事故发生
业务监控触发了告警通知,相关服务接口出现超时,同时 Redis 也出现了命令操作耗时增加的告警。
规则标题:service-服务自身接口耗时增加
业务组:ops.devops
规则备注:
event_code_avgtime event=RestServe.fans_club.get_medal project=ops.fan_club.logic
所属集群:Default
告警级别:S3
事件状态:Recovered
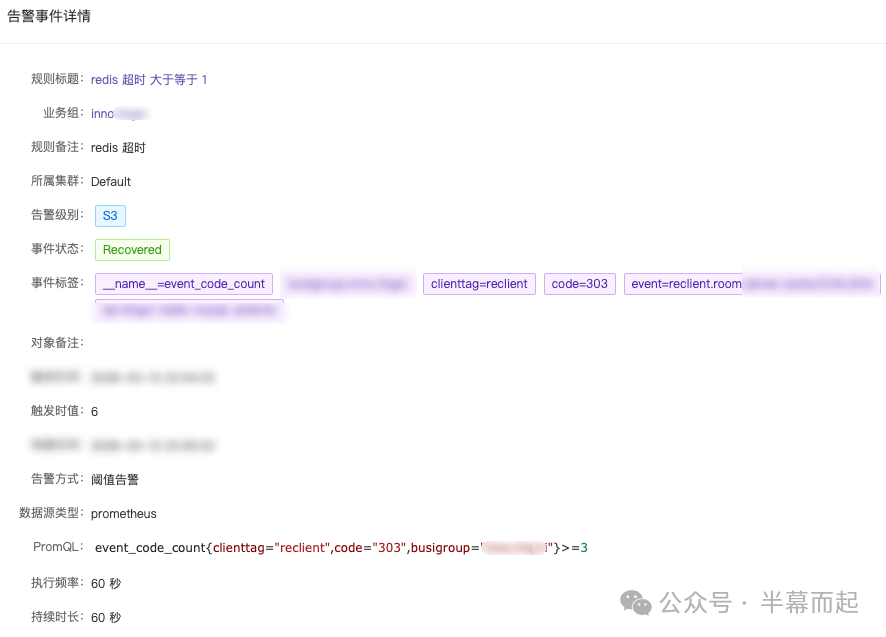
当时心里一紧:坏了,难道是 Redis 出问题了?

事故排查
当遇到涉及公共中间件的组件异常时,第一步是立即同步负责的 DBA 或 SRE 同事,让他们同步介入排查。
但业务稳定是第一要务,首先要做的是快速恢复接口的可用性,减少对用户的影响。对于 Redis 这种核心组件导致的突发问题,最直接有效的临时手段就是垂直扩容,提升实例规格。
在协调资源进行扩容的同时,业务侧也需要同步排查根本原因。从告警信息快速定位到 Redis 后,我们去控制台查看实例的总体状态,结论很直接:CPU 被打满了。
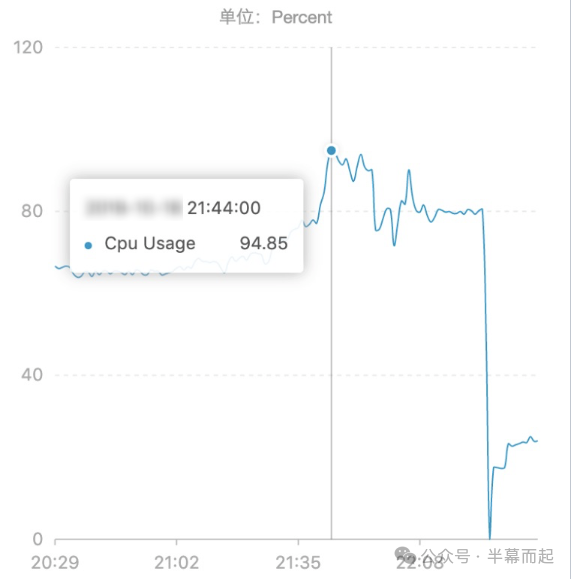
在 DBA 完成紧急扩容操作后,Redis 的 CPU 使用率迅速下降,业务接口也随之恢复。这次使用的是云上的分布式 Redis 架构。
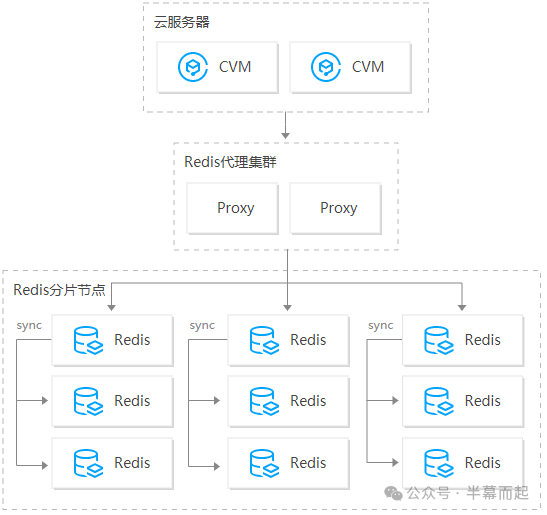
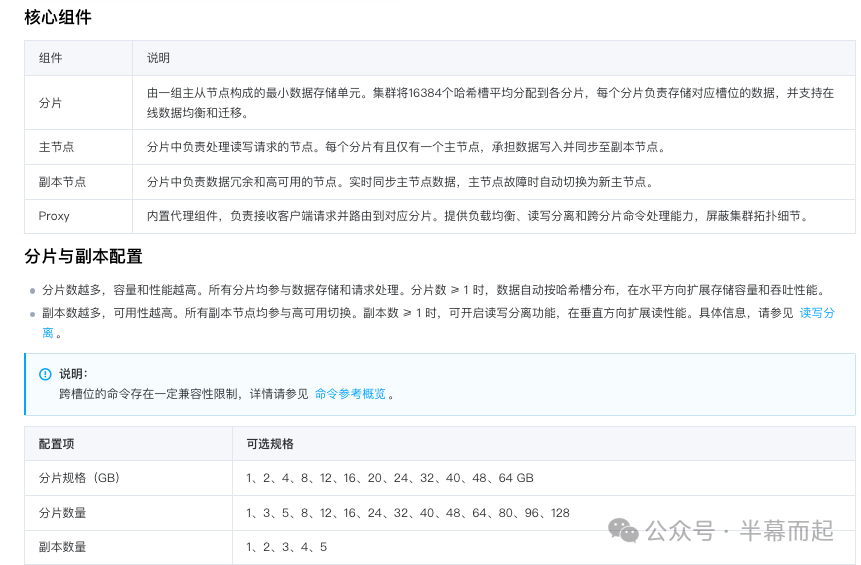
具体的架构和规格可以参考云厂商的官方文档:https://cloud.tencent.com/document/product/239/18336。
-
Redis 的 QPS 指标
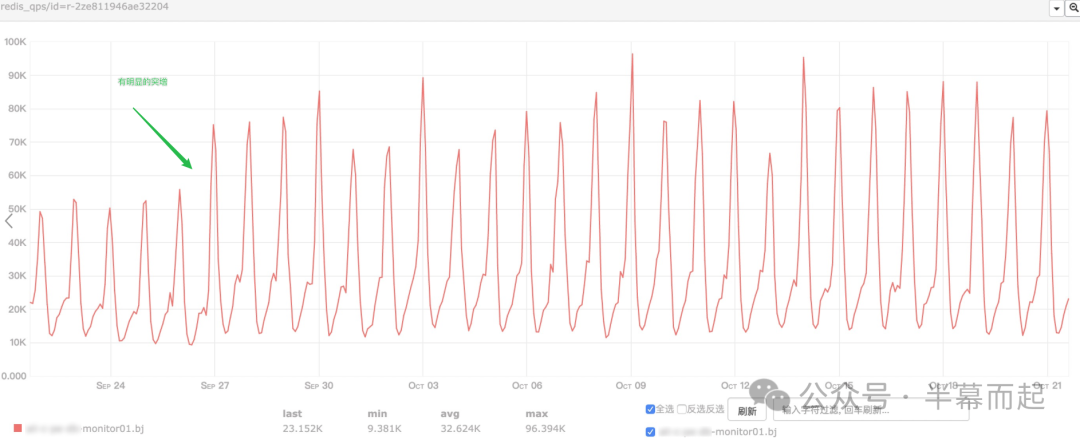
从监控可以看到,Redis 的 QPS 峰值去到了 8W+,并且在某个时间点出现了明显的流量突增。
-
业务侧 Redis 操作端累计分析
为了定位突增来源,我们梳理了主要业务对 Redis 的操作量。我们分接口侧和 Kafka 消费侧进行了统计。
- 接口侧累计
| 接口名 |
峰值qpm |
单次消费操作redis次数 |
qpm峰值 |
| anchor_fans_club |
24k |
10 |
240k |
| fans_verify |
70k |
3 |
210k |
| get_commander_info |
10k |
1 |
10k |
| get_medal |
60k |
61 |
3660k |
- Kafka 消费侧累计
| Kafka |
峰值qpm |
单次消费操作redis次数 |
qpm峰值 |
| 普通送礼 |
600 |
3 |
1800 |
| 道具送礼 |
80 |
2 |
160 |
| 直播间拉流 |
140k |
3 |
520k |
| 进房消息 |
5k |
10 |
50k |
| 开关播 |
40 |
3 |
120 |
接口侧和消费侧的累计操作量级与监控的 QPS 大致匹配。结合监控上的突增点,我们需要定位在那个时间点,业务内部是否有版本或配置变更。
通过分析 Kafka 消费侧的监控数据,并没有发现特别明显的流量变化:
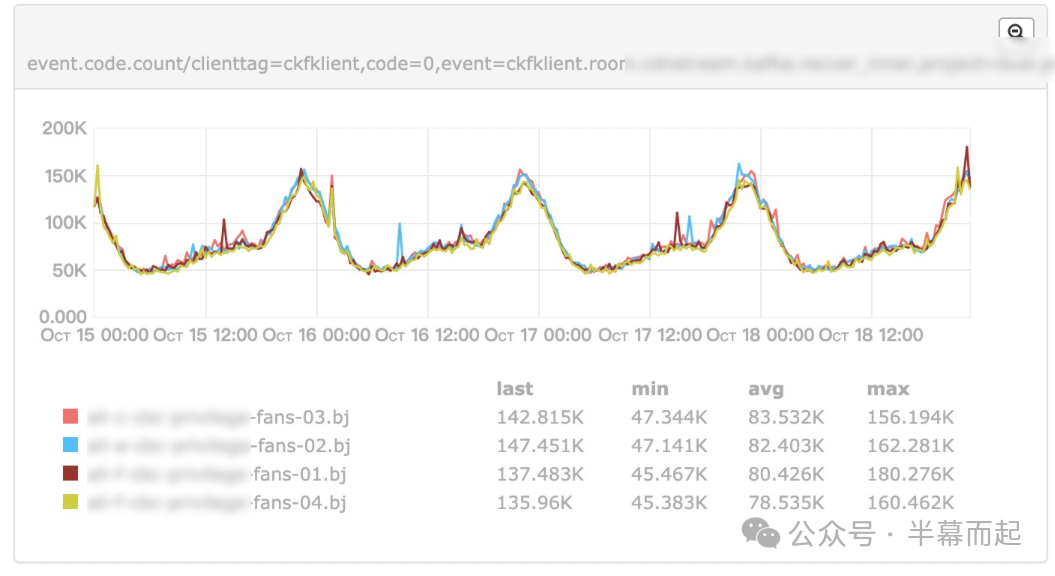
那么问题大概率出在接口侧。我们重点分析了对 Redis 操作量最大的几个接口,很快就发现是 get_medal 接口出现了异常突增。查看该接口近期的代码变更记录,终于找到了问题根源:
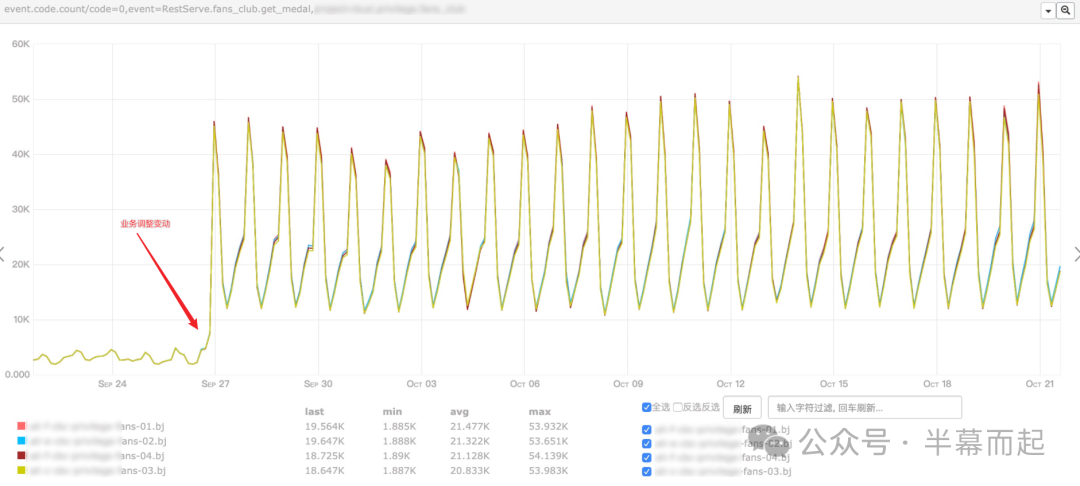
原来,之前一个看似很小的需求改动,将 get_medal 接口的查询范围从局部切换到了全局。在业务持续高频运行的背景下,这个“小改动”积累的流量变化,最终引发了这次事故。
-
主因分析
事故的核心原因可以概括为:在高 QPS 场景下,突增的批量 IO 操作导致 CPU 飙升。
这个 Redis 实例的 CPU 利用率平时就维持在较高水平(接近 80%)。在 18 日,由于接口流量比往常上涨了超过 1w QPS,CPU 利用率在短时间内冲上 90%+。这导致大量 Redis 请求在队列中堆积,命令处理耗时增加,从而引发了上游业务的超时告警。
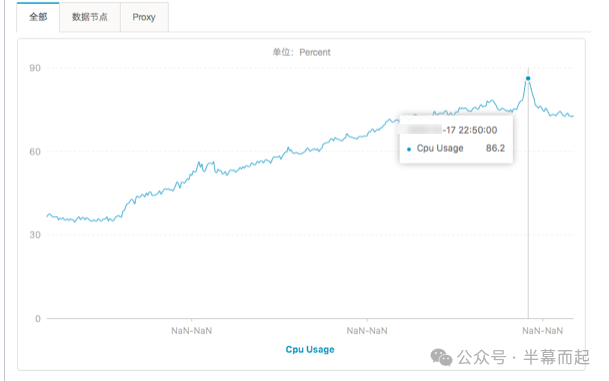
直接诱因就是切换到全局查询的 get_medal 接口,它涉及 Redis 的批量操作命令。在本来就高并发的背景下,这部分突然增加的流量成了“压垮骆驼的最后一根稻草”。
大量操作命令瞬间涌入,直接让单线程工作的 Redis 处理命令的线程阻塞,导致 CPU 飙升到 95%。你可以这样理解这个过程:
【正常情况 - CPU 60%】
时间轴: 0ms 1ms 2ms 3ms 4ms 5ms
请求: [cmd1] [cmd2] [cmd3] [cmd4] [cmd5]
处理: ==== ==== ==== ==== ====
CPU: ▄▄ ▄▄ ▄▄ ▄▄ ▄▄ (有间隙,可休息)
【阻塞情况 - CPU 95%】
时间轴: 0ms 1ms 2ms 3ms 4ms 5ms 6ms 7ms 8ms
请求: [cmd1] [cmd2] [cmd3] [cmd4] [cmd5] [cmd6] [cmd7] [cmd8] ...持续涌入
处理: ================================(处理一个慢命令耗时 5ms)
队列: [cmd2] [cmd3] [cmd4] [cmd5] [cmd6] [cmd7] [cmd8] [cmd9] ...堆积
CPU: ████████████████████████████████████(持续满载,无间隙)
↑
例如,这里 cmd2 涉及到耗时的IO命令,阻塞了 5ms
但期间新请求不断到达,epoll 通知立即触发
cmd1 完成后,Redis 疯狂处理积压的 cmd2-cmdN
# 队列堆积触发的连锁反应
请求堆积 → 更多 socket 处于就绪状态 → epoll 频繁触发
→ 更多内存分配(创建客户端对象、响应缓冲区)
→ 内核调度频繁(软中断、上下文切换)
→ 如果开启 AOF,fsync 压力增大
事故发生时,Redis 操作命令的平均耗时急剧上升,也印证了上述分析。
事故总结
这次事故给我们敲响了警钟。在日常需求开发中,任何可能改变数据查询范围、影响调用链路的改动,即使再“小”,也必须提前做好资源影响评估。决不能因为需求简单就掉以轻心。
版本上线后,需要对核心依赖的资源(如数据库、缓存)的各项指标进行持续数天的观察,确保稳定。另一方面,必须建立完善的业务资源压力预警机制,对核心服务的 QPS 突增、CPU、内存、网络等关键指标设置合理的告警阈值,实现问题早发现、早处理。

在 云栈社区 的运维 & 测试和数据库/中间件/技术栈板块,你可以找到更多关于稳定性保障、Redis 性能调优的实战经验和深度讨论。 |  发表于 2026-3-29 01:59:22
|
查看: 126|
回复: 0
发表于 2026-3-29 01:59:22
|
查看: 126|
回复: 0
