事故发生
一个平静的下午,告警电话突然响起,挂断后又不依不饶地再次响起。查看详情,是关于私信接口可用性跌落的告警。心里不禁咯噔一下:可别出什么大问题……
收到的告警信息如下:
[Recovered] S2 - 私信服务可用性低于99
告警来源: 夜莺监控
告警备注: project=message.logic.service,event=RestServe.api.message.logic.send
持续时间: 3m31s

事故排查
1. 日志排查
通过日志平台或登录服务部署机器,快速进行 ERROR 级别的日志筛选,能立即发现明确的错误信息。
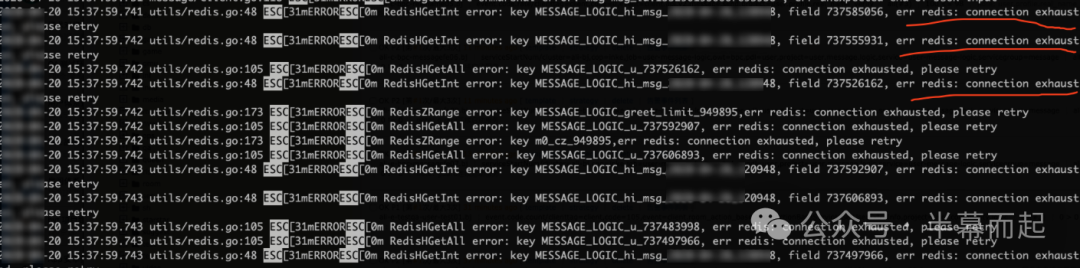
从日志中可以直观地初步定位问题:正是由于 Redis 连接池被耗尽,导致了业务核心私信功能的级联故障。
紧接着,需要紧急联系 SRE 同事,观察 Redis 实例的当前运行状况,判断是否需要立即进行扩容或升级等操作。同时,我们也可以通过命令行快速查看实例的连接数配置上限:
crs-app.host:6379> config get maxclients
1) "maxclients"
2) "10000" // 查看当前默认的最大连接数
2. 指标图排查
接下来需要查看流量监控指标。从下图的监控仪表盘中可以清晰地观察到,私信接口的 QPS(每秒查询率)出现了突发性激增,这很可能就是直接压垮 Redis 连接池的“最后一根稻草”。
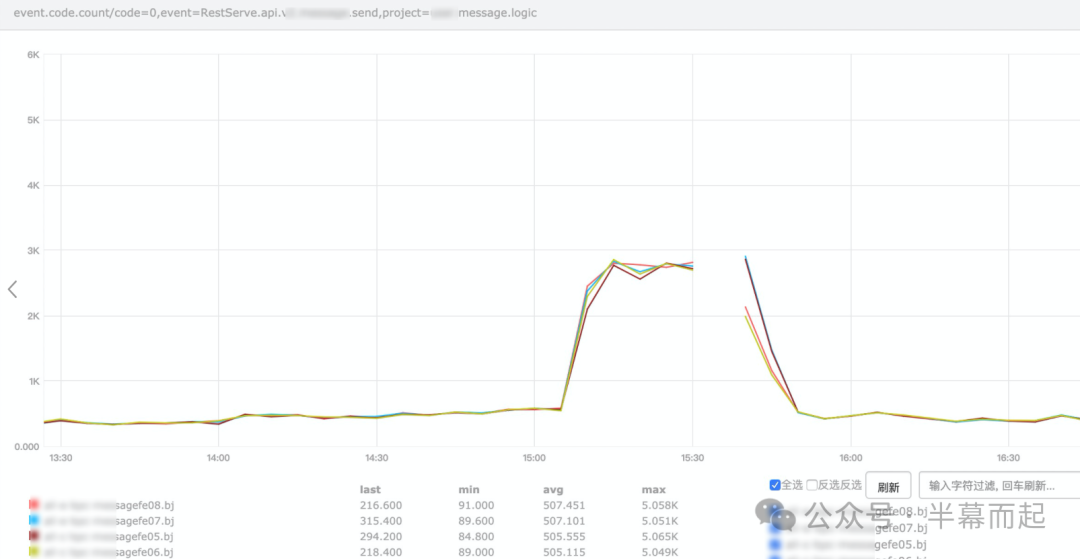
图中明显显示有约 5K 的突发流量请求涌入。一旦锁定了流量源头,就需要立即反馈给上游的服务调用方,协调其进行限流或其他降级处理,从源头上遏制问题。
3. 业务执行原理
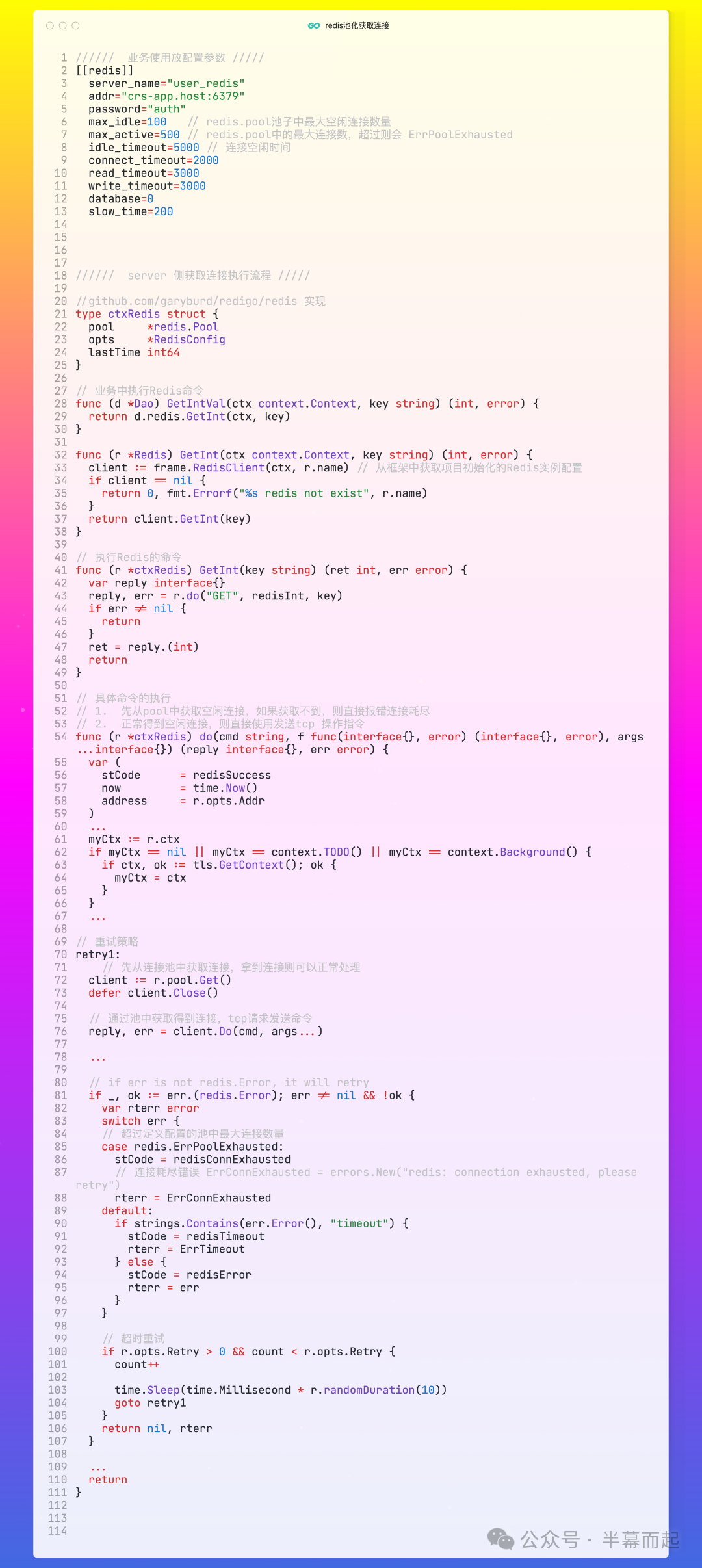
要彻底理解问题,我们需要回顾一下业务代码中是如何操作 Redis 的。下图展示了一段典型的 Go 语言代码,其中涉及了 Redis 连接池的配置和命令执行逻辑。关键参数如 max_active(最大活跃连接数)的设置,在此类故障中扮演着决定性角色。
事故处理
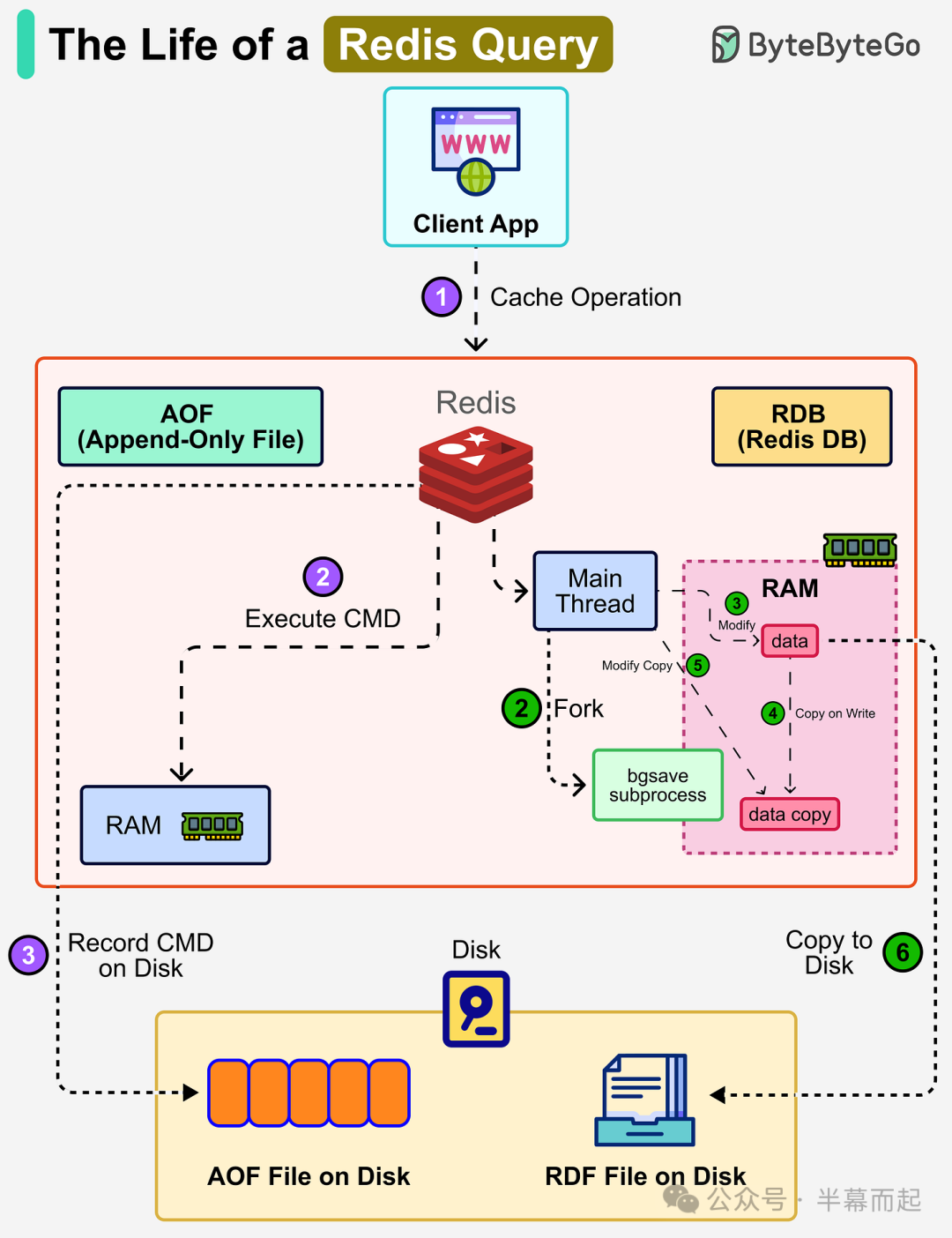
根本原因已经清晰:Redis 实例配置的最大连接数是 10000,但在短时间内持续涌入 4-5K 的连接请求,迅速耗尽了连接池资源。此时,必须分秒必争地进行应急处理。下图概括了一个 Redis 查询的生命周期,帮助我们理解连接使用的各个环节。
应急处理主要遵循两个思路,核心目标是优先恢复服务的可用性。
第一步,同步协调上游调用私信的业务方进行调整,例如实施限流降级,或暂停引发流量的业务脚本等。
第二步,在 Redis 实例层面进行紧急扩容或参数调整。例如,立即放宽 maxclients 连接数上限、缩短空闲连接超时时间 timeout,或者使用 CLIENT KILL 命令优先清理掉异常或空闲过久的连接。
具体的紧急操作命令如下:
# 1. 立刻放宽连接上限(最重要一步!)
CONFIG SET maxclients 100000 # 或更高,根据机器能承受的 fd 数
# 2. 快速清理空闲连接(效果立竿见影)
CONFIG SET timeout 30 # 30秒无操作就自动关闭(生产环境慎用过小值)
# 或者进行更精细的清理操作:
CLIENT LIST | grep idle= # 先观察空闲连接情况
# 杀掉 idle > 300 秒的连接(可写成脚本循环执行)
redis-cli CLIENT KILL oldest # 杀掉最老的连接(Redis 4.0+ 支持)
# 或者杀掉指定 ip:port 的连接
redis-cli CLIENT KILL addr 10.1.2.3:56789
redis-cli CLIENT KILL id 12345

可以将最紧急的处理步骤总结为一个口诀:
先抬 maxclients → 杀 oldest/idle 连接 → 降 timeout → 业务限流/降级 → 事后再优化连接池和代码

总结与反思
在实际生产环境中,必须根据具体的客户端类型、连接池策略、Redis 架构(单实例、集群等),针对不同量级的 QPS 提前做好容量评估和配置优化。
特别需要注意的是,如果业务上计划开展促销活动或存在脚本类的批量任务,务必提前同步信息,进行严格的资源承载力评估。同时,完善的监控与告警体系是稳定性的基石。我们应该提前预设好关键指标埋点,确保在触发告警时,能够有计划、有步骤地执行应急预案,从而保障业务的高可用性。
如果你在 运维 或架构设计中遇到过类似的挑战,欢迎在 云栈社区 分享你的经验与见解。
 发表于 2026-3-29 02:05:12
|
查看: 152|
回复: 0
发表于 2026-3-29 02:05:12
|
查看: 152|
回复: 0
