单纯在网页中嵌入JSON-LD结构化数据,对提升RAG系统的准确率帮助甚微——这是许多开发者的直觉,如今被一项研究证实。然而,当我们将这些“隐形”的数据转化为一种名为“增强型实体页面”的显性格式后,RAG的准确率实现了近30%的显著跃升。
这篇来自WordLift团队的研究论文,通过系统性的实验揭示了这一关键发现。研究团队设计了7种不同的实验条件,横跨编辑、法律、旅游、电商四大领域,并进行了多达2,443次独立评估,得出以下核心数据:
- 在纯HTML页面基础上仅添加JSON-LD块,带来的准确率提升微乎其微(仅+0.17,效应量d=0.18)。
- 将JSON-LD转化为 “增强型实体页面” 后,在标准RAG流程中准确率提升 +29.6%,在更复杂的Agentic RAG流程中提升 +29.8%。
- 效果最强的“增强+”版本(Enhanced+)达到了最高的绝对分数,平均准确率为4.85(满分5分)。
方案原理
核心架构
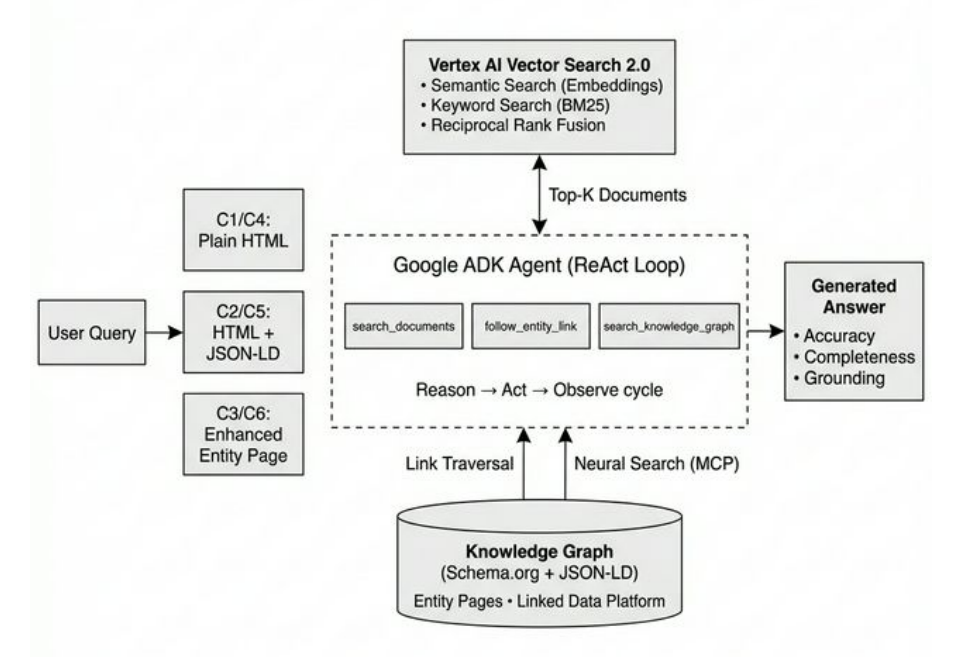
为了验证这一想法,研究团队构建了一个模拟Google AI Mode的实验系统,其架构分为三层:
- 检索层:基于Google的Vertex AI Vector Search 2.0,它融合了语义搜索(Embeddings)、关键词搜索(BM25)以及 Reciprocal Rank Fusion 技术。
- 推理层:核心是Google Agent Development Kit(ADK)驱动的智能代理,支持ReAct式多步推理循环。
- 数据层:由WordLift提供的知识图谱,其中的实体均采用带有可解析URI的Schema.org标准进行描述。
下图清晰地展示了这个代理式RAG系统的工作流程:
增强型实体页面设计
那么,什么是“增强型实体页面”?它与我们熟悉的、隐藏在<script>标签里的JSON-LD块有本质区别。增强页面致力于将结构化数据“显性化”和“可操作化”,主要包括以下元素:
- 自然语言摘要:从结构化数据中自动生成的一段人类可读的描述文本。
- 可见的实体导航:以链接形式展示与该实体相关的其他实体,每个链接都指向知识图谱中可解析的URI。
llms.txt风格指令:像为AI代理编写的“说明书”,明确告知它如何处理该页面的信息,例如优先返回哪些属性。- Schema.org面包屑导航:展示实体在Schema.org类型体系中的层级路径,提供丰富的上下文。
- 神经搜索技能引用:支持代理进行跨实体的深度发现与关联。
下面的对比图直观展示了从“纯HTML”到“增强型实体页面”的转变,以及带来的显著效果提升:

Agentic RAG工作流
在这个架构中,AI代理并非魔法。它通过调用三种定义好的工具进行协同工作:
search_documents: 执行传统的向量检索,获取相关的文档片段。follow_entity_link: 通过内容协商机制,智能地解析页面中实体链接的URI,可以获取JSON-LD、Turtle或HTML等不同格式的实体描述。search_knowledge_graph: 在知识图谱中进行神经搜索,发现跨图谱的深层关联。
代理被允许执行最多2跳的链接遍历。实验数据显示,平均每个查询会调用2.0次工具,体现了其多步推理的特性。
关键结论
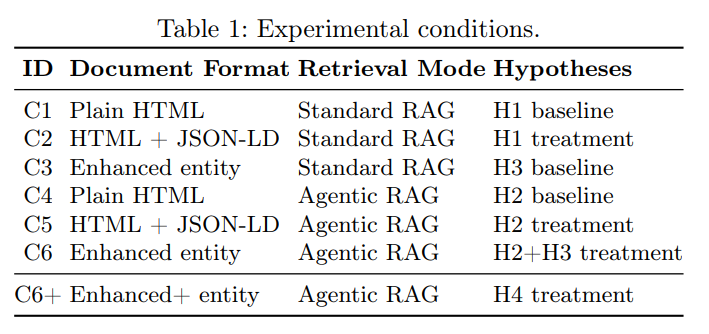
为了系统评估各种因素,研究设置了如下表所示的实验条件:
为什么单独的JSON-LD不够用?
研究指出了一个普遍问题:当前大多数RAG系统在摄入文档时,将整个页面视为“扁平的文本流”。JSON-LD块在这种处理方式下,很容易在分块(Chunking)过程中被意外截断,或者其结构化信息被淹没在海量文本中。实验结果也证实,在这种扁平架构下,添加JSON-LD带来的增益几乎可以忽略不计(虽有统计学显著性p=0.024,但效应量极小)。
增强页面的“链接物化”机制
“增强型实体页面”成功的核心,在于它实现了一种 “链接物化” 机制。简单来说,它把知识图谱中需要通过链接跳转才能获取的信息,“提前”渲染到了当前页面上。
- 纯HTML页面:可能只包含一个指向某地点的URI,如
data.wordlift.io/wl12345。
- 增强型实体页面:系统会预先解析这个URI,将该地点的坐标、价格、营业时间等属性,直接以自然语言文本的形式展示出来。
这使得LLM在单次检索中就能获得原本需要多跳遍历才能得到的信息,极大提升了信息获取的效率和完整性。这正是 RAG 系统追求的关键目标之一。
Agent的互补角色
一个有趣的发现是:当文档格式本身已经优化得很好时(如增强页面),引入复杂的Agent几乎不会带来额外的准确率提升(条件C3准确率4.69 vs 条件C6准确率4.70)。那么,Agent的价值在哪里?
- 补偿劣质内容:在仅有纯HTML的劣质内容上,Agent能通过其多步推理和链接跟随能力,将准确率提升+0.74。
- 提升检索效率:即使在信息丰富的增强页面上,Agent也能更“聪明”地工作。数据显示,在增强页面的基础上使用Agent,其需要主动跟随的链接数从1.0次下降到了0.4次,但最终答案的准确率反而更高。这说明Agent学会了更有效地利用已呈现的信息。
领域差异性
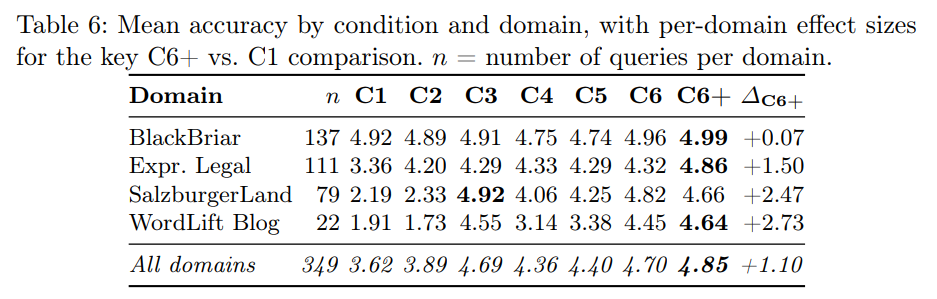
“增强实体页面”的效果并非放之四海而皆准,它与领域特性强相关:
- 电商领域(实验代号BlackBriar):基线准确率本身就很高(4.92),因此提升最小(+0.07)。这是因为产品页面通常已经包含了丰富、结构化的产品事实信息。
- 旅游领域(实验代号SalzburgerLand):基线很低(2.19),提升却最大(+2.47)。究其原因,许多关键信息(如景点坐标、餐厅菜系)原本仅存在于后台知识图谱中,并未在HTML页面上直接展示,而增强页面恰好补全了这块短板。
- 编辑与法律领域:则处于中间位置,获得了中等程度的提升(+1.50至+2.73)。
不同领域的详细效果对比如下表所示:
实践启示
对RAG系统设计的建议
这项研究为构建更高效的 RAG 系统提供了明确的工程方向:
- 结构化数据感知摄入:RAG的文档处理流水线应该像Google爬虫一样,具备识别并单独提取HTML中JSON-LD等结构化数据块的能力,而不是简单地将它们与其他文本混合处理。
- 实体感知分块:在文档分块时,需要采用更智能的策略,避免在固定的字符边界处粗暴地截断一个完整的结构化数据块,导致语义断裂。
- 混合检索策略:结合向量相似性搜索与基于知识图谱的语义遍历,让系统既能把握上下文相关性,又能进行精准的事实关联。像论文中使用的 Google ADK Agent 就展示了这种混合工作流的强大潜力。
实现可信度
“增强型实体页面”还解决了一个重要的可信度问题:它确保了 “人机同源” 。AI模型所“看到”的结构化数据,与人类用户通过浏览器看到的HTML可视化内容,是从同一个URI通过内容协商服务提供的、完全一致的信息。这避免了为“AI优化”而单独创建一套内容所导致的“双轨制”风险,即AI答案与真实网页内容脱节,从根本上保障了信息源的真实性与一致性。
论文核心价值:这项研究不仅验证了语义网和关联数据技术在生成式AI时代的巨大应用价值,更重要的是,它提供了一个可立即落地实施的“增强实体页面”具体模板。这为RAG系统从简单的“文档检索与排名”范式,向更高级的“基于结构化知识的推理优化”范式演进,提供了坚实的实证基础与可行的技术路径。
论文标题:Structured Linked Data as a Memory Layer for Agent-Orchestrated Retrieval
论文地址:https://arxiv.org/pdf/2603.10700
如果你对如何具体实现这样的 知识图谱 增强系统,或者想深入探讨更多Agent与RAG的结合案例,欢迎到 云栈社区 的对应板块交流讨论。
 发表于 2026-3-30 04:25:39
|
查看: 188|
回复: 0
发表于 2026-3-30 04:25:39
|
查看: 188|
回复: 0
