原论文信息如下:
论文标题: PoseDriver: A Unified Approach to Multi-Category Skeleton Detection for Autonomous Driving
发表日期: 2026年03月
发表单位: Ecole Polytechnique Federale de Lausanne (EPFL,瑞士联邦理工学院)
原文链接: https://arxiv.org/pdf/2603.23215v2.pdf
开源数据集链接: MS COCO Bicycle (论文作者构建的自行车关键点数据集)
想象一下,你正在开车。前方一个行人突然停下脚步,转头看向马路对面——他要过马路吗?旁边车道的汽车,车头微微向左偏,是不是要变道?远处蜿蜒的车道线,在雨夜中若隐若现,它的准确走向是什么?
传统的自动驾驶感知系统,可能会用一个方框(Bounding Box)把人圈出来,或者用一条粗线把车道标出来。但这种信息太“粗糙”了。方框不知道行人头朝哪边,粗线也搞不清车道具体的弯曲形态。要让机器真正理解场景、做出精准预判,我们需要一种更细腻、更本质的表示方法。
这,就是“骨架”(Skeleton)。就像我们用寥寥几笔就能画出一个人的动态,骨架表示法抓取的是物体的核心“关节”和“骨骼”连接。对于自动驾驶,如果能同时抓取出行人、车辆、自行车乃至车道线的骨架,那感知系统就真的拥有了“透视眼”,能读懂场景的结构和意图。
今天要聊的这篇来自瑞士联邦理工学院(EPFL)的论文《PoseDriver》,就提出了一个统一的框架,让一个模型同时学会检测五大类目标的骨架——行人、动物、汽车、自行车,还有车道线。没错,它甚至把车道线也“骨架化”了!
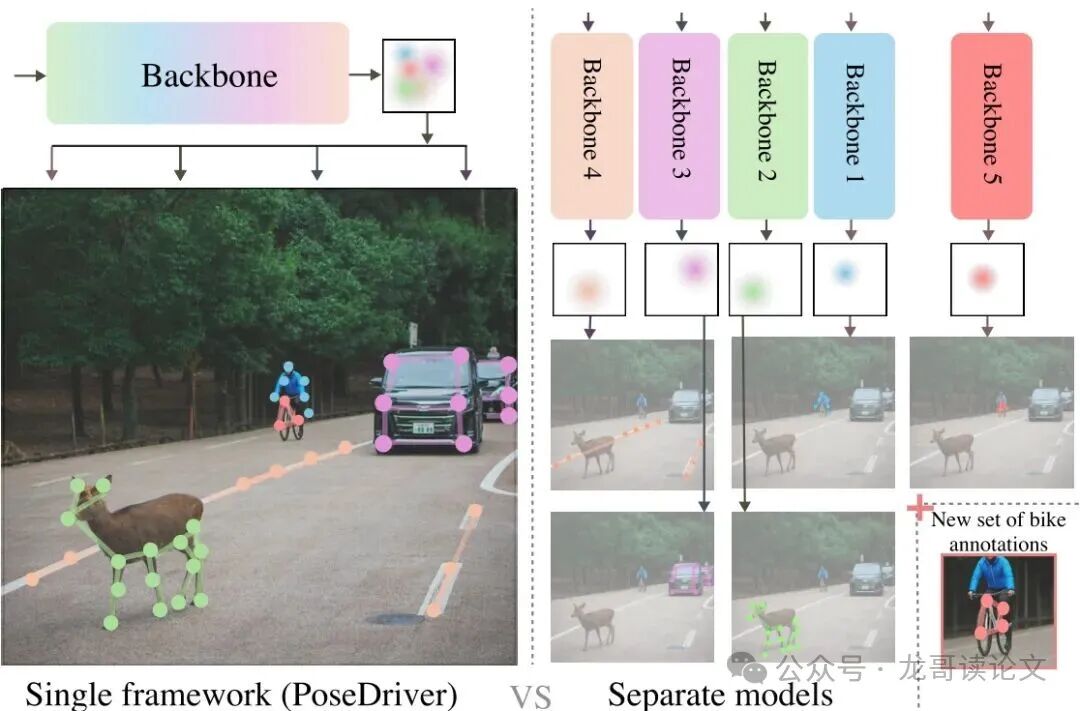
图1:骨架检测为自动驾驶提供了一种详细而轻量的环境表示。我们的目标是联合检测动态道路使用者(汽车、人、动物)以及静态道路结构(车道线)的骨架,以获得车辆周围环境的综合表征。
统一骨架感知:自动驾驶环境理解新范式
在深度学习感知任务里,我们见过各种“表示法”。边界框(Bounding Box) 告诉你“物体在哪”,分割掩码(Segmentation Mask) 告诉你“物体的轮廓是什么”。而骨架(Skeleton),则试图揭示“物体的结构如何”。
比如行人,骨架就是17个身体关键点(头、肩、肘、膝等)及其连接;对于汽车,可能是车轮、车灯、后视镜等关键部位。这种表示非常紧凑,却包含了姿态、朝向等对预测意图至关重要的信息。
PoseDriver的核心愿景,是建立一个统一的、自底向上的(Bottom-up)多类别骨架检测框架。这里有两个关键词:
自底向上(Bottom-up): 与“自顶向下(Top-down)”(先检测物体框,再在框内检测关键点)不同,自底向上方法先一口气检测出图像中所有类别的所有关键点,然后再把这些点“组装”成一个个物体的骨架。这种方法在人群密集、遮挡严重的场景下更有优势。
多类别(Multi-category): 这是本文的难点和亮点。以前的工作大多只专注于某一类,比如只做行人姿态估计。而PoseDriver要同时处理五个差异巨大的类别:可变形的(行人、动物)、刚性的(汽车、自行车),以及一个非常特殊的类别——车道线。
把车道线也纳入骨架检测的范畴,这个想法本身就很大胆。
车道线变骨架:突破传统检测的思维定式
车道线检测是个老课题了,方法五花八门:有把它当分割问题做的,有设计各种“锚点”(Anchor)去拟合的,还有用多项式或贝塞尔曲线来回归的。但PoseDriver的作者们提出了一个关键问题:为什么不能把一条车道线也看作是一串“关键点”呢?
当然,这里的“关键点”没有像“左膝盖”那样的语义,它只是车道线上一些均匀分布的结构点。PoseDriver为每条车道线预测固定数量(比如M个)的二维坐标点,这些点按顺序连接起来,就构成了车道的“骨架”。
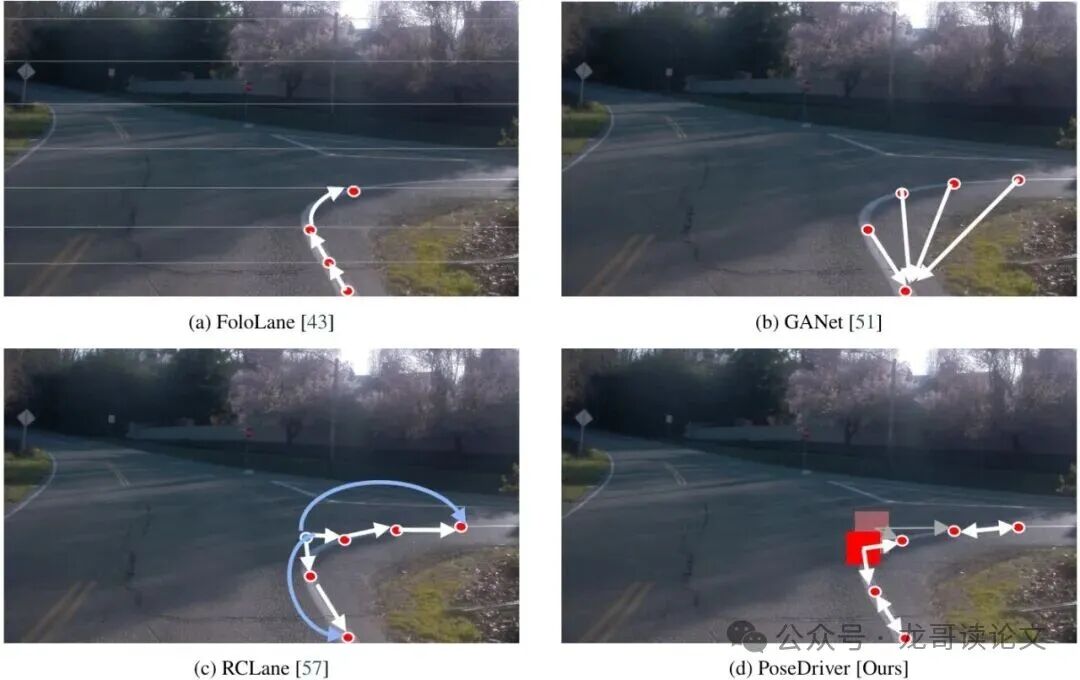
图2:基于骨架的车道线检测方法的关联策略比较。(a) FoloLane采用局部迭代方式。(b) GANet将每个关键点回归到其起始点。(c) RCLane将车道建模为接力链。(d) PoseDriver使用强度场和关联场联合估计关键点位置和关联。
这样做的好处是什么?
统一表示,统一处理: 车道检测被无缝地纳入了同一个骨架检测框架。模型不需要为车道线单独设计一套复杂的后处理逻辑。
天然保持拓扑连续性: 通过预测“关联场”,模型在输出点的同时,也输出了点与点之间的连接关系。这意味着,即使车道线中间被车辆遮挡了一部分,模型也能依靠关联场“脑补”出完整的、连续的车道骨架,避免了传统关键点方法中“断线”的问题。
图2对比了几种关键点式车道检测方法。可以看到,PoseDriver(图d)的策略是并行的、全局的,一次前向传播就完成了所有点的检测和关联,效率很高。

把车道线“骨架化”,这个视角转换非常巧妙。但更大的挑战在于,如何让一个模型同时学好行人、动物、汽车、自行车和车道线这五门“功课”?这就是多任务学习的艺术了。
多任务协同:如何让一个模型学会“眼观六路”?
PoseDriver的框架建立在开源项目OpenPifPaf之上,这是一个优秀的自底向上姿态估计库。但直接拿它来做多类别检测,会碰到几个棘手的坎儿。论文作者针对性地做了三项核心改造:
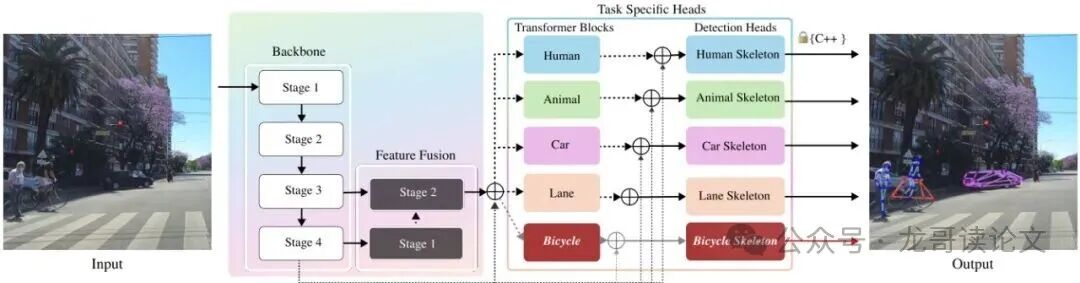
图3:我们的框架概述:网络旨在检测行人、动物、汽车、自行车和车道线的骨架。在骨干网络之后加入了特征融合阶段,并在特定任务前加入了Transformer模块。
1. 骨干网络“去BN化”
一个现实问题是:没有哪个现成数据集同时包含这五类目标的标注。PoseDriver必须使用多个来源不同、分布各异的数据库进行混合训练(见表1)。
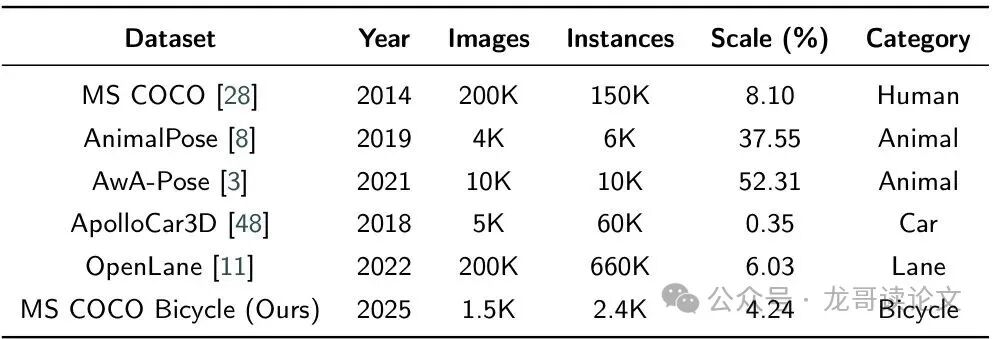
表1:实验中使用的数据集总结。尺度指标定义为每个样本的平均边界框面积除以其对应图像的面积。
这就带来了域偏移(Domain Shift) 问题。而传统的批归一化(Batch Normalization, BN) 层在训练时会统计每个批次的均值和方差,这个过程会“记住”数据分布特征。在多域数据混合训练时,BN反而可能加剧域间差异,损害性能。
因此,PoseDriver弃用了含有BN的骨干网络(如ResNet),转而选用ConvNeXt、Swin Transformer等原生不使用BN的现代架构,从根源上避免了这个问题。
2. 多尺度特征融合
再看表1的“Scale”列,动物平均占图面积可达52%,而汽车只有0.35%。目标尺度差异巨大!为了同时看清近处的行人和远处的小汽车,PoseDriver引入了特征金字塔网络(FPN),融合不同层级的特征,让模型兼具“望远镜”和“放大镜”的能力。同时,在数据增强时也采用了Mosaic增强,特意增加大尺度物体出现的概率,平衡数据分布。
3. 任务特定的Transformer“小脑袋”
虽然共享一个骨干网络提取通用特征,但行人关键点和车道线关键点的模式能一样吗?显然需要更专门的加工。PoseDriver在骨干网络输出的共享特征后,为每个任务类别都配备了一个轻量级的Swin Transformer模块 作为“任务特定头”。这个模块就像一个专属的注意力聚焦器,能根据各自类别的特点,从共享特征中提炼出最相关的信息,再送给后续的检测头。
最终的检测头采用OpenPifPaf的设计,输出两种场:
复合强度场(CIF): 负责预测关键点的位置热力图,回答“点在哪里”。
复合关联场(CAF): 负责预测关键点之间的连接向量场,回答“哪些点属于同一个物体/同一条车道”。
通过这套组合拳,PoseDriver成功地将五个差异巨大的感知任务,统一到了一个优雅的框架之下。
泛化能力实测:没见过自行车也能精准定位?
多任务学习的一个核心假设是:学习多个相关任务可以帮助模型学到更通用、更鲁棒的特征表示,从而对未知任务有更好的泛化能力。PoseDriver用自行车检测这个任务,漂亮地验证了这一点。
研究团队首先从MS COCO数据集中挑选了1557张包含自行车的图片,手工标注了6个关键点(前后轮的中心与边缘、车座、把手中心),构成了一个全新的自行车骨架数据集。
然后,他们设计了对比实验:
单任务模型: 只用新的自行车数据,从头开始训练一个模型。
多任务预训练+微调模型: 先用PoseDriver框架在行人、动物、汽车、车道线四个任务上做多任务预训练,让模型学到通用的“骨架感知”能力。然后,在这个预训练好的模型基础上,用自行车数据对自行车检测头进行微调。
结果如何呢?经过多任务预训练的模型,在自行车检测上的表现显著优于从头训练的单任务模型。 这意味着,从行人、汽车等任务中学到的“什么是关键点”、“如何连接它们”的通用知识,确实可以迁移到自行车这个新类别上,实现了“举一反三”。

这个实验不仅证明了框架的泛化能力,也为扩展更多类别(比如摩托车、交通标志杆)提供了一条可行的路径:先用丰富数据预训练一个通用的“骨架专家”,新类别只需要少量标注数据微调即可。
实验结果亮眼:多项任务达到最先进水平
纸上谈兵终觉浅,PoseDriver在多个任务上进行了全面测试,结果相当有说服力。
车道线检测:新SOTA的诞生
在权威的OpenLane数据集上,PoseDriver展现出了强大的竞争力。即使是参数量较小的ShuffleNetV2K16版本,其F1分数也达到了60.6%。而当使用更强的骨干网络时,性能实现了跨越式提升。
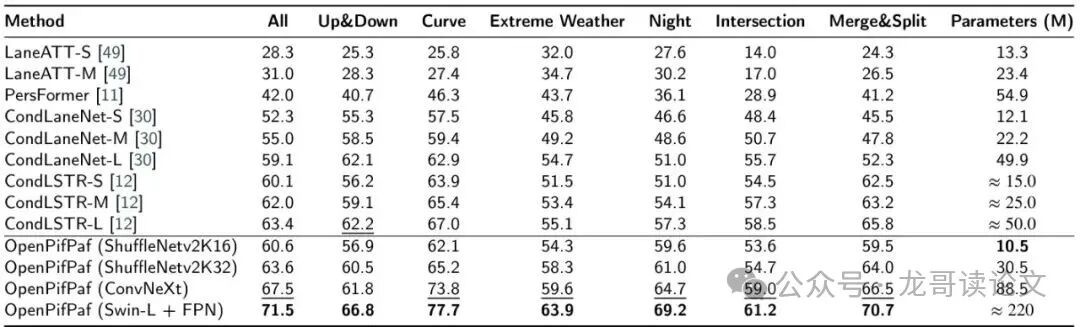
表2:OpenLane数据集上的结果。最佳结果加粗,次佳结果加下划线。
从表2可以看到,使用Swin-L+FPN骨干的PoseDriver,在总体F1分数上达到了71.5%,大幅超越了之前的最佳模型CondLSTR-L(63.4%)。更值得称道的是,在极端天气、夜间、弯道等极具挑战的子场景下,其优势更为明显。这证明了骨架表示法在复杂、遮挡情况下的鲁棒性。
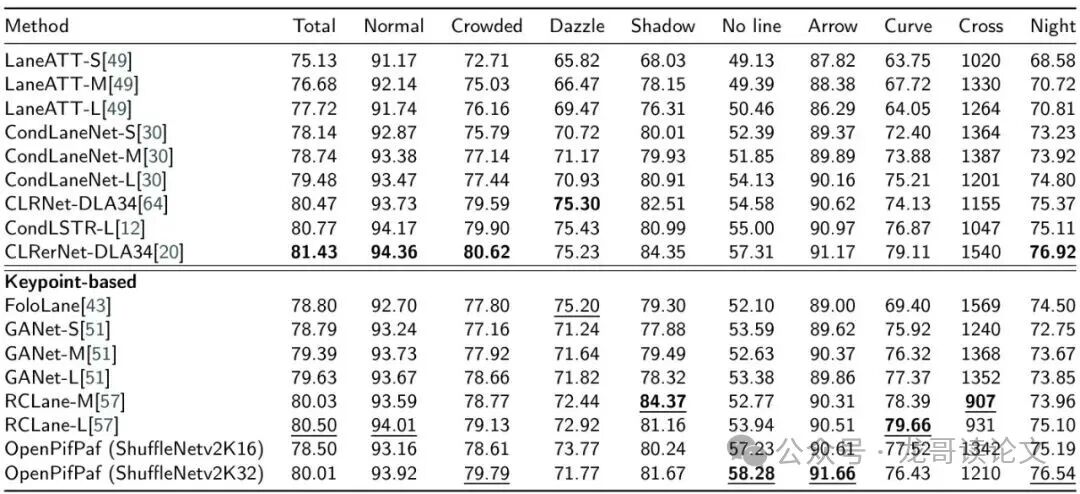
表3:CULane数据集上的定量结果(F1分数%)。最佳性能加粗,基于关键点方法的组内最佳性能加下划线。
在另一个主流车道数据集CULane上,PoseDriver也取得了80.01%的F1分数,与最先进的专用车道检测模型CLRerNet(81.43%)差距很小,并且在“拥挤”、“无线”、“夜间”等场景下表现优异。

图4:我们的方法(第4列)在CULane测试集上的定性结果,与CLRNet(第3列)对比。红色箭头指向我们方法明显预测得更好的部分。
多类别骨架检测:接近或超越单任务专家
对于行人、动物、汽车的骨架检测,PoseDriver在多任务设置下的表现如何?论文进行了详尽的消融实验(见表7)。核心结论是:在大多数情况下,经过精心设计的多任务模型,其性能与单独训练的单任务模型持平,甚至在动物和汽车检测上略有超越。 唯一的例外是行人检测,多任务模型相比单任务专家有轻微的精度下降,这可能是由于行人姿态的复杂性和其他类别数据带来的干扰所致。但考虑到一个模型同时处理了五大任务,这个代价是可以接受的。
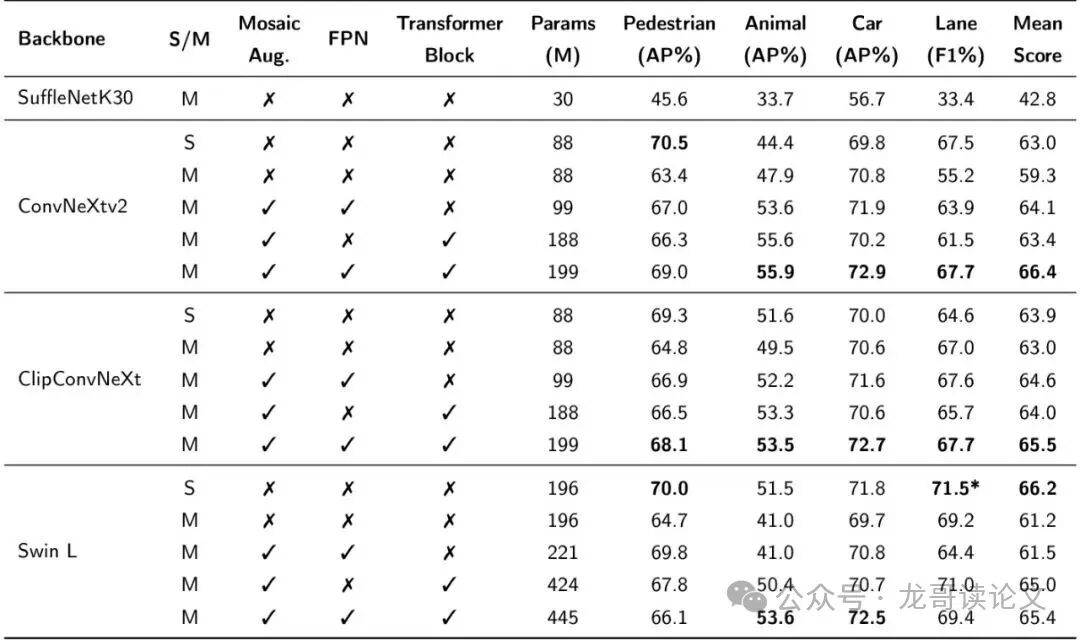
表7:单任务(S)和多任务(M)设置下骨干架构的性能对比。此表总结了Mosaic增强、FPN和Transformer模块对模型性能的影响。
最后,让我们通过一些可视化结果,直观感受一下PoseDriver“眼观六路”的能力:

图6:在OpenDV数据集(前两张图)和MS COCO验证集(后两张图)上的实验结果。如图所示,我们的模型成功检测了真实场景中的行人(蓝色)、动物(绿色)、汽车(紫色)、自行车(红色)和车道线(橙色)。
图中的彩色线条和点,就是PoseDriver为我们勾勒出的、一个结构化、可理解的自动驾驶世界。这项研究为构建更智能、更通用的自动驾驶感知系统提供了全新的思路和技术路径,其将计算机视觉中的关键点检测思想创造性扩展至复杂驾驶场景,颇具启发性。想了解更多前沿技术解析,可以关注像云栈社区这样的开发者平台,获取更多深度内容。
主要参考文献
[1] 原论文:PoseDriver: A Unified Approach to Multi-Category Skeleton Detection for Autonomous Driving. https://arxiv.org/pdf/2603.23215v2.pdf
[2] OpenPifPaf: Composite Fields for Semantic Keypoint Detection and Spatio-Temporal Association. https://github.com/openpifpaf/openpifpaf
[3] 文中使用的数据集:MS COCO, AnimalPose, AwA-Pose, ApolloCar3D, OpenLane, CULane.
 发表于 2026-3-31 04:02:02
|
查看: 133|
回复: 0
发表于 2026-3-31 04:02:02
|
查看: 133|
回复: 0
