线上告警在凌晨三点响了。
监控大盘显示,Redis集群的内存使用率突破了85%,触发了告警阈值。你从睡梦中被叫醒,打开电脑,第一反应是:业务量暴增了?但流量监控显示一切正常,QPS跟昨天差不多。
翻了翻监控曲线,内存是从三周前开始缓慢爬坡的。团队在两个月前做了一次大版本迭代,缓存的数据结构从简单的字符串换成了哈希表,方便存储用户属性。从那之后,内存就开始慢慢涨。
你连上Redis,执行 INFO memory,看到一个让人头皮发麻的数字:mem_fragmentation_ratio是2.3。
这意味着什么?操作系统分配给Redis的物理内存,是Redis自己记录的已使用内存的2.3倍。换句话说,将近一半的物理内存被碎片吃掉了,实际存数据的只有一多半。
这是一个很典型的场景。内存问题往往不是突发的,而是在数据结构选择、编码方式、分配器行为这些细节上慢慢积累出来的。在十万QPS的时候,这些问题不明显;到了百万QPS,开始影响成本;到了千万QPS,内存效率直接决定了集群能不能撑得住。
内存消耗从哪里来
要优化内存,先要搞清楚内存都花在了哪里。这个问题比大多数人想象的复杂。
Redis的内存消耗,可以粗略分成四个部分:
- 一是数据本身。 你存的key和value,这是必要的消耗。但“数据本身”的开销远比你以为的大,因为Redis不是裸存字节,每个对象都带着元数据。
- 二是数据结构的额外开销。 一个Redis的hash对象,底层可能是listpack(紧凑编码),也可能是hashtable(散列表)。同样的数据,用hashtable存储的内存开销可能是listpack的3~5倍。
- 三是内存分配器的碎片。 Redis向操作系统申请内存,不是用多少申请多少,而是通过内存分配器(jemalloc、tcmalloc等)来管理。分配器为了效率,会按固定的大小类(size class)分配内存,导致实际分配的内存总是大于请求的内存。频繁的内存分配和释放,会产生碎片。
- 四是操作系统层面的预留。 操作系统为进程维护内存映射、页表等结构,也会占用一部分物理内存。
四层内存消耗构成了Redis的实际物理内存占用,从数据层到分配器层逐级放大。
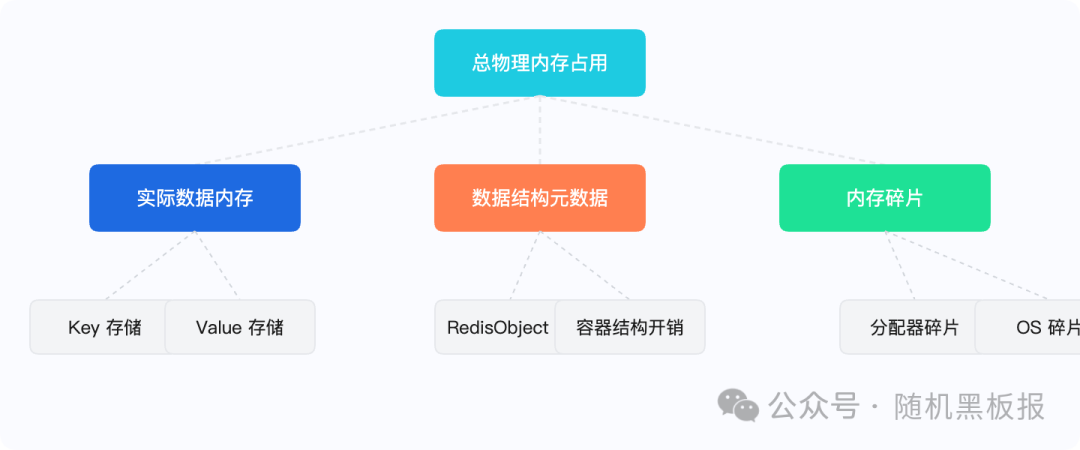
Redis 内存构成:总物理内存由数据内存、元数据开销、碎片三部分叠加
理解这四层之后,内存优化的思路就清晰了:从数据结构编码入手,压缩每个对象的存储大小;通过分配器选择和碎片整理,降低碎片率;通过过期和淘汰策略,控制总量。
紧凑编码:被低估的内存利器
先聊最容易被忽略、但效果最显著的一个优化点:数据结构的编码方式。
Redis的聪明之处在于,同一种逻辑数据结构,在数据量小的时候用紧凑编码,在数据量大的时候自动转换成高效编码。这个机制叫做“编码自适应”。
以hash为例。当一个hash的字段数量少于某个阈值(默认128),且每个字段的值大小小于某个阈值(默认64字节)时,Redis用listpack存储它。listpack是一种紧凑的线性内存结构,所有字段挨着存,没有指针,没有散列桶,内存效率极高。
一旦超过阈值,Redis自动把listpack转成hashtable。hashtable的查找是O(1),但每个节点都要维护哈希链表指针,内存开销大幅增加。
来看一个具体的对比:

这个 4~5 倍的内存差距,不是靠优化代码得来的,而是靠数据建模的方式决定的。
同样的逻辑,适用于list(listpack vs quicklist)、set(intset/listpack vs hashtable)、zset(listpack vs skiplist+hashtable)。
各数据结构的编码转换都有明确的触发条件,触发后无法自动回退,因此数据模型设计阶段就要考虑到。
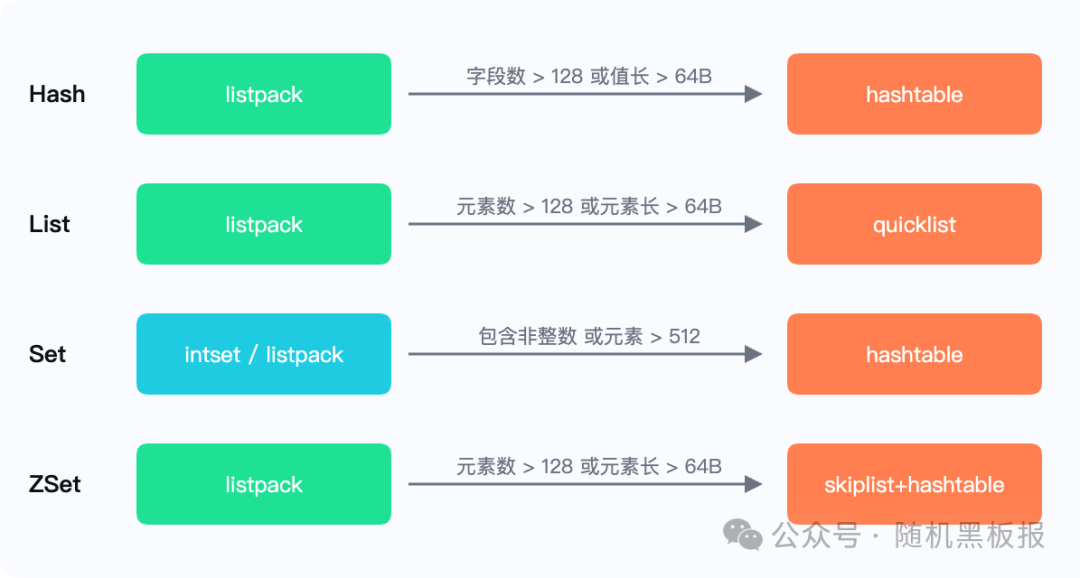
各数据结构的编码转换时机,触发后不可自动回退
真实的工程陷阱
理解了编码机制之后,回头看那个凌晨告警的案例,问题就很清楚了:业务把用户属性从字符串迁移到hash,但没有考虑每个用户的属性数量。有些活跃用户积累了大量属性,字段数超过128,触发了listpack到hashtable的转换。几百万个用户,每个hash多了4~5倍的内存,总量就爆了。
解法其实不复杂,有两个方向:
- 方向一:控制单个hash的字段数。 如果业务允许,把用户属性按类别拆分成多个hash(基础属性、扩展属性、行为属性),保证每个hash的字段数在阈值以内。
- 方向二:合理调整阈值。 如果你的value都是短字符串,可以适当放大字段数阈值,让更多hash保持listpack编码。反过来,如果你的value本身就比较大,超过64字节,可以缩小这个阈值,避免在listpack里存储过大的元素(listpack的遍历是O(N),元素太多或太大会影响查询性能)。
编码阈值的调整是一个trade-off:更大的阈值换来更低的内存,代价是更高的查询复杂度。具体怎么取舍,取决于你的读写比例和对延迟的容忍度。
intset:被遗忘的内存神器
还有一个很容易被忽略的编码:intset。
当你的set集合里存的全是整数时,Redis会用intset来存储。intset是一个有序的整数数组,内存极度紧凑。存储512个64位整数,intset只需要4KB左右;如果换成hashtable,同样的数据需要20KB以上。
这个特性在存储用户ID集合、商品ID集合等场景下非常实用。前提是:集合里不能混入非整数成员。一旦插入了字符串,intset立刻降级为hashtable,内存暴涨,且无法自动恢复。
内存分配器:选择比努力更重要
讲完了数据结构层面的优化,来聊一个更底层的问题:内存分配器。
这个话题听起来很学术,但在大规模Redis集群里,分配器的选择对内存碎片率有直接影响,影响幅度在10%~40%之间,不可忽视。
为什么会有碎片
内存碎片的本质,是内存分配和释放的时序不匹配。
Redis在运行过程中,不断地申请内存(写入新key)和释放内存(过期key被删除、key被覆盖)。问题是,被释放的内存块,和下一次申请的内存块,大小不一定匹配。分配器只好把小的空闲块留着,用更大的空间来满足新的申请。久而久之,内存里充满了大量细碎的“孔洞”,这就是碎片。
碎片的形成是一个渐进过程:初始连续内存在分配和释放的交替中逐渐产生“空洞”,最终导致实际可用内存远小于物理内存。
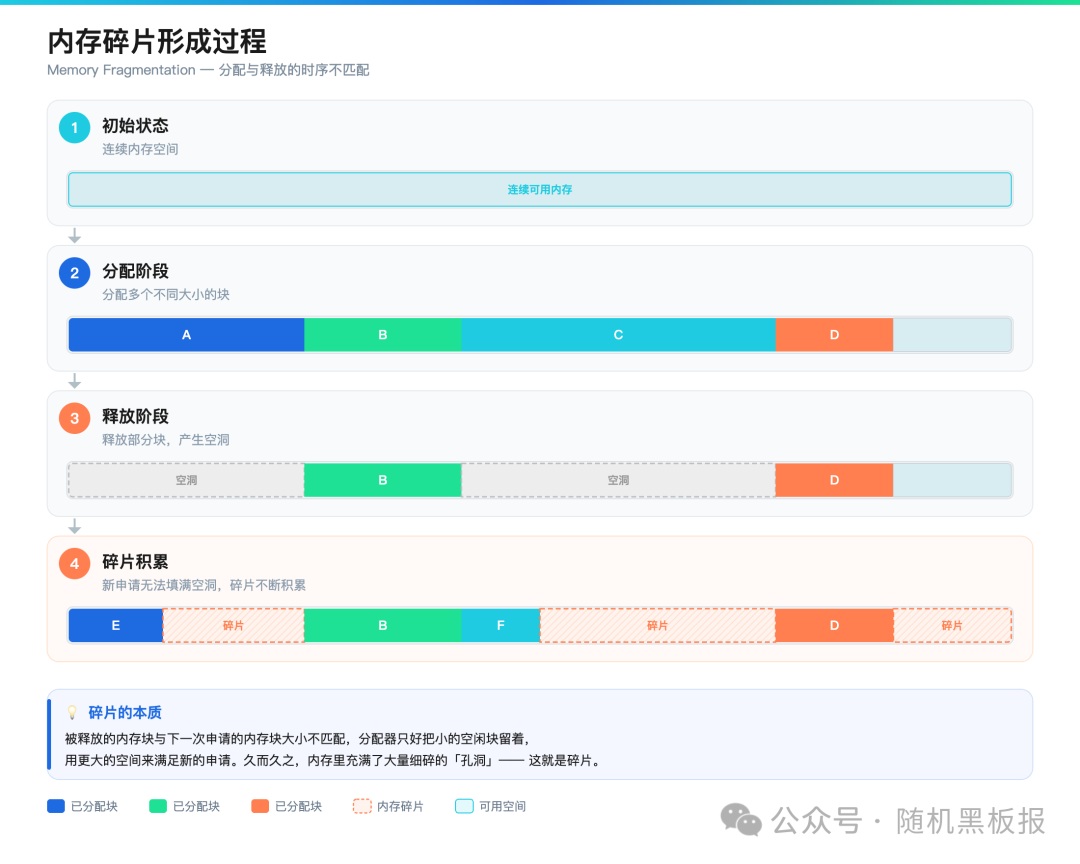
内存碎片形成过程:连续分配和碎片化释放,导致空洞积累
碎片的严重程度,很大程度上取决于内存分配器的设计哲学。
jemalloc vs tcmalloc vs glibc malloc
Redis默认使用jemalloc。这个选择是经过深思熟虑的。
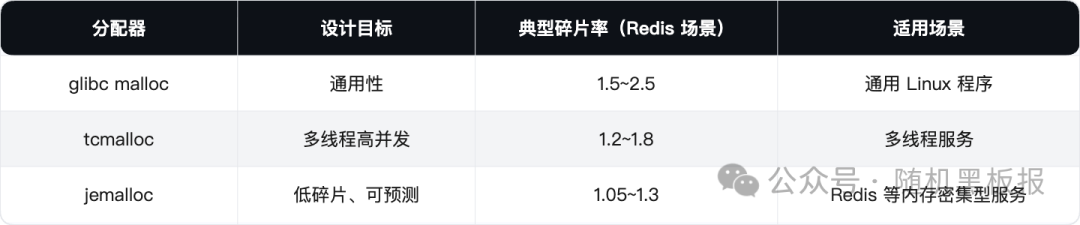
- glibc malloc 是Linux系统自带的内存分配器,通用性最强,但为Redis这种大量小对象、高频分配释放的场景优化不足,碎片率通常偏高。在Redis的测试中,glibc malloc的碎片率经常在1.5以上。
- tcmalloc 是Google开发的内存分配器,per-thread缓存的设计让多线程场景下的分配非常快。但Redis本质上是单线程(I/O事件循环),per-thread cache对它帮助不大,反而增加了内存的预留开销。
- jemalloc 是Facebook开发、现在广泛应用的内存分配器,设计目标就是低碎片率和可预测的性能。它把内存按大小分成不同的size class,每个size class有独立的arena(内存池),显著减少了不同大小对象之间的干扰。在Redis的实测场景中,jemalloc的碎片率通常在1.05~1.3之间,表现最好。
jemalloc 对Redis的另一个贡献是:它暴露了丰富的统计接口,Redis的 MEMORY USAGE、mem_fragmentation_ratio 这些指标,很大程度上依赖jemalloc提供的底层数据。
碎片治理:主动整理
即便用了jemalloc,碎片还是会随着时间积累,特别是在以下几种场景:
- 大量key集中过期(比如促销结束后缓存失效)
- 频繁覆盖写(value大小变化导致重新分配)
- 数据规模的潮汐变化(白天写满,夜间清空)
Redis 4.0引入了主动碎片整理(Active Defragmentation)机制。它的工作原理是:在后台,逐步把碎片化严重的内存块中的数据,复制到新的连续内存中,然后释放旧的碎片块。这个过程是渐进式的,对正常读写请求的影响被控制在可接受范围内。
主动碎片整理是一种“以CPU换内存”的策略,在碎片率高于1.5时,开启后通常能在几小时内把碎片率降到1.1以内。
但这里有一个重要的trade-off:主动整理会消耗CPU,在高QPS场景下,需要仔细评估CPU余量,避免整理任务和业务请求争抢资源。通常的建议是,把整理的CPU占用比例控制在25%以内,并监控整理过程中P99延迟的变化。
另一种更粗暴但有时更实用的方式是:在低峰期,对实例执行计划性重启或迁移,彻底清空碎片。这适合碎片率极高(超过2.0)且整理效果不理想的情况。
过期策略与淘汰策略:内存的“出口管理”
数据进来了,如何把不需要的数据及时清理出去,同样是内存管理的关键。Redis提供了两套机制:过期策略(Expiration)和淘汰策略(Eviction)。
这两个机制经常被混为一谈,但实际上它们解决的是不同问题:
- 过期策略 处理的是“到期了该删的数据”,是有明确TTL的key的生命周期管理。
- 淘汰策略 处理的是“内存不够用时该删哪些数据”,是内存超限时的主动选择。
过期策略:懒删除的两面性
Redis的过期删除,是“懒删除”和“定期删除”结合的策略。
- 懒删除:key过期后,不立即删除,等到下次访问这个key时,才检查是否过期并删除。
- 定期删除:Redis每隔一段时间(默认每秒10次),随机抽样一批设置了TTL的key,删除其中已过期的。
懒删除保证了Redis的性能,但代价是过期key可能在内存中“赖着不走”,在高QPS场景下这个问题尤为突出。
来看一个典型问题:假设你有1000万个key,其中30%在某个时间点同时过期(比如你设置了统一的TTL)。Redis的定期删除每次只抽样20个key,按照概率,完整清理这300万个过期key需要相当长的时间。在这段时间里,这些key一直占据着内存。
解决思路:
- 一是错开过期时间。 给key的TTL加上随机抖动(比如基础TTL加减20%的随机值),避免大量key同时到期,让定期删除能够均匀地持续清理。
- 二是关注定期删除的效率。 Redis的定期删除频率可以适当调高,但这会增加CPU开销,需要根据实际情况权衡。
淘汰策略:内存压力下的选择
当Redis的内存达到上限(maxmemory),就需要主动淘汰key。Redis提供了多种淘汰策略,选哪个,直接影响缓存命中率和内存利用率。
不同规模下,淘汰策略的选择逻辑有所不同。
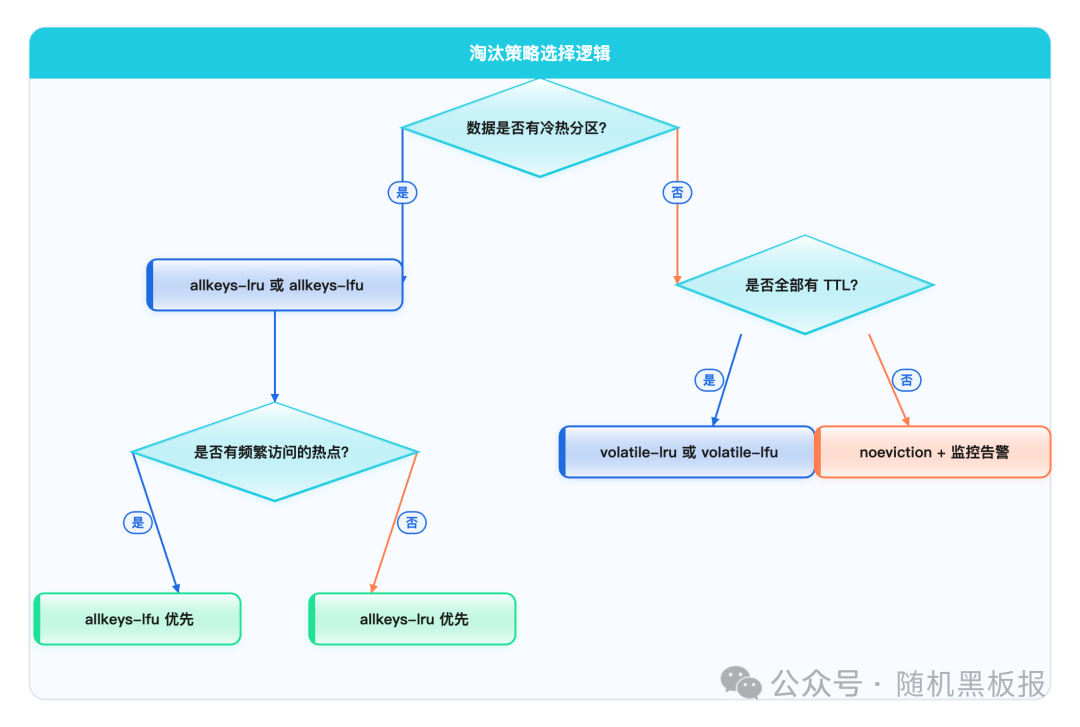
淘汰策略选择决策树:根据数据冷热分布和TTL情况选择合适策略
- allkeys-lru是最常见的选择,适合大多数有冷热分区的缓存场景。它会优先淘汰最久未被访问的key,符合“最近用到的数据更可能再被用到”的直觉。
- allkeys-lfu(Least Frequently Used)在Redis 4.0引入。它不看“最近用没用”,而是看“用的频率高不高”。对于有长期热点的场景(比如某些商品永远是爆款),LFU比LRU更智能,能避免热点数据被偶尔的批量操作“冲走”。
从十万QPS到千万QPS,淘汰策略的选择本身变化不大,但淘汰触发的频率和代价会显著增加。在千万QPS场景下,如果内存管理不当导致频繁淘汰,每次淘汰操作都会在关键路径上引入额外的延迟,这个影响是不可忽视的。
核心建议是:把maxmemory设置留出足够的安全水位(通常是物理内存的75%~80%),让Redis在淘汰触发之前,通过过期清理和主动整理就能维持健康的内存水位。频繁触发淘汰,往往说明内存容量规划出了问题,而不仅仅是策略选择的问题。
从十万到千万:内存优化的演进路线
内存优化不是一次性的事,它随着系统规模的增长,重心会不断转移。
十万QPS阶段:能跑就行
在这个阶段,Redis通常是单实例或小规模集群,内存容量相对充裕。
内存优化的重点是:选对数据结构,不要犯明显的错误。比如,不要把本来应该用hash存的数据,用多个独立key来存(每个key都有RedisObject的元数据开销);不要存过大的value(几MB的大value对Redis的性能影响是全方位的)。
这个阶段,大多数团队用默认配置就够了。jemalloc默认开启,listpack阈值也是合理的起点。
百万QPS阶段:开始精细化
进入百万QPS阶段,内存效率开始影响成本。单节点内存已经不够用,需要分片集群。这时候内存优化的重心转移到两个方向:
- 一是对数据建模做精细审查。 系统里出现了大量的hash、list、zset,每个数据结构的编码状态是什么?有没有本来应该用listpack但因为设计不当触发了转换的?这个阶段值得花时间做一次系统性的
OBJECT ENCODING 审查。
- 二是开始关注碎片率。 百万QPS意味着更高的写入频率,碎片累积速度更快。需要把碎片率纳入日常监控,并制定碎片率超阈值的处理预案。
从十万到百万,内存效率提升带来的收益,往往体现在集群节点数的减少上,这直接影响运维成本和故障域的大小。

内存优化策略随规模演进:从基础建模到集群级治理
千万QPS阶段:系统性工程
到了千万QPS,内存优化变成了一个系统性工程,有几个百万QPS阶段没有的挑战:
- 挑战一:集群规模带来的管理复杂性。 千万QPS的Redis集群,通常需要数百个节点。你不可能逐个节点去检查编码状态和碎片率,需要一套自动化的内存分析和治理系统,能够定期扫描、汇总、告警,并自动触发碎片整理。
- 挑战二:内存水位的潮汐管理。 大规模系统的流量往往有明显的潮汐特征。白天高峰期内存接近上限,夜间低谷期内存可能只用了一半。如果按高峰期配置内存,夜间的资源大量浪费;如果按平均水位配置,高峰期会触发淘汰。千万QPS场景下,需要考虑动态扩缩容(弹性集群),让内存容量跟着流量走,而不是静态预留。
- 挑战三:大规模key的过期积压。 千万QPS场景下,key的数量通常在亿级别。如果TTL设计不合理,定期删除跟不上过期速度,内存会持续增长。需要在系统设计层面,对key的TTL分布做精细规划,并配合监控来验证过期清理的效果。
千万QPS和百万QPS在内存管理上的本质差距,不在于单个实例的优化技巧,而在于集群级别的内存治理能力。
大规模集群下的内存挑战
大规模Redis集群的内存管理,有一些在小规模下不会遇到的特有问题,值得单独讨论。
数据倾斜
在分片集群中,不同shard的内存使用量可能差异很大,这叫做数据倾斜。极端情况下,某个shard已经打满内存触发淘汰,其他shard还有大量空闲内存。
数据倾斜的根本原因通常是hash slot的分配不均匀,或者某些热点key过于集中。监测和处理数据倾斜,需要有shard粒度的内存监控,而不仅仅是集群平均值。
集群级别的内存利用率,要看最高水位线,而不是平均水位线。一个集群平均内存使用率60%,但有一个shard已经到了95%,这个集群实际上已经处于危险状态了。
大key的危害
大key是指value非常大(比如几MB甚至几十MB)的key,或者集合类型中元素数量极多的key。
大key在内存上的危害是显而易见的:它会在单个shard上造成局部内存压力。但更隐蔽的危害是:对大key的删除操作(DEL)是同步的,会阻塞Redis事件循环,在千万QPS场景下,一个几十MB的key被删除,可能导致几毫秒的请求延迟尖峰。
Redis 4.0引入了UNLINK命令,异步删除大key,把实际的内存回收放到后台线程完成,避免阻塞主线程。在大规模集群中,应该养成用UNLINK替代DEL的习惯,并定期扫描大key,提前处理,而不是等到删除时才暴露问题。
集群扩容的内存平衡
当集群需要扩容时(增加新的shard),需要把现有shard的部分数据迁移到新shard。这个迁移过程,对内存使用有一个短暂的峰值:源shard在迁移完成之前,需要同时维护迁移数据的原始副本和迁移中的状态,内存使用会有一个短暂的高峰。
在内存已经比较紧张的时候做扩容,这个峰值可能触发淘汰,影响缓存命中率。扩容要提前做,不要等到内存快打满了才扩,给迁移过程留出足够的缓冲空间。
把内存优化纳入系统设计
最后一个话题,也是最容易被忽视的:内存优化不应该是运维层面的救火,而应该在系统设计阶段就嵌入进去。
设计阶段的内存预算
在设计一个新的缓存系统时,就应该做内存预算:
- 预计存储的key数量是多少?
- 每个key的value大概多大?用什么数据结构?
- 这些数据结构会触发哪种编码?
- 加上碎片率(比如预估1.2),总的内存需求是多少?
- 高峰期和低谷期的内存差异有多大?
这个预算不需要精确到字节,但要有数量级的把握。一个1000万key的集群,如果平均value是500字节,内存需求大约是5~10GB(考虑元数据和碎片),配置16GB内存应该够用;但如果数据结构设计不当导致平均开销是2KB,那就需要20~40GB。这个差距,在设计阶段提前发现,比上线后发现要便宜得多。
监控体系的建立
内存优化不是一次性的工作,需要持续的监控来发现问题。
值得监控的核心指标:
mem_fragmentation_ratio:碎片率,超过1.5需要关注,超过2.0需要处理used_memory vs used_memory_peak:内存使用率,建议告警阈值不超过80%evicted_keys:淘汰的key数量,频繁淘汰说明内存容量规划不足expired_keys:过期删除的key数量,和evicted_keys对比,判断淘汰是否正常keyspace:各db的key数量分布,发现异常增长- 大key扫描:定期跑大key分析,提前发现潜在问题
内存问题的发现越早,处理成本越低,这是内存监控体系存在的核心价值。
应急预案
即便做了很好的预防,线上内存告警还是会发生。提前准备好应急预案,能在问题发生时大幅缩短处理时间:
- 快速扩容方案(增加shard、提升单机内存)
- 紧急淘汰方案(降低maxmemory阈值,主动触发淘汰释放空间)
- 大key紧急清理方案(异步删除,避免阻塞)
- 碎片整理方案(开启主动整理,或计划性重启低流量节点)
内存的精细化是一个长期命题
回到文章开头的场景,那个凌晨三点的告警最终怎么解决的?
团队做了三件事:开启主动碎片整理,在一周内把碎片率从2.3降到了1.2;重新审视了用户属性的hash设计,把单个用户的属性hash拆成了三个(基础属性、扩展属性、行为属性),字段数从平均200个降到了60个,内存降了将近一半;以及给key的TTL加上了随机抖动,解决了过期key积压的问题。
这三件事加在一起,内存使用率从85%降到了45%,一台服务器撑住了原来需要两台撑的数据量。
内存优化这件事,有一个普遍规律:越是大规模的系统,内存优化的收益越是以“省去多少台服务器”来衡量,而不是以百分比来衡量。从十万QPS到百万再到千万,内存优化的手段没有发生质变(紧凑编码、合理分配器、碎片整理、策略控制这些工具始终有效),但优化的系统性、自动化程度和容量规划的精细度,必须随着规模一起成长。
在千万QPS的系统里,没有人能靠手工巡检来维持内存的健康,需要的是自动化的治理体系。而这套体系的建立,往往在百万QPS阶段就要开始谋划。
你现在的系统,内存利用率是多少?碎片率有没有定期监控?如果哪天凌晨三点告警响了,你有没有准备好的应急预案?欢迎在云栈社区分享你的实战经验与思考。
 发表于 2026-3-31 05:12:49
|
查看: 83|
回复: 0
发表于 2026-3-31 05:12:49
|
查看: 83|
回复: 0
