事故背景
近期,业务上有一个需求:需要对用户的钱包数据进行处理,回收那些不活跃用户的账户余额。通过大数据平台按照特定规则,我们筛选出了大约 50 万条待处理的用户数据。
接下来,由服务端开发脚本程序来解析和处理这些数据。然而,就在脚本运行过程中,监控系统连续发出了告警,提示脚本服务本身以及上游的核心交易接口都出现了大量超时。

事故排查
接口监控
我们首先查看了相关脚本接口的监控数据,发现其 QPS(每秒查询率)出现了异常暴增,与此同时,接口的响应耗时也同步飙升。这初步指向了脚本接口本身存在异常。
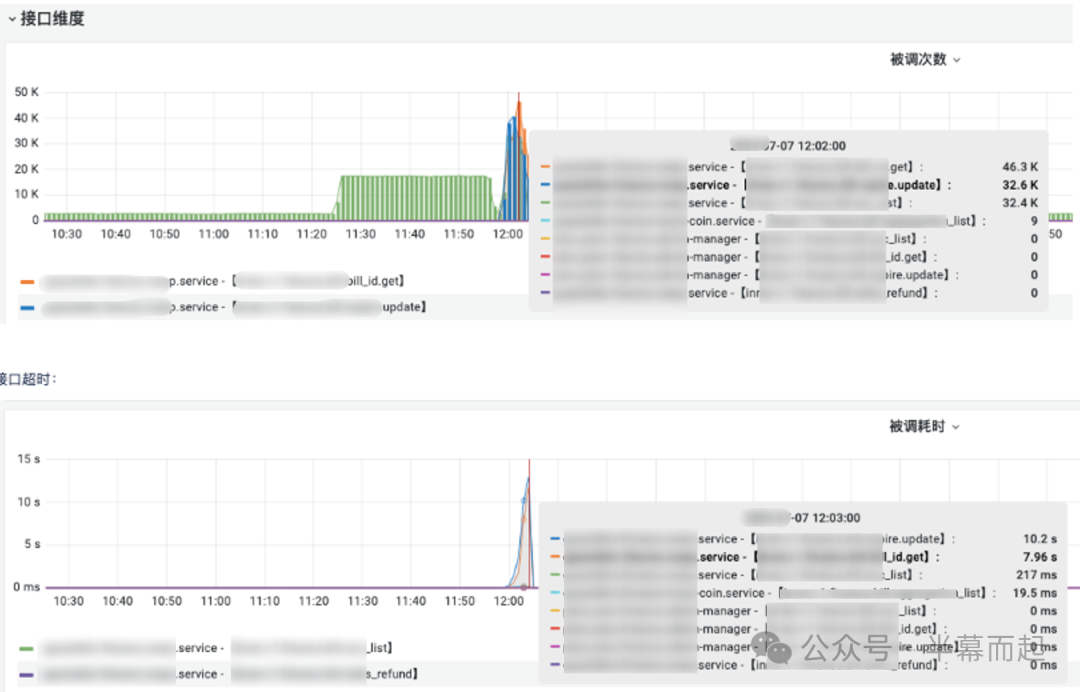
紧接着,我们去服务器上查看了详细的业务日志。日志信息清晰地表明,耗时主要卡在了数据库(DB)相关的操作上,问题大概率出在数据库层。
资源监控
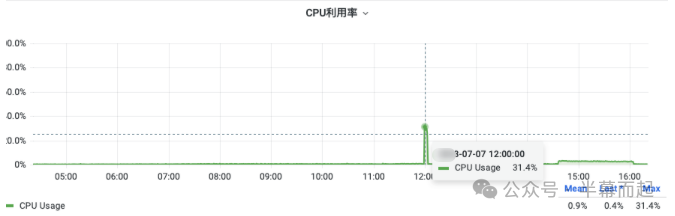
顺着这个思路,我们开始检查相关的资源监控,包括运行脚本的服务器的资源使用情况,以及数据库服务器的资源指标。数据显示,服务器的 CPU 使用率已经飙升至一个非常高的水平。
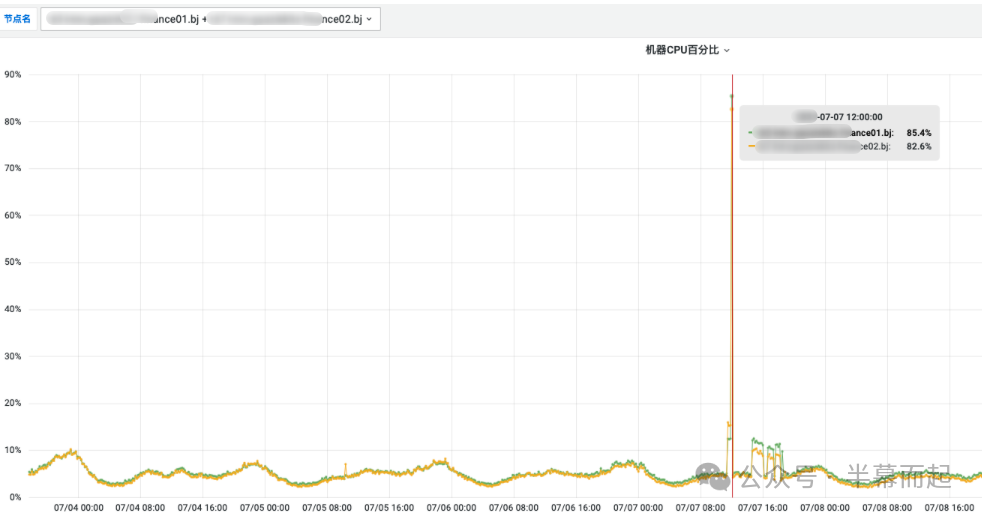
相比之下,数据库服务器的 CPU 使用率虽然有所上升,但远未达到极限。这说明当前的问题并非由数据库的复杂计算或大量数据 I/O 交换所导致。
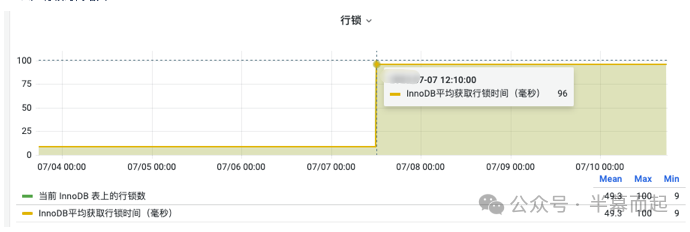
但一个关键指标引起了我们的注意:数据库的行锁平均等待时间出现了异常跃升,从平时的毫秒级猛增至几十甚至上百毫秒。这个信号强烈暗示,系统中存在激烈的锁竞争。
原因分析
结合接口流量突增和资源监控的线索,事故的直接原因变得清晰:脚本接口的异常高并发请求,引发了数据库层面的行锁竞争。锁等待时间的增加,直接导致了依赖该数据库的上游接口处理超时。
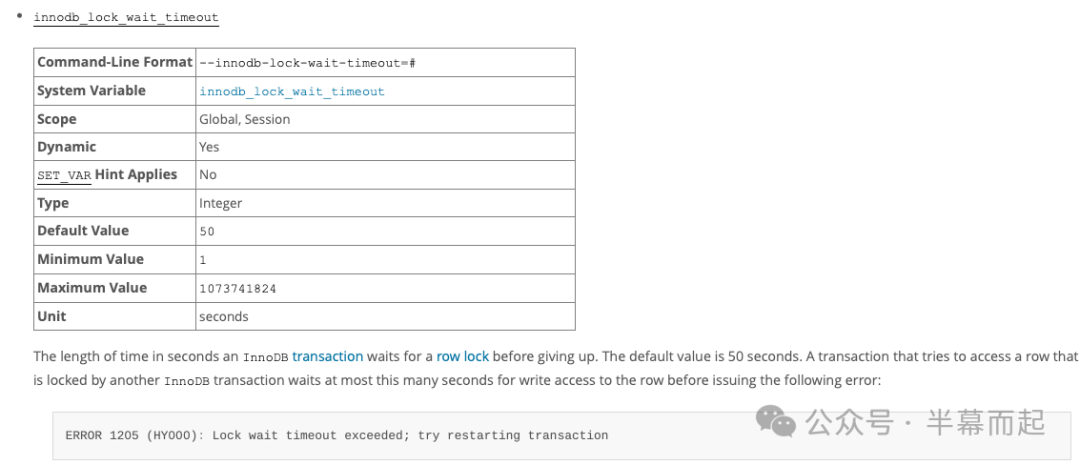
这里涉及 MySQL 的一个重要参数 innodb_lock_wait_timeout,它定义了事务等待行锁的最长时间(默认 50 秒),超时则会报错 ERROR 1205 (HY000): Lock wait timeout exceeded。
同时,我们需要关注 Innodb_row_lock_time_avg 这个状态变量。从监控看到它达到了 96ms 以上,这直接印证了脚本程序在处理数据时,其事务逻辑可能导致了“热点行”更新,从而引发了严重的锁竞争。

因此,问题排查的重心需要转向业务脚本代码,必须重新审视其数据处理流程,检查是否存在大事务,或者在事务内进行了无序的、针对同一热点的行更新。

问题修复
根本原因在于脚本中 Go 协程(goroutine)的并发控制失当。原始代码可能采用了简单的循环遍历,并在循环体内直接创建新的协程来处理每一条数据,这种做法在数据量大时极易瞬间创建海量协程,对下游 MySQL 数据库造成并发冲击。
修复的核心思路是控制并发度。不应无限制地创建协程,而是应该采用更可控的方式,例如:
- 协程池:预先创建固定数量的工作协程,通过 Channel 分发任务。
- 分批处理:将 50 万条数据分成多个批次(比如每批 500 条),串行或使用有限并发处理每个批次。
具体选择哪种方案,需要根据业务逻辑和数据处理特点来决定,但最终目标都是对并发量设置一个明确的上限,避免突发流量对系统造成连锁反应。
下面是一个示例,展示了从“循环内直接开协程”改为“批量同步处理”的简化思路(关键调整在于去除无限制的 go 关键字,并引入分批和间隔):
// 原代码可能类似这样(问题模式):
// for _, item := range hugeList {
// go processItem(item) // 瞬间爆发大量goroutine访问DB
// }
// 修复思路:分批同步处理
func (s *Service) UserBalanceClearProcess(ctx context.Context) {
pageSize := int64(500) // 一次处理500个
// ... 获取总数,循环分页 ...
for page := int64(0); page < totalPage; page++ {
// 1. 获取当前批次数据 userBalanceClears
// 2. 同步处理当前批次
s.DoUserBalanceClear(ctx, userBalanceClears)
// 3. 批次间适当间隔,平滑压力
time.Sleep(time.Millisecond * 500)
}
}

通过上述改造,我们将不可控的千协程齐发,转变为可控的分批平稳处理,从源头上避免了数据库锁竞争的雪崩。这次经历也提醒我们,在处理海量数据时,尤其是在涉及 高并发 写操作的场景下,必须对并发度进行精细的设计和控制。
在 云栈社区 中,我们经常讨论此类因资源竞争导致的服务稳定性问题。良好的架构设计和代码实践是保障系统韧性的基础,希望这个案例能为大家提供一些参考。
 发表于 2026-3-29 02:02:30
|
查看: 101|
回复: 0
发表于 2026-3-29 02:02:30
|
查看: 101|
回复: 0
