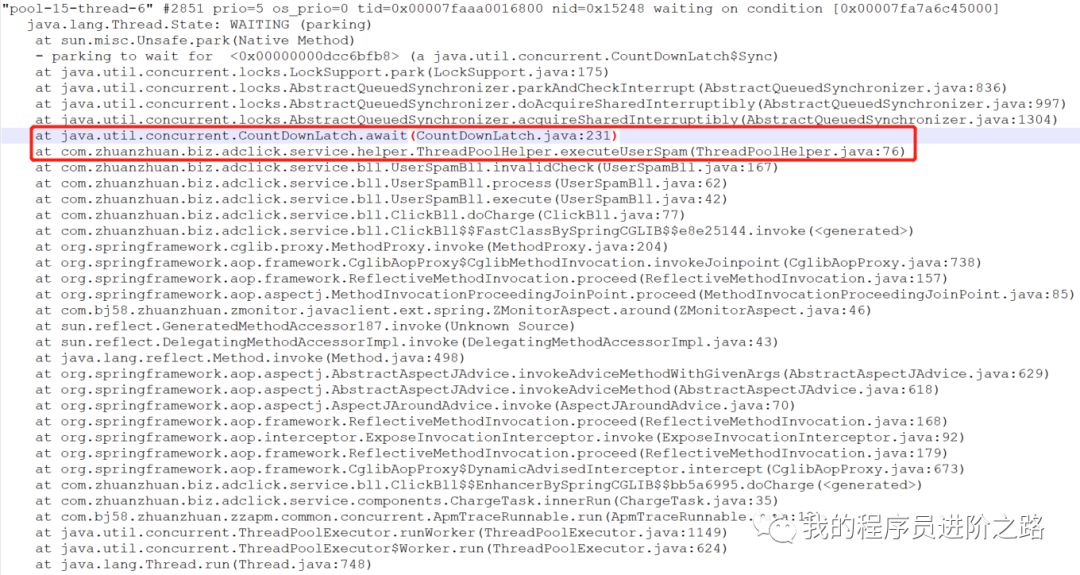
第3步:找到这个异常点后,离真相就很近了。我们回到代码中调查,发现业务代码中使用了Executors.newFixedThreadPool来创建线程池,核心线程数设置为25。关于newFixedThreadPool,JDK文档的说明是:
创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程。如果在所有线程处于活跃状态时提交新任务,则在有可用线程之前,新任务将在队列中等待。
这里有两个核心点:
- 最大线程数等于核心线程数,当所有核心线程都在忙时,新任务会进入任务队列等待。
- 它使用了无界队列。这意味着提交给线程池的任务队列没有大小限制,如果任务处理被阻塞或变慢,队列就会无限增长。
因此,进一步的结论是:核心线程全部陷入死锁,新进的任务不断涌入无界队列,导致队列大小只增不减。
第4步:到底是什么导致了死锁?我们再次回到jstack日志提示的那行代码进行分析。以下是我简化后的示例代码:
/**
* 执行扣费任务
*/
public Result<Integer> executeDeduct(ChargeInputDTO chargeInput) {
ChargeTask chargeTask = new ChargeTask(chargeInput);
bizThreadPool.execute(() -> chargeTaskBll.execute(chargeTask ));
return Result.success();
}
/*
* 扣费任务的具体业务逻辑
*/
public class ChargeTaskBll implements Runnable {
public void execute(ChargeTask chargeTask) {
// 第一步:参数校验
verifyInputParam(chargeTask);
// 第二步:执行反作弊子任务
executeUserSpam(SpamHelper.userConfigs);
// 第三步:执行扣费
handlePay(chargeTask);
// 其他步骤:点击埋点等
...
}
}
/**
* 执行反作弊子任务
*/
public void executeUserSpam(List<SpamUserConfigDO> configs) {
if (CollectionUtils.isEmpty(configs)) {
return;
}
try {
CountDownLatch latch = new CountDownLatch(configs.size());
for (SpamUserConfigDO config : configs) {
UserSpamTask task = new UserSpamTask(config,latch);
bizThreadPool.execute(task);
}
latch.await();
} catch (Exception ex) {
logger.error("", ex);
}
}
通过上述代码,你能发现死锁是如何发生的吗?根本原因在于:一次扣费行为是父任务,它又包含了多个并行执行的子任务(反作弊检查),而父任务和子任务使用的是同一个业务线程池。
当线程池中的所有核心线程都在执行父任务,并且每个父任务都在等待其子任务完成时,死锁就发生了。子任务在等待队列中,但执行子任务的线程正是那些被父任务占用的核心线程——它们永远无法被释放。下面这张图可以更直观地展示这个状态:
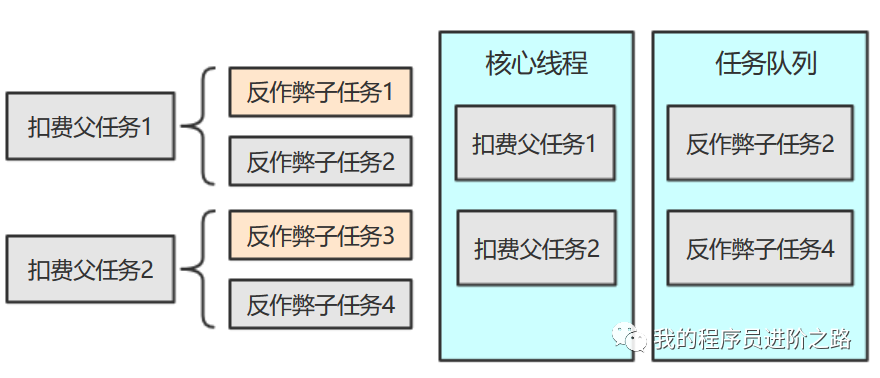
假设核心线程数是2,当前正在执行扣费父任务1和2。反作弊子任务1和3已执行完,但子任务2和4积压在任务队列中等待调度。由于子任务2和4没执行完,父任务1和2的latch.await()就永远不会返回,导致这两个核心线程被永久占用。这样一来,队列中的子任务2和4也永远得不到执行,系统陷入死锁,新任务不断加入无界队列,直至可能发生OOM。
死锁原因清楚了,但还有个疑问:这段代码线上运行已久,为何现在才出事?和数据库慢查询有直接关系吗?
我们暂时未能完全复现,但可以推断:上述代码设计本身就存在死锁的概率,尤其是在高并发或任务处理变慢(比如因数据库慢查询导致)的情况下,概率会显著增加。本次事故中,数据库慢查询很可能就是触发死锁的“导火索”,它拖慢了父任务的处理速度,使得所有核心线程更快地进入等待状态。
05 解决方案
弄清楚根本原因后,最简单的解决方案就是进行线程池隔离:增加一个新的业务线程池,专门用于处理反作弊子任务,现有的线程池则只处理扣费父任务。这样就从资源上切断了循环依赖,彻底避免了死锁的发生。
06 问题总结
回顾这次事故的解决过程以及扣费服务的技术方案,以下几点值得后续优化:
- 慎用固定线程池与无界队列:使用
Executors.newFixedThreadPool这类创建固定线程数且使用无界队列的线程池,存在资源耗尽(OOM)的风险。在阿里巴巴Java开发手册中也明确指出,不建议(甚至“不允许”)使用Executors快捷创建线程池,而是推荐通过ThreadPoolExecutor构造函数手动创建。这样做能让开发者更清晰地明确线程池的运行规则和核心参数(如核心线程数、最大线程数、队列类型及容量、拒绝策略等),从而主动规避风险。
- 异步方案的健壮性设计:广告扣费是一个异步过程,使用线程池或消息队列(MQ)实现都是可选方案。考虑到业务允许极个别点击请求丢失,但绝不能接受大批量请求丢弃且无补偿。后续若改用有界队列,需要仔细设计拒绝策略,例如将拒绝的任务发送至MQ进行异步重试处理,以保证业务的最终一致性。
这次线上事故是一次深刻的教训,它提醒我们在享受线程池带来的便利时,必须对其底层机制和潜在风险有清醒的认识。希望这个案例能为大家在云栈社区和其他平台进行高并发系统设计时提供一些有益的参考。
 发表于 2026-3-28 08:18:14
|
查看: 133|
回复: 0
发表于 2026-3-28 08:18:14
|
查看: 133|
回复: 0
