当你在嵌入式Linux开发中调试一个崩溃的程序时,是不是常常觉得无从下手?面对终端里一句冰冷的 “Segmentation fault (core dumped)”,新手可能两眼一黑,老手也得在脑海中快速排查各种可能性。程序崩溃的原因五花八门,但归根结底,它们通常可以归入几大类。在深入具体的代码行之前,建立一个全局的“崩溃全景图”,能帮你快速定位问题方向。
一、崩溃全景图
嵌入式软件的崩溃,大体上可以归纳为以下四大类,这张分类图可以帮助你建立初步的印象:
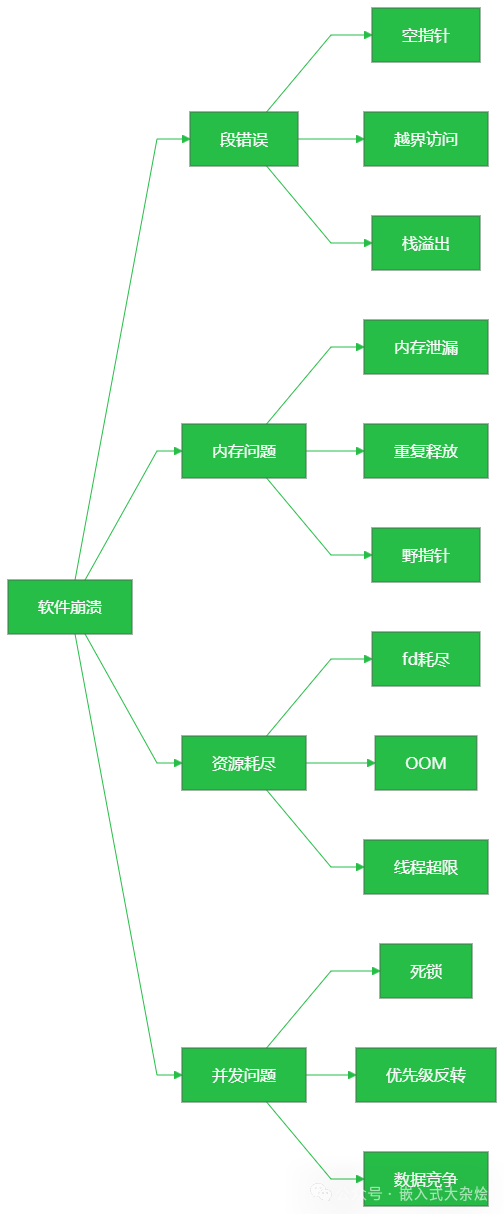
接下来,我们将逐一拆解这些类型,通过具体的代码示例来理解它们是如何发生的,以及如何预防。
二、段错误 (SIGSEGV)
这是内核给你的一个明确信号:程序访问了它不该访问的内存地址。在嵌入式C/C++开发中,这恐怕是你遇到最多的崩溃类型。
2.1 空指针访问
来看一个经典的“空指针解引用”场景:
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int id;
char name[32];
} Device;
Device* find_device(int id){
// 查找失败,返回NULL
return NULL;
}
int main(){
Device *dev = find_device(100);
// 危险:未检查返回值
printf("Device name: %s\n", dev->name); // SIGSEGV!
return 0;
}
运行后,你会看到类似下面的错误:
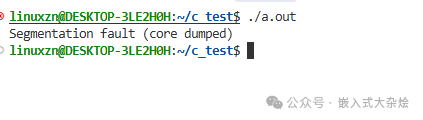
此时,用 dmesg 命令查看内核日志,通常会看到 segfault at 0,地址0正是NULL指针的特征。问题根源在于函数返回NULL后,调用者没有进行有效性检查就直接解引用。
这在嵌入式开发中极其常见——硬件初始化失败、配置解析出错、资源未就绪,都可能返回NULL。黄金法则: 对所有可能返回NULL的指针,使用前必须进行“三重检查”:是否初始化?是否为NULL?是否指向有效的内存区域?
2.2 数组越界访问
越界写入是另一个段错误的常见来源:
#include <stdio.h>
#include <string.h>
void parse_command(const char *cmd){
char buffer[16];
// 危险:未限制拷贝长度
strcpy(buffer, cmd); // 如果cmd超过15字节,栈被破坏
printf("Command: %s\n", buffer);
}
int main(){
// 构造超长输入
char evil_cmd[64] = "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA";
parse_command(evil_cmd); // 崩溃或行为异常
return 0;
}
程序可能会立即报段错误,也可能在函数返回时崩溃(因为返回地址被覆盖了)。运行结果示例如下:
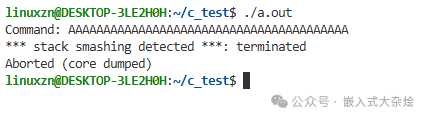
罪魁祸首是 strcpy,它从不关心目标缓冲区的大小。当嵌入式设备处理来自网络或串口的外部协议数据时,这类问题尤其危险。解决方案: 使用 strncpy 或更安全的 snprintf,并始终指定最大拷贝长度。
2.3 栈溢出
栈空间是有限的,深层递归或分配大数组可能导致它耗尽:
#include <stdio.h>
void recursive_parse(int depth){
char local_buffer[1024]; // 每层调用消耗1KB+栈空间
sprintf(local_buffer, "depth=%d", depth);
recursive_parse(depth + 1); // 无终止条件
}
int main(){
recursive_parse(0); // 很快栈耗尽,SIGSEGV
return 0;
}
这种崩溃的地址通常看起来比较“合理”(靠近栈底)。预防措施: 尽量避免深递归,用迭代替代;大的局部数组请使用堆内存(malloc)。
三、内存问题
与段错误的“立毙”不同,内存问题更像是“慢性毒药”,程序往往运行一段时间后才暴露问题。
3.1 内存泄漏
内存只申请不释放,资源终将枯竭:
#include <stdlib.h>
#include <string.h>
char* process_message(const char *raw){
char *buffer = malloc(256);
if (!buffer) return NULL;
// 处理逻辑...
if (strlen(raw) > 200) {
return NULL; // 危险:提前返回,buffer未释放!
}
strcpy(buffer, raw);
return buffer;
}
int main(){
for (int i = 0; i < 100000; i++) {
char *msg = process_message("short message");
// 假设调用者也忘记free...
}
// 内存持续增长,最终OOM
return 0;
}
程序会越跑越慢,通过 /proc/<pid>/status 查看 VmRSS(常驻内存)会发现它持续增长,最终可能被系统的OOM Killer终结。内存泄漏最容易出现在复杂的错误处理分支中。建议: 使用如 Valgrind 等工具定期进行内存检查。
3.2 重复释放 (Double Free)
对同一块内存调用两次 free 是未定义行为:
#include <stdlib.h>
int main(){
char *ptr = malloc(100);
free(ptr);
// ... 中间很多代码 ...
free(ptr); // Double free! 行为未定义
return 0;
}
现代的 glibc 通常会检测到这种操作并终止程序:
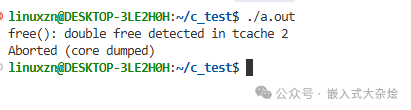
问题的关键在于,第一次释放后,指针 ptr 并未被置为 NULL,在复杂的控制流中,它可能被误认为仍然有效而被再次释放。一个好习惯是:free(ptr); ptr = NULL;。
3.3 野指针 (Use After Free)
访问已经被释放的内存是调试者的噩梦:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(){
char *name = malloc(32);
strcpy(name, "sensor_01");
free(name);
// 危险:内存已释放,但指针还能用(暂时)
printf("Name: %s\n", name); // 可能打印乱码,可能崩溃
char *other = malloc(32); // 可能分配到同一块内存
strcpy(other, "XXXXXXXX");
printf("Name: %s\n", name); // 现在打印XXXXXXXX!数据被污染
return 0;
}
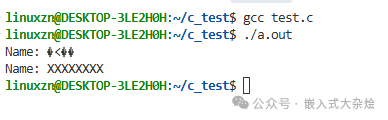
这种问题不一定立即崩溃,可能导致数据错乱或随机性行为,极难复现和定位,因为崩溃点和真正的bug可能相隔十万八千里。强力工具: Clang/GCC 的 AddressSanitizer (ASan) 是检测这类问题的利器。
四、资源耗尽
除了内存,文件描述符、线程数等系统资源也是有限的。
4.1 文件描述符耗尽
打开文件或套接字后忘记关闭:
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
void read_config(){
int fd = open("/etc/config.txt", O_RDONLY);
if (fd < 0) return;
char buf[128];
read(fd, buf, sizeof(buf));
// 危险:忘记close(fd)
}
int main(){
for (int i = 0; i < 2000; i++) {
read_config(); // 每次泄漏一个fd
}
// 后续所有open/socket都会失败
int fd = open("/tmp/test", O_RDONLY);
printf("fd = %d\n", fd); // 输出-1,errno=EMFILE
return 0;
}

程序不会段错误,但后续所有依赖文件描述符的操作(open, socket, accept等)都会失败。嵌入式设备的文件描述符限制通常较低(默认1024)。可以用 ls /proc/<pid>/fd | wc -l 查看进程当前使用的fd数量。
4.2 OOM Killer
当系统物理内存严重不足时,内核的“OOM Killer”会出手“干掉”一个进程来保全系统:
#include <stdlib.h>
#include <string.h>
int main(){
while (1) {
char *p = malloc(1024 * 1024); // 每次1MB
if (p) memset(p, 0, 1024 * 1024);
// 永不释放
}
return 0;
}
进程会被 SIGKILL 信号无情终止。查看 dmesg 内核日志,你会找到类似 Out of memory: Kill process ... 的记录。Linux 默认的 overcommit 机制允许程序申请超过物理内存的空间,但在实际用到这些内存时,如果系统无法满足,OOM Killer 就会启动。
五、并发问题
对于多线程程序,并发问题是隐藏最深、最棘手的“杀手”。
5.1 死锁
经典的 AB-BA 死锁模式:
#include <pthread.h>
#include <stdio.h>
pthread_mutex_t lock_a = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t lock_b = PTHREAD_MUTEX_INITIALIZER;
void* thread1(void *arg){
pthread_mutex_lock(&lock_a);
usleep(1000); // 增加死锁概率
pthread_mutex_lock(&lock_b); // 等待lock_b
printf("Thread 1 got both locks\n");
pthread_mutex_unlock(&lock_b);
pthread_mutex_unlock(&lock_a);
return NULL;
}
void* thread2(void *arg){
pthread_mutex_lock(&lock_b);
usleep(1000);
pthread_mutex_lock(&lock_a); // 等待lock_a,死锁!
printf("Thread 2 got both locks\n");
pthread_mutex_unlock(&lock_a);
pthread_mutex_unlock(&lock_b);
return NULL;
}
int main(){
pthread_t t1, t2;
pthread_create(&t1, NULL, thread1, NULL);
pthread_create(&t2, NULL, thread2, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL); // 永远不会返回
return 0;
}
程序会完全“卡死”,CPU 使用率变为 0。从下面的时序图可以清晰看到两个线程如何陷入互相等待的境地:
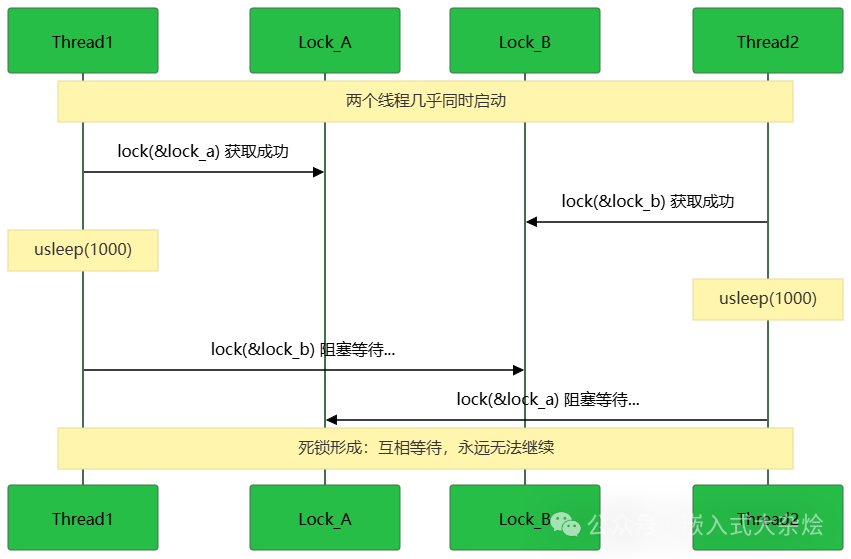
两个线程以相反的顺序(A->B 和 B->A)请求两把锁,在特定的竞争时序下,它们各自持有一把锁并等待对方释放另一把,从而形成永久的等待。
修复方案:统一加锁顺序
解决死锁最直接的方法就是确保所有线程以相同的顺序获取锁。
void* thread1(void *arg){
pthread_mutex_lock(&lock_a); // 先A
pthread_mutex_lock(&lock_b); // 后B
printf("Thread 1 got both locks\n");
pthread_mutex_unlock(&lock_b);
pthread_mutex_unlock(&lock_a);
return NULL;
}
void* thread2(void *arg){
pthread_mutex_lock(&lock_a); // 先A(与thread1顺序一致)
pthread_mutex_lock(&lock_b); // 后B
printf("Thread 2 got both locks\n");
pthread_mutex_unlock(&lock_b);
pthread_mutex_unlock(&lock_a);
return NULL;
}
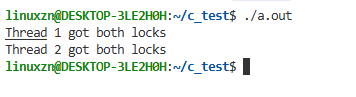
修复后,程序能顺利执行并输出:
5.2 数据竞争
当多个线程同时读写一个共享变量而未加保护时,就会发生数据竞争:
#include <pthread.h>
#include <stdio.h>
int counter = 0; // 共享变量,无锁保护
void* increment(void *arg){
for (int i = 0; i < 100000; i++) {
counter++; // 非原子操作!
}
return NULL;
}
int main(){
pthread_t t1, t2;
pthread_create(&t1, NULL, increment, NULL);
pthread_create(&t2, NULL, increment, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("Counter = %d (expected 200000)\n", counter); // 实际结果远小于200000
return 0;
}
运行结果并非预期的 200000:
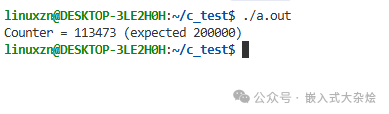
虽然这里程序没有崩溃,但得到了错误的结果。在更复杂的场景下(如操作链表),数据竞争很可能直接导致数据结构损坏进而崩溃。问题的根源在于 counter++ 并非原子操作,它在汇编层面是“读-改-写”三个步骤,多线程交错执行会导致更新丢失。
我们通过两张图来理解这个问题:
- 实际发生的竞争情况:两个线程几乎同时读取旧值(0),然后各自加1后写回,导致最终结果丢失了一次更新。
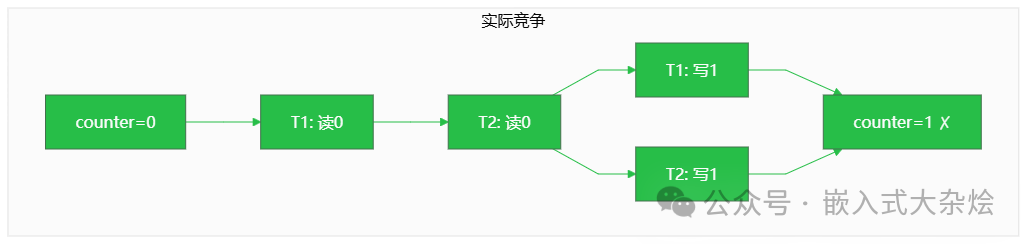
- 理想情况:操作被正确序列化,最终得到正确结果。

| 修复方案对比: |
方案 |
实现 |
性能 |
适用场景 |
| 互斥锁 |
pthread_mutex_lock/unlock |
较低 |
复杂的临界区操作 |
| 原子操作 |
__atomic_add_fetch 或 C11 atomic_* |
高 |
简单的计数器、标志位 |
| 自旋锁 |
pthread_spin_lock |
高(短临界区) |
嵌入式实时场景,不允许睡眠 |
使用原子操作修复的示例代码如下(C11标准):
#include <pthread.h>
#include <stdio.h>
#include <stdatomic.h>
atomic_int counter = 0; // 原子变量
void* increment(void *arg) {
for (int i = 0; i < 100000; i++) {
atomic_fetch_add(&counter, 1); // 原子自增
}
return NULL;
}
// ... main函数创建线程等代码不变
// 输出: Counter = 200000 √
六、总结与工具推荐
上面梳理的这12种崩溃场景,基本上覆盖了嵌入式Linux开发中90%以上的问题。你可以根据下表快速归类并选择调试工具:
| 崩溃类型 |
典型特征 |
首选调试分析工具 |
| 段错误 (SIGSEGV) |
立即崩溃,dmesg 或 coredump 中有非法内存地址 |
GDB + Core Dump |
| 内存问题 |
延迟暴露,行为随机,内存持续增长或重复释放 |
Valgrind / AddressSanitizer (ASan) |
| 资源耗尽 |
相关系统调用(open, socket等)开始失败,返回错误码 |
监控 /proc/<pid>/fd, /proc/<pid>/status |
| 并发问题 |
程序卡死(死锁) 或 结果非预期(数据竞争) |
GDB 多线程调试,Helgrind (DRD), ThreadSanitizer (TSan) |
无论是空指针、内存泄漏还是死锁,理解其背后的原理是预防的第一步。在云栈社区的嵌入式板块里,开发者们经常分享和讨论这些实际工程中遇到的棘手问题以及排查心得。希望这份“崩溃图谱”能成为你下次调试时的有效参考,快速定位问题根源,而不是在茫茫代码中盲目搜索。
 发表于 2026-3-30 02:57:05
|
查看: 180|
回复: 0
发表于 2026-3-30 02:57:05
|
查看: 180|
回复: 0
