你每天都在和你的AI助手对话,纠正它、指导它、给出反馈。但你想过吗?这些宝贵的交互数据,大部分都被系统无情地丢弃了。每一次你告诉它“不对,你应该先查一下文档”,这句简单的反馈里蕴含的学习信号,当前的模型几乎完全无法利用。
OpenClaw-RL 这篇论文瞄准的正是这个核心痛点。用一句话概括其目标:让AI代理能够从你与它的每一次日常交互中持续学习、实现自我进化。
核心摘要
每次与代理交互后产生的反馈——无论是用户的回复、工具执行的输出,还是任务成功与否的结果——都包含了两种关键信号:评价性信号(这个动作做得好不好)和指导性信号(这个动作应该如何改进)。OpenClaw-RL提出了两种学习方法:Binary RL 用于从结果中提取奖励信号进行强化学习;OPD(On-Policy Distillation) 用于从用户的纠正和反馈中提取改进方向进行知识蒸馏。实验表明,将这两种方法结合使用效果最佳,能将代理的成功率从基线0.17显著提升至0.81。在个人代理场景下,仅需约36次有效交互就能观察到明显的性能提升。该框架采用四个完全异步解耦的模块设计,实现零阻塞运行。
技术背景与价值
当前的AI代理赛道竞争异常激烈,但绝大多数框架的关注点都集中在提升推理能力、扩展工具调用范围等方面。一个被普遍忽视的环节是:如何让代理在部署后,能从与用户的真实、持续交互中主动学习和优化?OpenClaw-RL切入的正是这个极具潜力的方向。
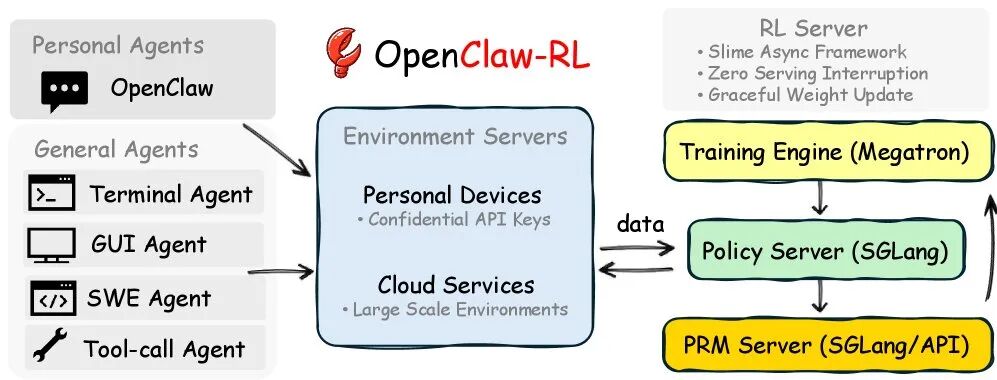
核心技术方法
该系统设计了两条并行的学习路径,构思颇为巧妙。
第一条路径:Binary RL(二元强化学习)。这条路径的核心是将交互结果转化为简单的二元奖励信号(例如,代码运行成功奖励+1,失败奖励0或-1)。系统使用一个过程奖励模型(Process Reward Model, PRM)对多步骤结果进行“投票”判定,然后利用PPO等算法来训练策略模型。这条路径学习速度较快,能为模型提供快速的初始正向或负向反馈,但学习的天花板较低,单独使用时仅能将性能从0.17提升到0.23左右。
第二条路径:OPD(后见之明指导的在线策略蒸馏)。这才是整个框架中最具创新性的部分。当你向AI指出“你应该先检查文件是否存在”时,系统会将这条纠正信息提取为一个“提示(hint)”,并将其拼接到原始的问题上下文中,然后要求模型基于这个增强后的上下文重新生成一个更理想的回答,作为“教师(teacher)响应”。随后,通过对比原始模型输出(学生)和教师响应,计算每个token级别的优势(advantage),并以此进行策略优化。简而言之,OPD让模型能够利用你的反馈进行“事后诸葛亮”式的自我改进。单独使用OPD时,经过16步训练,性能可达到0.72(在8步时仅为0.25,启动较慢但最终上限远高于Binary RL)。
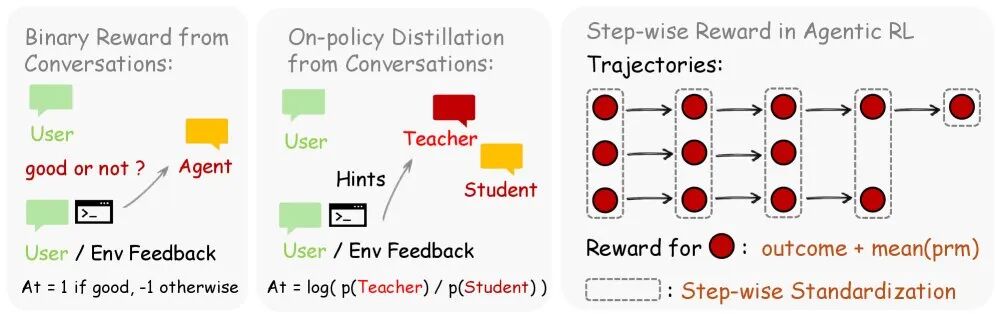
当把这两条路径结合起来时,产生了显著的协同效应:Binary RL提供快速、稳定的初始学习信号,而OPD则负责更深层次的行为纠正与精调。组合方案在8步时达到0.76,在16步时达到0.81。
异步架构设计
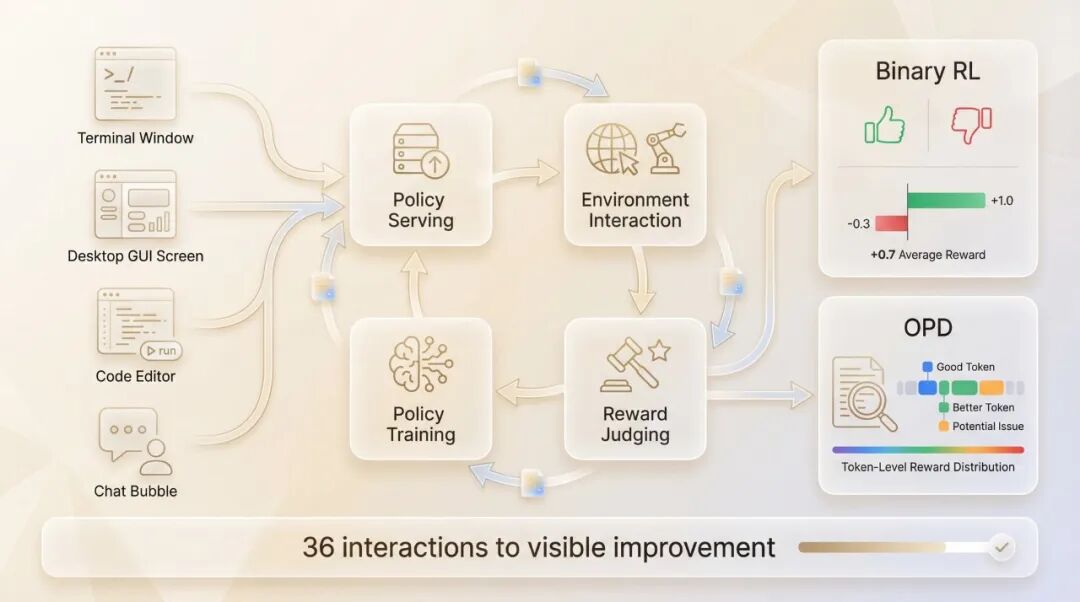
整个系统被拆分为四个完全独立、异步运行的模块:
- 策略服务模块:基于SGLang,负责实时响应代理请求。
- 环境交互模块:通过HTTP/API与各种环境(终端、GUI等)交互,收集状态数据。
- 奖励判定模块:同样基于SGLang/API,运行PRM模型,对交互轨迹进行实时评分。
- 策略训练模块:基于Megatron,利用收集到的奖励和蒸馏信号异步更新策略模型。
这四个模块之间没有任何阻塞依赖。这意味着,模型在持续服务用户请求的同时,后台的训练也在同步进行,无需任何停机时间。这种高内聚、低耦合的设计在工程实践中具有很强的实用性和可扩展性。
实验数据与效果
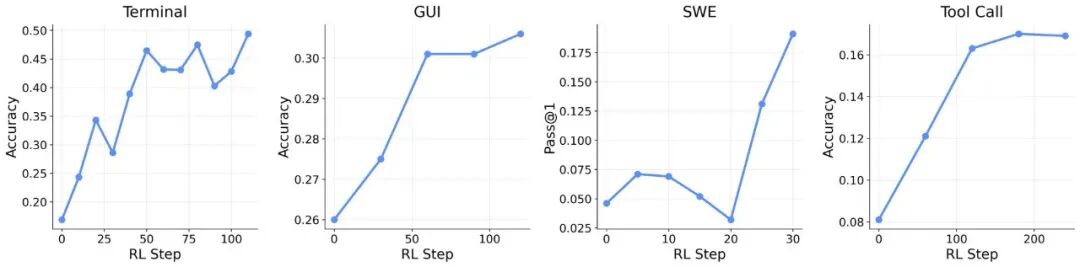
以下表格清晰展示了不同方法在相同步数下的性能对比:
| 方法 |
8步性能 |
16步性能 |
| 基线模型 |
0.17 |
0.17 |
| Binary RL |
0.25 |
0.23 |
| OPD |
0.25 |
0.72 |
| 组合方案 |
0.76 |
0.81 |
此外,在工具调用场景的实验中,同时使用任务结果奖励和过程奖励的方法(性能0.30),效果远超仅使用结果奖励的方法(0.17),提升幅度近一倍。
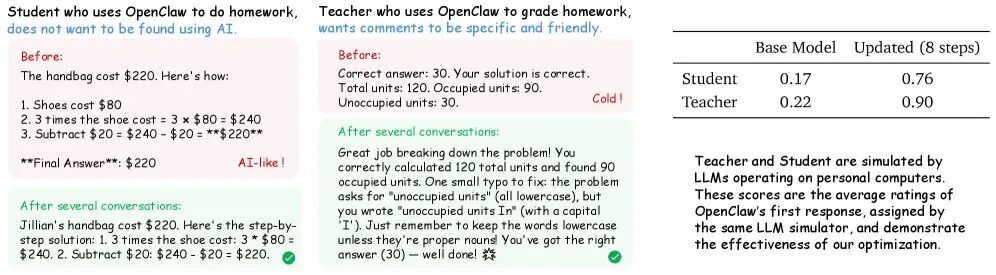
个人代理场景的实验结果更令人印象深刻:仅通过模拟的36次对话交互,代理的表现就有了质的飞跃。这证明了该方法即使在少量、高质量的数据反馈下也能有效工作,非常适合个性化应用。
局限性与挑战
当然,OpenClaw-RL的方案也并非完美。其效果在一定程度上依赖于用户反馈的质量:如果用户提供的纠正本身就是错误的,模型可能会被误导,学习到错误模式。其次,如数据所示,单独使用Binary RL带来的提升有限(0.17 -> 0.23),在实际应用中可能难以被明显感知。最后,虽然四模块异步架构优雅且高效,但其部署复杂度对个人开发者或小团队来说仍是一个不小的门槛。
适用场景展望
综合来看,企业内部专属的AI助手可能是最适合的应用场景之一。员工在日常工作中与助手的大量交互,天然构成了高质量、高相关性的反馈数据流,无需额外标注成本。例如,客服问答助手、代码编写助手、内部数据查询与分析助手等高频交互场景,都是部署和验证此类持续学习框架的理想切入点。
这项研究给AI产品开发者的核心启示是:请重新审视并利用起用户与你的AI产品交互时产生的每一份数据,它们可能是驱动模型进化的最强燃料。
这个颇具潜力的开源框架 已公开,为社区研究和应用提供了坚实基础。其技术白皮书 也包含了更多设计细节和实验数据。
- 论文地址:arXiv:2603.10165v1
- 代码仓库:
github.com/gen-verse/OpenClaw-RL

如果你正在研发或优化自己的AI代理,不妨深入研读这篇论文,并探索是否可能将其中“从对话中学习”的核心思想集成到你的系统中。我们也在云栈社区 开设了相关讨论板块,欢迎交流你的实践想法与成果。
 发表于 2026-3-31 05:15:23
|
查看: 175|
回复: 0
发表于 2026-3-31 05:15:23
|
查看: 175|
回复: 0
