系统设计面试真的会考红黑树吗?大多数时候并不会。面试官更关心的是,你是否了解那些真正支撑起大规模分布式系统的核心算法,以及如何在设计中选择和应用它们。
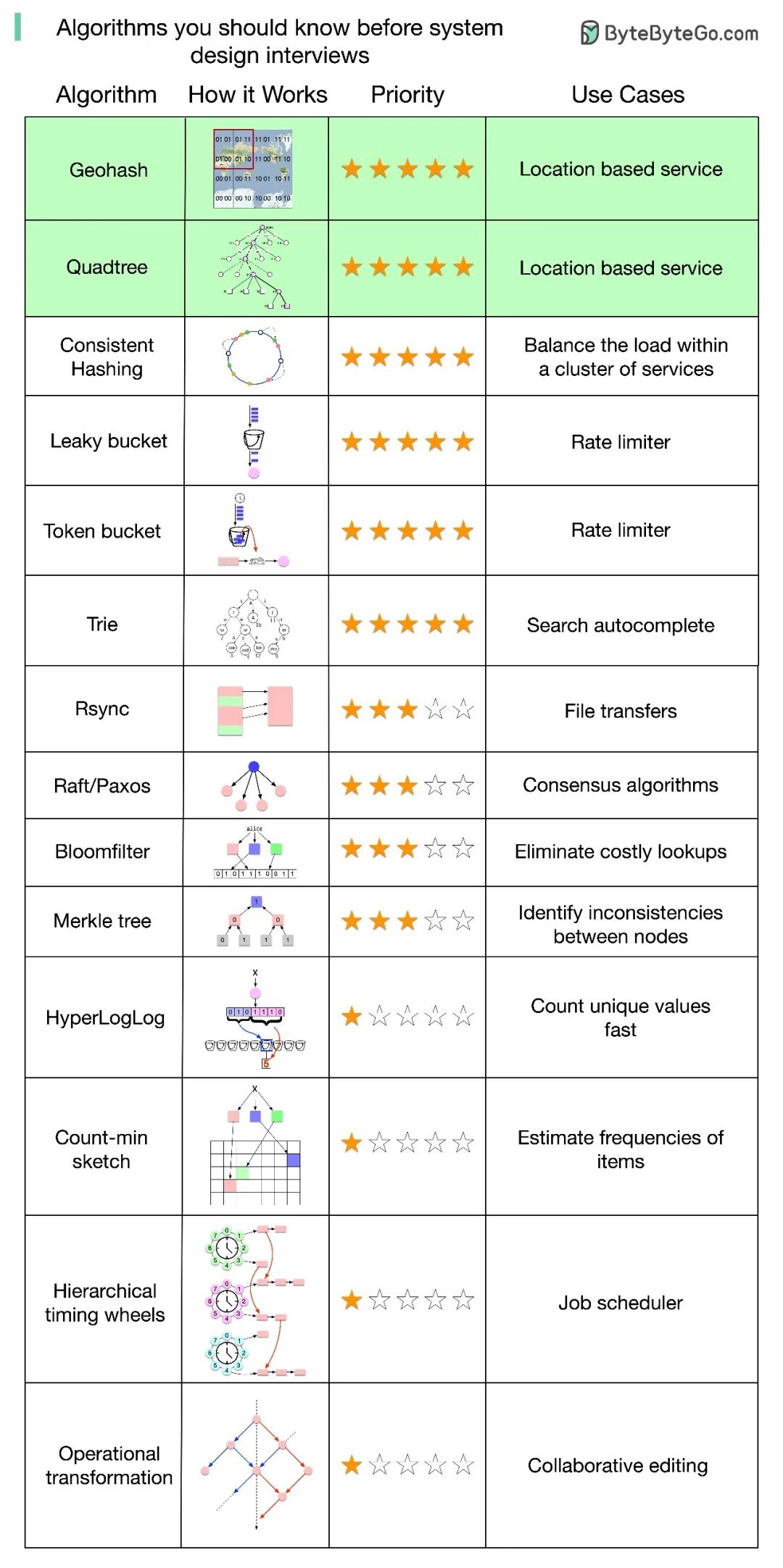
上图是一份非常实用的速查表,清晰展示了在 系统设计 面试中需要掌握的核心算法、其工作原理、重要程度及典型应用场景。 (来源:ByteByteGo.com)
理解“这些算法在真实系统中怎么用”,远比死记硬背实现细节来得重要。面试中,你的目标是展示你解决问题的思路和知识储备,而非背诵教科书。
五星优先级:必须熟练掌握
这类算法是构建可靠、高效分布式系统的基石,在面试中出现频率极高。
一致性哈希(Consistent Hashing)
这是 分布式缓存 和数据库分片场景下的核心算法。它解决了普通哈希取模在节点增删时,导致大量数据需要重新映射的问题。一致性哈希通过构建一个哈希环,确保在添加或删除节点时,只有环上相邻节点的数据需要迁移,从而大大降低了数据迁移的成本。
应用实例:Redis Cluster、Cassandra、DynamoDB 等分布式存储系统都广泛采用了一致性哈希来实现数据分片和负载均衡。
布隆过滤器(Bloom Filter)
布隆过滤器是一种空间效率极高的概率型数据结构,用于快速判断一个元素“是否绝对不在集合中”或“可能在集合中”。它的特点是存在一定的误判率(假阳性),但绝不会漏判(假阴性)。这使得它非常适合用于前置的快速过滤操作。
应用实例:Google Bigtable 和 HBase 用它来快速判断某行数据是否不存在,从而避免了对不存在数据的昂贵磁盘查找。它也常被用于防止缓存穿透 —— 当查询一个数据库中根本不存在的数据时,利用布隆过滤器在缓存层直接拦截,保护底层数据库。
限流算法(Rate Limiting)
高并发系统中保护服务不被突发流量打垮的关键机制。你需要了解几种常见的实现方式:
- 令牌桶:以固定速率生成令牌,请求到来时消耗令牌,无令牌则拒绝。
- 漏桶:请求以任意速率流入“桶”中,但以恒定速率流出处理。
- 滑动窗口:统计最近一段时间窗口内的请求量,更为精准。
应用实例:所有 API 网关(如 Nginx、Spring Cloud Gateway)、微服务框架的限流组件。
心跳检测(Heartbeat)
这是分布式系统中最基础的故障检测机制。节点之间定期互相发送轻量的心跳包(或保活消息),若在约定时间内未收到对方的心跳,则单方面判定该节点失效。
应用实例:所有分布式协调服务,如 ZooKeeper、etcd 的核心功能之一就是通过心跳来维持集群节点的状态感知。
三星优先级:深入理解原理与适用场景
这些算法同样重要,但可能只在特定业务场景下成为设计的关键点,理解其思想和应用边界即可。
GeoHash
将二维的经纬度坐标编码成一维字符串的算法。其精妙之处在于,地理位置相近的点,其 GeoHash 字符串的前缀也相同。这使得基于前缀的范围查询可以高效地找到“附近”的目标。
应用实例:“附近的人”、地图 POI 搜索。Redis 的 GEO 模块和 MongoDB 的地理空间索引底层都采用了类似思想。
倒排索引(Inverted Index)
搜索引擎的基石。它不同于传统数据库“文档 -> 关键词”的正排索引,而是建立“关键词 -> 文档列表”的映射。当用户搜索时,可以快速通过关键词找到所有包含它的文档。
应用实例:Elasticsearch、Solr 等全文检索引擎的核心,也是 MySQL 等数据库全文索引功能的实现原理。
Merkle Tree
一种哈希树结构,常用于快速、高效地验证大数据集的内容是否一致,并精确定位差异所在。它的叶子节点是数据块的哈希值,非叶子节点是其子节点哈希值的哈希。
应用实例:
- 版本控制系统:Git 使用 Merkle Tree 来管理提交历史和文件内容。
- 区块链:Bitcoin 用 Merkle Tree 来汇总和验证区块中的交易。
- 分布式存储:Cassandra、IPFS 用它来进行跨节点的数据同步和一致性校验。
一星优先级:进阶了解,体现技术广度
了解这些算法可以让你在讨论特定优化或数据结构的选型时脱颖而出。
跳表(Skip List)
一种可以替代平衡树(如红黑树)的有序数据结构。它通过添加多级索引来实现平均 O(log n) 的查询、插入和删除复杂度,且实现起来比平衡树要简单许多。
应用实例:Redis 的 Sorted Set 数据类型的底层实现之一就是跳表。LevelDB/RocksDB 的 MemTable 也使用了跳表。
前缀树(Trie)
专门为处理字符串而设计的树形数据结构。它的最大优势在于高效的前缀匹配,例如,查找所有以“pre”开头的单词,只需要定位到“pre”节点并遍历其子树即可。
应用实例:搜索引擎的搜索建议(Auto-complete)、IDE 的代码补全、路由器的 IP 路由表匹配。
Raft / Paxos
经典的分布式一致性算法,用于在多个节点之间就某个值(例如,谁是主节点、某条日志内容)达成共识,即使在部分节点故障、网络分区的恶劣环境下也能保证正确性。
应用实例:etcd、Consul(使用 Raft);Google 内部大量系统使用 Paxos 的变种。理解其基本流程和术语(如 Leader、Log Replication)对设计高可用系统很有帮助。
面试实战策略:如何展示你的算法知识
在系统设计面试中,不要等待面试官提问,而是要主动地将你的知识融入到设计方案中。当讨论到以下场景时,可以自然引出相关算法:
- 讨论数据分片与负载均衡 → 主动提及一致性哈希,说明如何平滑扩缩容。
- 设计缓存层策略 → 谈到防止恶意查询击穿数据库时,提出使用布隆过滤器进行前置过滤。
- 实现搜索或推荐功能 → 指出核心是构建倒排索引,并可以简述其原理。
- 设计 API 或服务保护机制 → 引入令牌桶或滑动窗口限流算法,确保系统稳定性。
- 确保分布式数据一致性或同步 → 提到可以用 Merkle Tree 来快速比对和同步节点间的数据差异。
你不需要在白板上推导公式或写出完整代码,但必须能清晰地口头阐述:
- 这个算法解决了什么核心问题?(痛点)
- 它的核心思想和工作原理是什么?(时间复杂度、空间复杂度如何?)
- 举出 1-2 个你知道的真实系统应用案例。(证明你不是纸上谈兵)
将这些算法内化为你系统设计工具箱的一部分,你就能在面试中更加从容自信,展现出扎实的功底和广阔的视野。如果你想查看更多关于 面试求职 的实战技巧和算法题解,欢迎访问云栈社区,这里有更多开发者一起交流成长。
 发表于 2026-3-29 01:23:18
|
查看: 157|
回复: 0
发表于 2026-3-29 01:23:18
|
查看: 157|
回复: 0
