想象一下未来的AR眼镜,它不仅仅是在你眼前叠加一个虚拟图像,而是能让这个图像像真实物体一样,拥有光影、景深,甚至当你转头时,光影也随之自然变化。这背后需要的,是一种能精准模拟光的所有物理特性的技术——全息显示。
但现有的方法有个大麻烦:你每动一下,视角一变,整个计算就得推倒重来。 这就像拍电影,每个镜头都要重新布景、打光,效率低得令人发指,更别提实时交互了。
最近,来自伦敦大学学院(UCL)和浦项科技大学(POSTECH)的研究团队搞了个大事情。他们给当下最火的3D高斯泼溅(3D Gaussian Splatting,简称3DGS) 技术做了个“大手术”,让它从只能处理光强,进化到能同时处理光的振幅和相位。这个新方法叫复数值全息辐射场。
最牛的是,它直接让3D场景“记住”了自己该发出的光波是什么样的,从此告别逐帧重算。论文声称渲染速度提升了30到10000倍!这意味着,高质量的全息渲染,离实时应用又近了一大步。
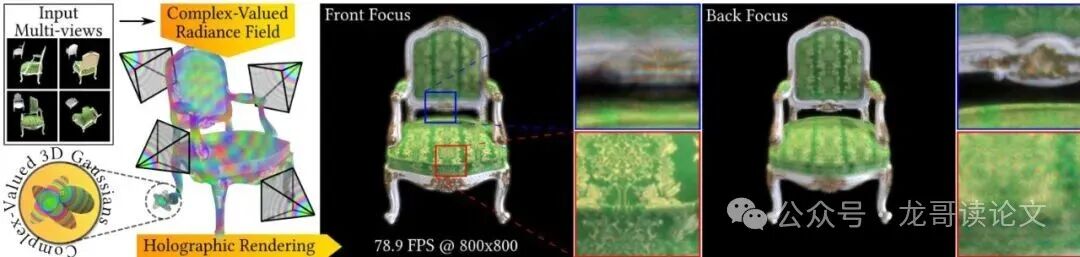
图1:复数值全息辐射场。本方法明确将复数值全息辐射场作为主要优化目标,联合优化多视角下的3D场景,以在场景表示中建模光的强度、干涉和衍射。复数值3D高斯将被投影到多个深度平面,通过全息渲染产生复杂的3D全息图。这使得重建的全息图具有景深效果:蓝色框突出显示后聚焦区域,红色框显示前聚焦区域。
全息显示新挑战:如何让3D场景“自带”光影波?
要理解这篇论文的价值,得先明白传统全息显示(CGH,Computer-Generated Holography)的痛点。
我们日常看到的图像,记录的是光的强度(Intensity),也就是“有多亮”。但光是电磁波,它还有相位(Phase) 这个属性。你可以把光波想象成水面上的波纹,强度对应波峰的高度,而相位则决定了波峰和波谷的具体位置。
为什么相位这么重要?因为当两束光相遇时,它们会干涉。如果两束波的波峰对齐(相位相同),就会相长干涉,变得更亮;如果一个波峰遇到一个波谷(相位相反),就会相消干涉,变暗甚至消失。电影里激光剑碰撞的火花、CD光盘上的彩虹色,都是干涉和衍射(光波遇到障碍物弯曲传播)的结果。
传统的计算机生成全息图(CGH),目标就是计算出一个包含振幅和相位信息的复数值(Complex-valued) 图案(全息图),当用激光照射这个图案时,就能重建出拥有逼真光影和深度的3D场景。
但是!绝大多数现有的CGH方法,包括一些基于学习的先进方法,都遵循一种叫欧拉(Eulerian) 的范式。简单说,就是它们针对一个固定的观察视角,去计算一个固定的全息图平面。一旦你的脑袋(观察视角)动了,全息图平面和3D场景之间的几何关系就变了,原来计算好的全息图就“失效”了,你看到的东西会变成一堆毫无意义的噪声。
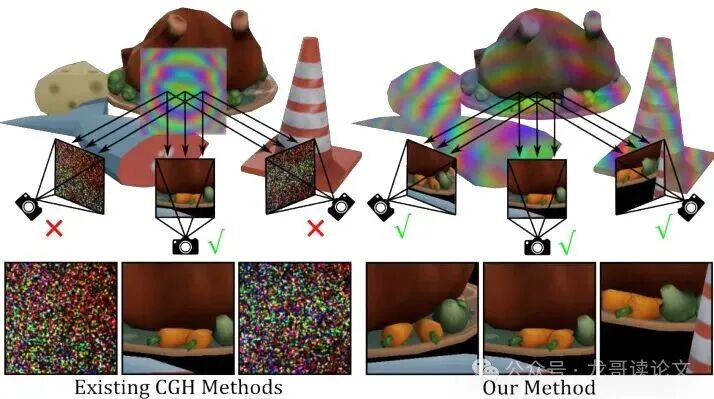
图2:左:现有CGH方法在视角变化下无法保持场景的几何一致性,需要对每个视角进行变换或重新计算。右:相比之下,我们的复数值全息辐射场提供了3D一致的表示。
这就是为什么过去的方法要么只能看一个固定角度,要么每次动一下,就需要极其昂贵地重新计算整个全息图。想象一下在VR里转头,画面要卡顿几十秒才能刷新,这体验直接把人送走。
核心问题在于:传统的全息图没有和3D场景的几何结构绑定。它只是一个2D的“魔法图案”,只对特定的观察角度有效。
告别逐帧重算!复数值高斯让全息图“活”起来
这篇论文的思路堪称“釜底抽薪”:我们不直接去算那个2D的全息图,而是去学一个3D场景本身该如何发光(发波)。
他们借用了当下神经渲染领域的“当红炸子鸡”——3D高斯泼溅。简单说,3DGS用一个个可学习的、有形状(椭圆球)、有颜色、有透明度的小斑点(高斯)的集合来表示一个3D场景。渲染时,把这些3D斑点投影到2D屏幕上,按前后顺序混合,就能得到一张新视角的图片。它速度快、质量高,而且几何是明确的。
但3DGS有个根本局限:它的小斑点只记录RGB颜色(光强)。对全息显示来说,这就像只有歌词没有曲谱,完全没法还原光的波动交响乐。
UCL和POSTECH团队的关键创新在于:给每个3D高斯斑点加上“相位”属性,让它从一个纯实数(Real-valued)的物体,变成一个复数值(Complex-valued)的“波源”。
现在,每个高斯斑点不仅知道“我有多亮”(振幅,由原先的颜色参数转换而来),还知道“我的光波在什么位置”(相位,一个新学的参数)。当这些波源发出的光波在空间中传播、相遇,自然就会产生干涉和衍射。
更重要的是,这些属性是绑定在3D几何上的。无论你从哪个角度看这个3D场景,每个高斯斑点都知道自己相对于观察者应该发出什么样的光波。这样,为任何新视角计算全息图,就变成了一个简单的“渲染”过程,而不是“重新计算”过程。这被称为拉格朗日(Lagrangian) 范式,与传统的欧拉范式形成鲜明对比。

原理拆解:振幅相位如何嵌入3D高斯?
下面我们深入“车间”,看看这个想法是怎么落地的。整个流程的精髓都在这张图里:

图3:无需查询基于强度的辐射场,我们的方法使用具有固有振幅和相位属性的高斯图元对复数值全息辐射场进行建模,实现了跨视角的场景几何感知振幅与相位建模,并通过可微分的多层传播管线实现高效渲染。
第一步:定义“波源”——复数值3D高斯
普通的3D高斯参数是 (位置,旋转,缩放,颜色,不透明度)。现在,颜色 c_n 被重新解释为振幅(Amplitude),即光波的强度根源。然后新增两个关键参数:
相位 φ_n:一个三维向量,代表这个高斯在不同波长(通常是RGB)下的固有相位值。它决定了这个波源发出的光波的“起跑线”。
平面分配概率 ρ_n:一个L维向量(L是设定的深度平面数)。这解决了“一个3D物体发出的光波,该贡献到哪个深度平面去计算”的问题。论文用了一个巧妙的直通估计器(Straight-Through Estimator, STE) 来让这个离散的分配过程可微分,从而能通过梯度下降学习。
第二步:分层投影与波前记录
给定一个新视角,我们不是直接算全息图,而是设置一系列平行于成像平面的虚拟深度平面。
- 投影:将所有复数值3D高斯根据其分配的深度平面,投影到对应的2D平面上。投影后的2D高斯贡献一个复数值:*U_n = 振幅 2D高斯形状 e^(j 相位)**。这里的 j 是虚数单位。
- 混合:在每个深度平面内,按照传统3DGS从前到后的顺序,但混合的是复数值!公式如下(对第l个平面):
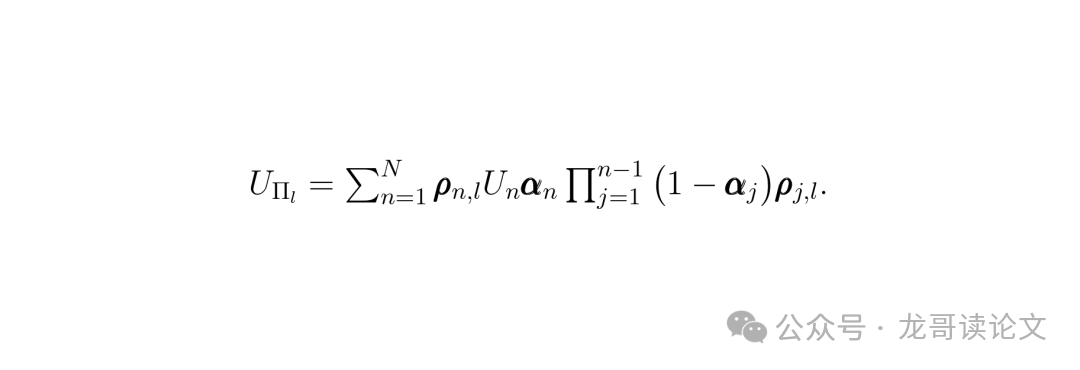
这个公式确保了只有被分配到当前平面的高斯才会参与该平面的复数值混合,并且不透明度 α 控制了波前的衰减,实现了光学遮挡的物理模拟。
- 传播(Forward Recording):得到了每个深度平面的复数值光场 U_Πl 后,使用带限角谱法(Band-Limited Angular Spectrum Method, ASM),将每个平面的光波传播到最终的全息图平面P上,并相干叠加。这一步模拟了光从不同深度传播到成像面的物理过程。
第三步:逆向传播与监督
生成了全息图P,但这并不是最终图像。全息图需要被“解码”才能被人眼看到。论文通过逆向传播(Inverse Propagation),将全息图P的光波重新传播回各个深度平面,然后计算其强度(模的平方),得到一系列聚焦在不同深度上的图像 I_l。
训练时,就用这些重建的强度图 I_l,与多视角采集的、已知的真实焦点堆栈(Focal Stack)图像 I_gt,l 进行比较,计算损失(结合了MSE和SSIM损失)。整个过程是完全可微分的,因此可以通过梯度下降反向传播,优化所有3D高斯的参数(位置、形状、振幅、相位、分配概率等)。
妙处在于:虽然我们从未直接提供“这个高斯相位应该是多少”的监督信号,但为了能准确地重建出所有视角下、所有焦点平面上的强度图像,模型不得不学会一套自洽的、与几何绑定的振幅和相位表示。这就是“复数值全息辐射场”的含义。
速度与质量的博弈:实验结果深度分析
光说不练假把式,论文在多个标准数据集(NeRF Synthetic, LLFF, Mip-NeRF 360)上进行了详尽的测试,主要对比了两个基于高斯的最新全息方法:3DGS+U-Net [Chen et al. 2025] 和 GWS (Gaussian Wave Splatting) [Choi et al. 2025]。
核心优势对比: 下表清晰地展示了本方法的全面性优势:

表1:基于高斯图元的全息图合成方法对比。Inference指推理速度。Re指当场景与观察者之间的几何关系变化时是否需要重新计算。Type指高斯表示类型。Quality指从全息图重建的图像质量。Align指跨新视角的场景几何感知振幅和相位表示。NDB指自然的散景模糊。
可以看到,本方法是唯一一个在“无需重算(Re: No)”、“表示与几何对齐(Align: Yes)”和“自然散景(NDB: Yes)”这三项都打勾的方法。3DGS+U-Net和GWS都因为其欧拉范式,需要为每个新视角重新计算或进行网络推理。
视觉效果对比: 下图展示了在乐高(Lego)场景中,从不同视角观察的效果。我们的方法(顶行)在不同旋转角度下都能保持一致的几何和外观。而基线方法(中间行)在视角变化后,全息图没有更新,导致重建出的图像完全失真,变成了无意义的噪声。这直观验证了“无需重算”的几何一致性表示的巨大优势。

图4:模拟中不同全息图合成方法在不同视角下的比较。顶行显示了我们的方法在大角度从左到右旋转的新视角下具有场景几何感知的表示。中间行显示了依赖基于强度中间表示的现有CGH方法,它们无法在新视角下保持一致性。底行显示了真实的强度图像。
图像质量与推理速度: 下表定量比较了图像质量(PSNR/SSIM/LPIPS)。在“无需重算”的公平对比下(比较各方法的“Vary”列),本方法在大多数场景和指标上优于或与3DGS+U-Net (Vary)持平。最重要的是推理速度:
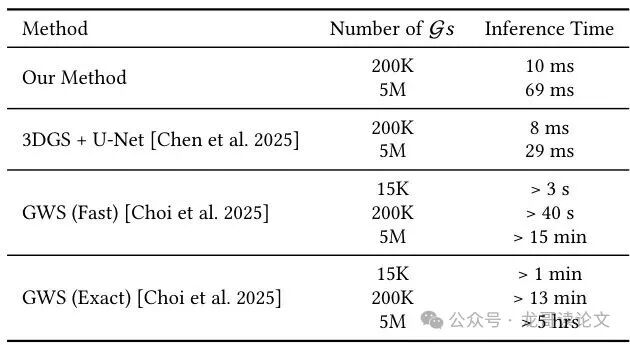
表3:不同基于高斯图元的全息图合成方法在800x800分辨率下的推理时间对比。3DGS+U-Net的推理时间包括每个查询视角的重新计算,由3DGS渲染和网络推理组成。
本方法单次推理仅需10毫秒,而3DGS+U-Net耗时略快,为8毫秒,GWS则很慢,为3秒以上。在更复杂的场景或更高分辨率下,由于避免了基于点数平方级增长的计算,加速比甚至可达10000倍。下图展示了渲染时间和内存随分辨率、高斯数量、深度平面数的变化,显示了良好的可扩展性。

图5:性能和内存使用分析。(a) 在1个平面下,不同高斯数量对应的渲染时间与分辨率的关系。(b) 内存使用和渲染时间与深度平面数的关系。(c) 内存使用和渲染时间与高斯数量的关系。(d) 不同高斯数量下内存使用与分辨率的关系。
物理效果验证:自然的散景模糊。由于本方法本质上是模拟波传播,它天生就能产生物理正确的散景(景深)效果。如下图所示,在聚焦到前景(Front Focus)时,背景(Back Focus)会自然地模糊;反之亦然。而3DGS+U-Net方法生成的散景则显得不够自然。
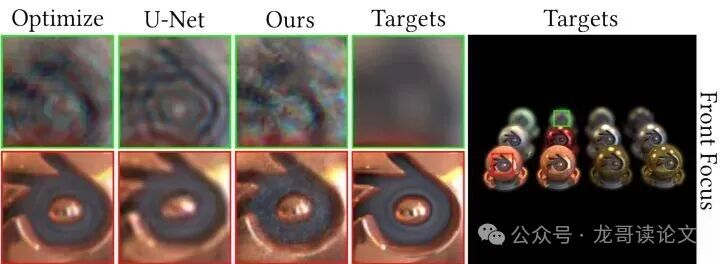
图7:全息重建中散景模糊的对比,比较了优化方法、3DGS+U-Net和我们的方法与目标图像。

未来已来?全息渲染的机遇与挑战
这篇论文无疑为实时、高质量的全息显示打开了一扇新的大门。它将物理光学模型与高效的神经场景表示相结合,提供了一个兼具物理准确性、3D一致性和高速度的解决方案。
可以预见,这项技术将对下一代增强现实(AR)、虚拟现实(VR)头显、全息通话、车载平视显示器(HUD)以及科学可视化等领域产生深远影响。当显示设备不仅能控制光强,还能精确控制相位时,我们离《钢铁侠》里贾维斯那种悬浮在空中的、拥有真实体感的全息交互界面就更近了一步。
当然,前路仍有挑战。论文也提到,目前的模型在应对极端运动视差(Motion Parallax) 的场景时,相位可能会产生不连续,影响重建质量。此外,如何将更多的波光学现象(如偏振、光谱)也整合进这个框架,也是一个值得探索的方向。
核心问题解答
下面是对于大家可能的一些问题的解答:
全息显示和普通的3D显示(如VR)有什么区别?
普通3D显示(如VR眼镜)是通过给左右眼显示有视差的图像,欺骗大脑产生立体感。但它无法提供真实的聚焦深度(Vergence-Accommodation Conflict) 线索,看久了容易晕。全息显示则通过重建真实的光波前,让你的眼睛的晶状体需要像看真实物体一样进行对焦,提供了所有物理正确的深度线索,视觉更舒适、更逼真。
“复数值”高斯比传统3DGS具体强在哪?
传统3DGS的高斯是实数值的,只记录颜色(强度),无法模拟光的干涉和衍射。复数值高斯则同时记录振幅和相位。这使得它不仅能表示“这个点有多亮”,还能表示“这个点发出的光波处于什么周期位置”。当多个这样的波源发出的光波在空间叠加时,就能自动产生物理正确的干涉图案(如高光闪烁、阴影边缘的衍射)和自然的景深模糊效果。
这个方法现在能用在手机上吗?
目前还不行,但方向很乐观。论文中的方法推理(渲染)速度极快(毫秒级),这是实时应用的前提。主要瓶颈可能在于训练阶段,需要从多视角图像中优化出这个复数值辐射场,这需要一定的算力。未来,通过模型压缩、专用硬件(如NPU)加速,以及可能的预训练模型下载,在移动设备上运行是很有希望的。现在的价值更多在于为下一代AR/VR硬件提供了关键的软件算法基础。
论文信息
主要参考文献
[1] Yicheng Zhan, Dong-Ha Shin, Seung-Hwan Baek, and Kaan Akşit. 2024. Complex-Valued Holographic Radiance Fields. ACM Trans. Graph. 43, 4, Article 1 (July 2024). (原论文)
[2] 项目主页与开源代码: https://github.com/complight/Complex_Valued_Holographic_Radiance_Fields
[3] Kerbl et al. 2023. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Trans. Graph. (3DGS 原始论文)
[4] Choi et al. 2025. Gaussian Wave Splatting for Real-Time Coherent Holography. CVPR 2025. (对比基线 GWS)
本文基于学术论文进行解读,仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。更多前沿技术动态与深度解析,欢迎访问 云栈社区 的开发者广场参与交流。
 发表于 2026-3-31 03:58:14
|
查看: 182|
回复: 0
发表于 2026-3-31 03:58:14
|
查看: 182|
回复: 0
