窗外阴沉沉的,11度多的上海让人完全不想出门。本来只想安静喝杯热咖啡,结果刷GitHub Trending的时候,一个项目让我瞬间清醒了。
不知道你们有没有类似的经历,反正我之前在项目里遇到过。上个月为了给公司内部的一个客服系统增加自动回复和情感分析功能,硬是写了两天的Python胶水代码。流程极其折磨:先从MongoDB里把历史工单抽出来,做数据清洗,然后调用模型生成Embedding向量,再塞到专门的向量知识库里。这还没完,业务端如果想结合Salesforce里的客户续费状态做综合判断,还得再写一段代码来对齐这两边的数据。
这个事情真的很反直觉。只要源头数据有一点变动,整个流程就得跟着调整,维护成本极高。上周五我就因为一个数据同步延迟的问题加了班。我们明明只是想用AI帮我们分析业务数据,为什么非得大费周章地把数据“端”出来,再用一堆臃肿的中间件喂给它呢?
直到我碰到了MindsDB。
一个反直觉的暴力解法:不搬数据了
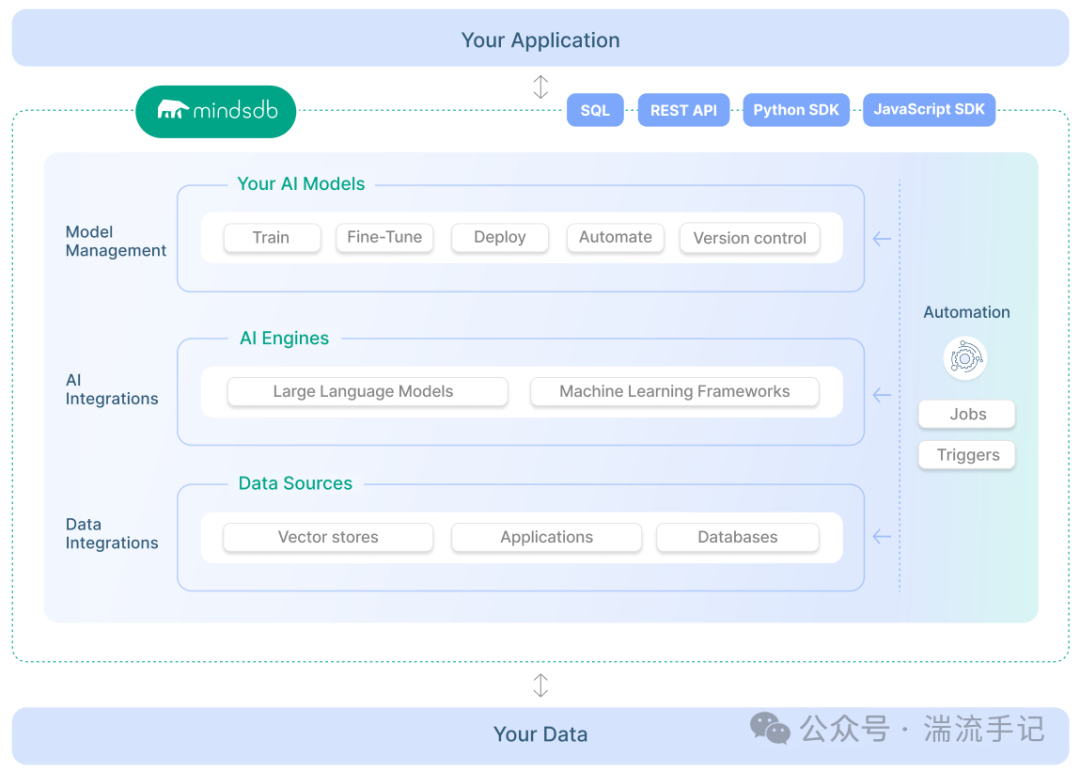
这是一个号称“数据库不可知”的开源AI联邦查询引擎。说直白点,它的核心思路就四个字:就地解决。
它把各种机器学习模型,包括像GPT这样的大语言模型,直接抽象成了数据库里的“虚拟表”。这意味着,你不再需要做繁琐的数据搬运(ETL),敲几行SQL,就能直接在数据源层面完成分析。这个理念在开发者社区评价很高。
这个设计确实巧妙,最吸引我的是下面两点。
它的连接能力非常夸张。现代企业内部的数据源往往很杂,对吧?MindsDB支持连接超过两百种数据源,无论是传统的PostgreSQL、MySQL,还是MongoDB,甚至是Slack聊天记录或Google Drive文档,都能接入。它就像一个超级插线板,提供了一个统一的声明式接口。你写好查询语句,引擎会自动在底层帮你做跨技术栈的聚合。实测发现,原本需要多个API拼凑的逻辑,现在一行SQL就能搞定。
另外,它内置的动态上下文引擎很实用。以前要混合查询关系型数据和非关系型数据,简直是噩梦。现在你可以直接把结构化的表格和非结构化的PDF向量拼在一起查询。比如,用一句SQL,就能把“续约金额大于一百万的头部客户”(结构化元数据)和“他们最近提交过关于数据安全漏洞的工单”(非结构化向量语义检索)进行强关联。这种混合检索的效率,比在应用层写代码硬怼高多了。
在构建智能体(Agent)时,这种就地检索的优势就更明显了。因为Agent是直接部署在数据源旁边的,相当于让AI在“仓库”里自己找“货”,而不是把整个仓库搬到AI面前。这种做法不仅极大降低了调用大模型时的Token消耗,而且由于提供了强有力的业务事实作为支撑,模型“幻觉”的概率也大幅下降。
跑起来看看,顺便排个雷
那么,这东西怎么跑起来?
部署环境门槛不高,只要有一台装了Docker的机器就行。官方提供了多种安装方式,甚至支持PyPI安装包。但我个人最习惯的还是直接拉镜像跑容器,避免污染本地环境。
docker run --name mindsdb_container \
-e MINDSDB_APIS=http,mysql \
-p 47334:47334 -p 47335:47335 \
mindsdb/mindsdb:latest
你可能会问为什么这样写。那个 -e MINDSDB_APIS=http,mysql 环境变量,是告诉容器要暴露哪些交互接口。MindsDB的妙处在于,它把自己伪装成了一个兼容MySQL语法的数据库服务端。另外两个端口中,47334 是它自带的Web UI端口,你可以在浏览器里进行配置;47335 则是MySQL协议端口,你可以用任何顺手的客户端(比如DBeaver或DataGrip)直接连上去敲命令。
我自己部署时也踩过坑。有一次启动容器后,发现它死活连不上我本地测试机上的另一个业务库,报错网络不可达。折腾半天才反应过来是Docker默认网桥隔离的原因。如果你想让它连接宿主机上的其他服务,记得在运行命令里加一个 --network host,或者在填写连接地址时,用 host.docker.internal 代替 localhost。这是个典型的新手坑,不注意就容易卡很久。
等容器跑起来,连上客户端后,你就可以尝试创建跨库视图了。例如,我们可以把MongoDB和Salesforce的数据直接JOIN在一起:
CREATE VIEW risky_renewals AS (
SELECT *
FROM mongodb.support_tickets AS reviews
JOIN salesforce.opportunities AS deals
ON reviews.customer_domain = deals.customer_domain
WHERE deals.type = "renewal"
AND reviews.sentiment = "negative"
);
这段SQL看起来平平无奇,但信息量很大。它跨越了两个完全不同的数据库系统,直接进行了一次跨库关联。你不需要写任何代码去同步这两边的数据,直接通过客户域名把它们关联起来,就能筛选出那些“处于续费期、但最近工单情绪是负面”的高危客户。对于运营同学来说,这种直接出结果的体验非常爽。
有了数据基础,再去拉起一个AI Agent就顺理成章了。
CREATE AGENT my_agent
USING
model = {
"provider": "openai",
"model_name" : "gpt-4o",
"api_key": "sk-..."
},
data = {
"knowledge_bases": ["mindsdb.customer_issues"],
"tables": ["salesforce.opportunities", "mongodb.support_tickets"]
},
prompt_template = '你是资深客服主管,请根据提供的工单数据分析客户流失风险...';
这里的建表语法被巧妙地用在了构建大模型应用上。data 字段就是授予这个AI权限,让它能同时从结构化业务表和向量知识库里查询。只要这个Agent创建完毕,你就可以像查询普通数据表一样向它提问,甚至可以用触发器把它的回答推送到外部应用。
把模型当成数据表来操作,这个思路确实清奇。
说句不好听的,它适合谁?
其实任何工具都有自己的局限性。MindsDB也不是没有缺点,我们得客观看看它的适用边界。
在这个领域,大家最容易拿来比较的就是PostgresML和LangChain。
如果纯粹追求单点极致的推理性能,老牌的PostgresML确实更快,因为它是一个深度绑定在PostgreSQL里的原生插件。但它的短板也很明显:生态封闭。如果你们公司的业务数据正好全在PG里还好,要是混搭了别的数据源,就不好办了。
另一头,像LangChain这种纯应用层的编排框架,或者像Databricks这种云端重量级方案,生态庞大、极其灵活。但代价是什么?前者往往需要你维护大量脆弱的胶水代码,后者则可能让你陷入昂贵的供应商锁定。MindsDB刚好巧妙地切入了一个中间地带:它开源、轻量,用普通的SQL语句就把开发门槛降下来了。
不过有个问题你得知道。它号称用SQL解决一切,但这套带有浓厚自定义风格的AI SQL方言,本身就是一层新的抽象。你得习惯这种把大模型当做表来查的思维方式,这有点违背常规的增删改查直觉。
更要命的是,如果你是在几千TPS这种极高并发的大规模生产环境里跑核心业务,MindsDB目前单节点的水平扩展能力可能是个挑战。社区里也有反馈,它暂时还缺乏一套被广泛验证过的高可用部署官方最佳实践。
所以,如果你的场景是极其苛刻的超高并发交易链路,现阶段可能需要慎重评估。但如果是用于内部运营分析系统、对话式分析助手,或者是客服工单的智能路由,这绝对是一个能让你少加很多次班的利器。
咖啡凉透了,不说了,我去把上周写的那些烂尾脚本删了。
References:
本文技术观点由云栈社区整理分享,一个专注于开发者实战与前沿技术交流的社区。
 发表于 2026-3-30 02:35:48
|
查看: 196|
回复: 0
发表于 2026-3-30 02:35:48
|
查看: 196|
回复: 0
