当整个行业都在追逐大语言模型的参数规模时,Yann LeCun 选择了一条截然不同的道路,将研究重心完全放在了构建理解物理世界的 智能体 上。过去几周, V-JEPA 2.1、LeWorldModel 和 ThinkJEPA 等关键论文相继发布,标志着这条技术路线正加速走向成熟。
面对主流自回归模型在物理常识和多步规划上的根本性局限,JEPA(联合嵌入预测架构)给出了另一种思路:彻底放弃底层的像素重建,直接在抽象的特征空间中预测未来状态。这14篇关键论文,正是这套架构从理论构想走向工程现实,并最终展现出强大规划能力的完整记录。
核心机制概述:为何要放弃像素重建?
要理解 JEPA 的价值,首先得看清它试图解决的痛点。现阶段的大型语言模型擅长捕捉文本中的统计模式,但普遍缺乏对物理世界的常识认知,很难完成依赖多步推理的复杂规划任务。
为此,LeCun 主张构建 目标驱动的 AI 系统。在这个系统中,世界模型 扮演着核心角色。它负责模拟真实环境的运作规律,提前推演未来的可能状态,从而让智能体具备推理和动作规划的能力。JEPA 就是搭建这个世界模型的基础架构。
它与以往生成式自监督学习最本质的区别在于:JEPA 彻底抛弃了像素级重建。现实世界的信息量极为庞大且充满噪声,系统不需要(也不应该)浪费宝贵的算力去一比一还原输入数据的每一个细节。它的核心解法是在隐空间中提取抽象特征。
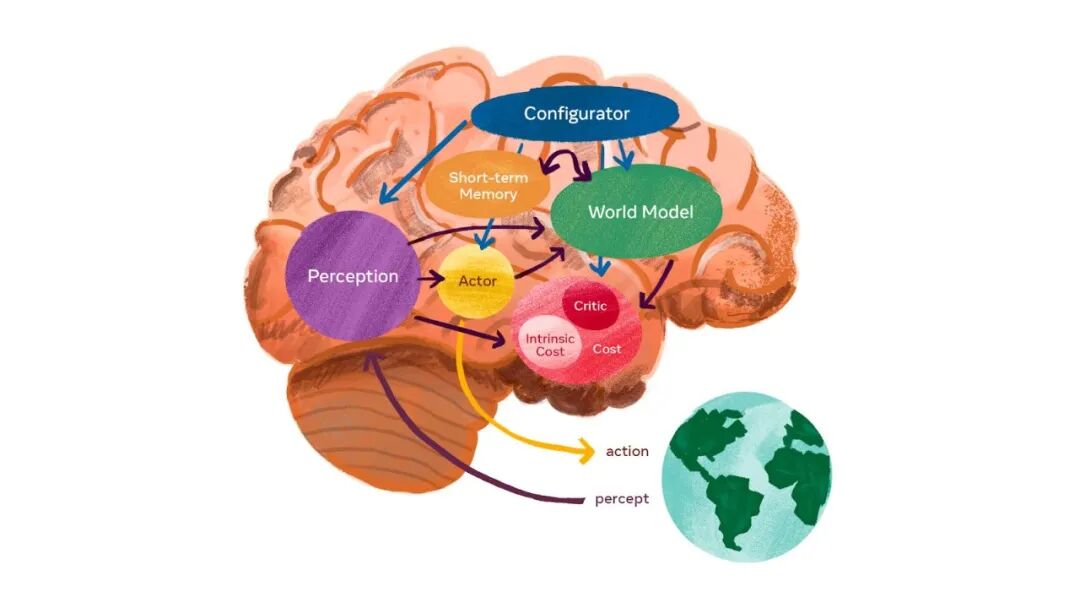
目标驱动的AI系统架构(来源:Yann LeCun)
在处理如视频连续帧这样的成对数据时,架构的编码器会先将其转化为抽象的表征。在这个提取过程中,背景噪声和无关细节会被自然剔除。随后,预测模块只利用当前的抽象表征,去预测未来的抽象表征。
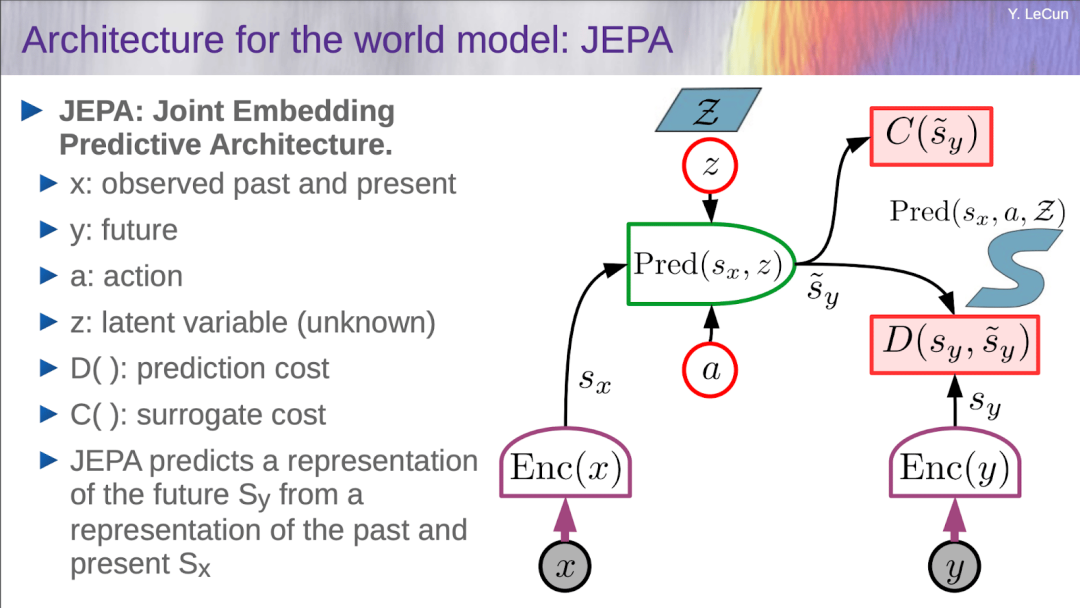
JEPA(Joint Embedding Predictive Architecture)工作原理示意图
为了应对现实世界演进中的不可预测性,架构在特征提取阶段,编码器会主动丢弃那些高度不确定或嘈杂的信息。不仅如此,架构还引入了 隐变量 。这个变量代表了当前状态下无法观测但会影响未来走向的潜在因素。通过调整隐变量的值,模型就能推演出在不同潜在因素作用下的多种未来走向,这为后续的规划能力奠定了基础。
阶段一:从理论到图像验证
在 JEPA 问世前,自监督 视觉学习一直被像素重建(如掩码自编码器 MAE)和依赖繁复数据增强的对比学习所主导。LeCun 打破了这一惯性,确立了一个核心原则:预测必须在抽象的表征空间中进行。
JEPA与H-JEPA:概念起点
JEPA 和 H-JEPA(Hierarchical JEPA)作为早期的理论蓝图,引入了层级化和多时间尺度的预测机制。这不仅是为了解决单一尺度的预测问题,更深层的目的是让模型具备对更高维度、更长周期状态进行推演的能力。这一阶段虽偏向理论构想,但为后续具备规划能力的 世界模型 划定了清晰的理论边界。
I-JEPA:视觉领域的首次成功落地
I-JEPA(Image-based JEPA)是将 JEPA 理论转化为工程实现的关键转折点。它证明了在不依赖任何手工设计的数据增强(如色彩抖动、裁剪)的情况下,系统依然能学到高度语义化的视觉表征,成为掩码自编码器之外一条极具竞争力的新路径。
整个流程基于 Vision Transformer (ViT) 构建,分为上下文编码器、目标编码器和预测器三部分。
- 训练过程:系统先在图像中随机采样多个目标块(占面积15%-20%),再采样一个更大的上下文块(占面积85%-100%),并确保两者不重叠。
- 编码过程:目标编码器的参数通过指数移动平均从上下文编码器更新而来;上下文编码器处理可见的上下文块。
- 预测与损失:一个轻量级预测器接收上下文特征和对应的掩码token,在隐空间中预测目标块的表征。损失是预测值与目标编码器输出的真实目标表征之间的 L2 距离。
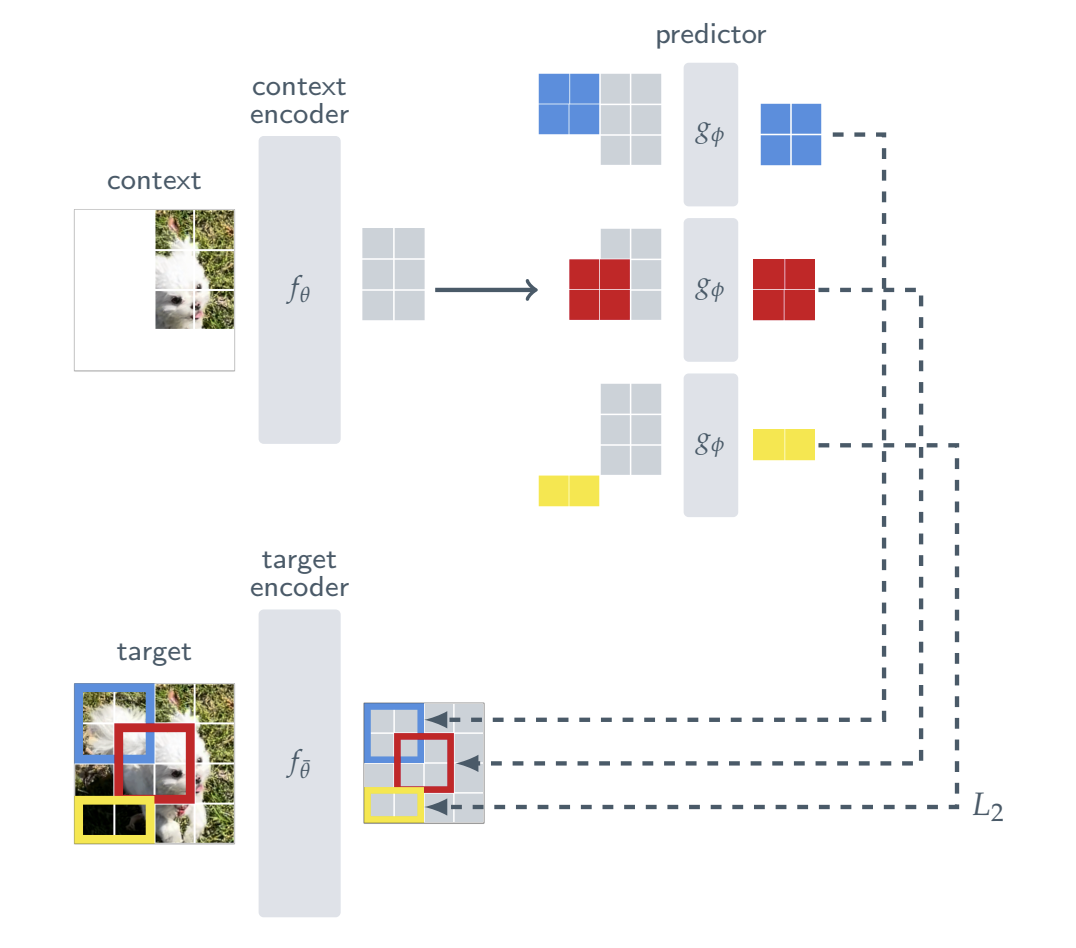
I-JEPA 方法流程图
掩码策略的革新 是设计的关键。如果只随机掩盖零散的图像块,模型很容易通过局部像素插值“作弊”,无法学习全局语义。I-JEPA 采用大尺度的目标块掩码,迫使模型必须理解图像的全局结构和语义内容。由于系统只需在隐空间中计算损失,无需解码还原像素细节,训练效率极高——预训练一个 ViT-Huge/14 模型,在16张A100上仅需不到1200 GPU小时。
阶段二:走向动态视频与跨模态理解
验证了图像领域的有效性后,架构的演进必然要面对现实世界中最核心的维度:时间与动态变化。这一阶段的研究,将特征预测机制推向了更复杂的时空数据和跨模态任务。
V-JEPA:视频特征预测的支柱性工作
V-JEPA(Video-based JEPA)是JEPA演进路线上的里程碑。处理视频时,若沿用像素级重建,时空维度的增加会导致计算成本爆炸。V-JEPA 有力地证明了:纯粹的特征预测完全可以作为视频自监督学习的独立目标,且无需依赖任何图像预训练、文本对齐或像素重建。
- 流程:输入视频被切分为空间16x16、时间跨度为2帧的时空token序列。
- 损失:采用 L1 损失(而非I-JEPA的L2),论文指出这在视频任务中更稳定。
- 掩码策略:设计了独特的 3D 多块掩码策略,在训练中平均丢弃高达90%的时空块。为防止模型通过相邻帧进行简单插值,掩码块会贯穿整个时间维度。系统混合使用短程掩码(多个小块)和长程掩码(少数大块),迫使模型在高度信息缺失下进行预测。
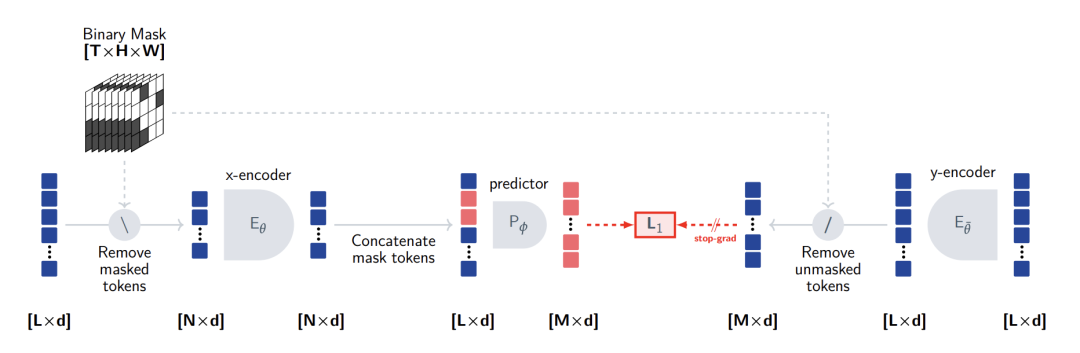
V-JEPA 架构流程图
这种训练方式使模型学到了极具通用性的视觉动态表征。在包含200万段视频的数据集上预训练后,V-JEPA 在需要精细动作理解的评测任务上,大幅超越了所有之前的视频掩码模型。同时,由于避开了像素解码,其训练速度比主流像素重建模型快约2倍,并展现出极高的标签效率。

V-JEPA 预测特征的可视化解码(仅根据上下文预测被遮盖区域)
Audio-JEPA:确立模态通用性
在视觉与视频领域成功后,Audio-JEPA 进一步证实了这套架构的底层通用性。它将特征预测机制迁移到音频频谱图上,通过引入时频感知掩码,让模型在隐空间中预测缺失的音频特征。这表明“避免原始信号重建、在抽象特征空间中进行预测”是一种可以跨越感官模态的通用学习法则。
阶段三:攻克无序的三维几何空间
从2D图像和视频跨越到3D点云,架构面临着新挑战:点云数据本质上是无序且不规则的。传统的点云掩码自编码器强行重建原始3D坐标,成本高昂且易受噪声干扰。
Point-JEPA 与 3D-JEPA
Point-JEPA 是专门为点云数据设计的JEPA变体。它避免在原始空间进行坐标重建,转而直接在隐空间中进行特征预测,成功绕开了点云数据中的冗余和噪声,证明了该架构处理复杂几何表征的高效性。随后的 3D-JEPA 进一步拓宽了架构在三维空间的适用范围,标志着它已成熟为处理完整3D语义的基础框架。
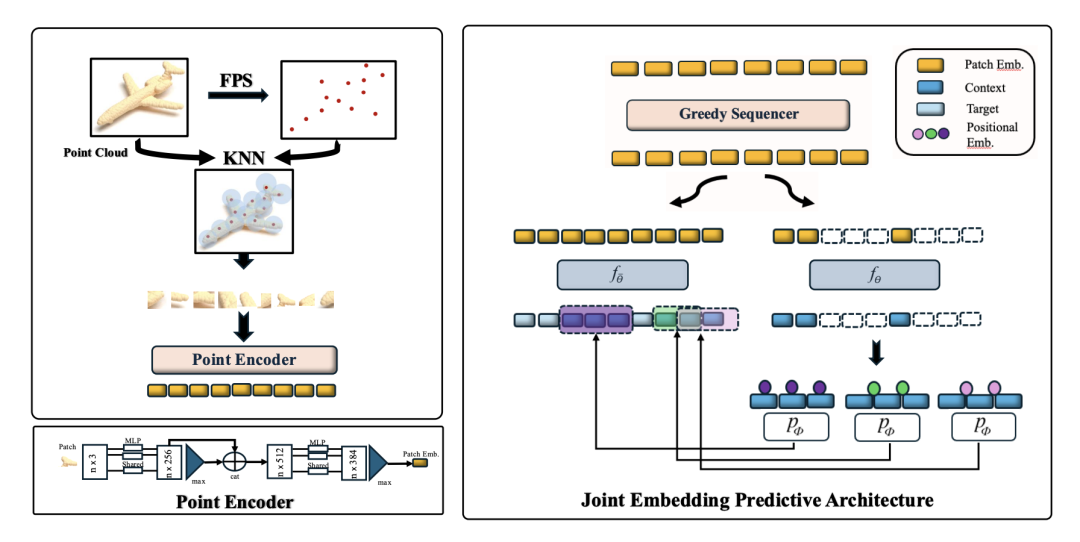
Point-JEPA 架构图
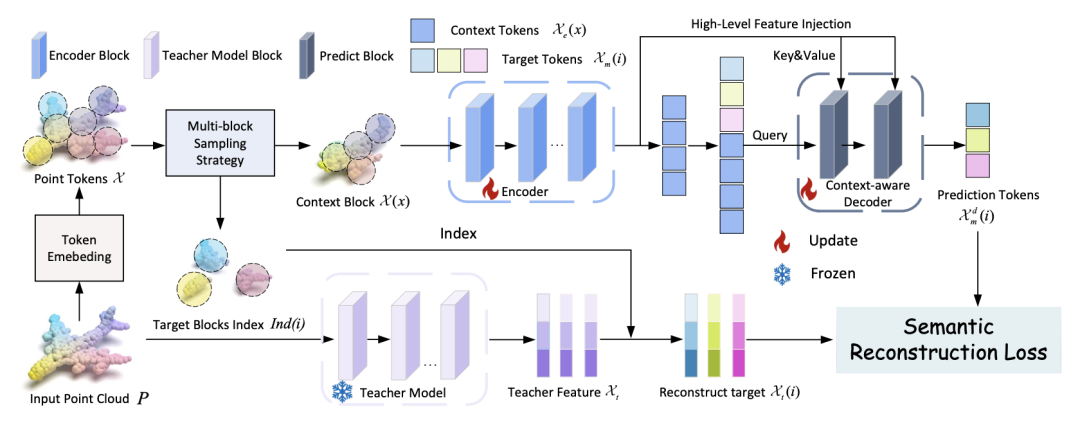
3D-JEPA 流程图
阶段四:接入动作变量,实现主动规划
在解决了静态和动态感知后,构建世界模型迎来了最核心的考验:理解动作如何影响环境,并据此进行多步推演。这一阶段标志着系统从被动感知正式跨入主动控制。
ACT-JEPA:引入动作的联合预测
ACT-JEPA 是JEPA走向完整控制系统的关键一步。它首次引入了 动作序列 这一核心变量。系统不再单一预测未来的观测特征,而是将动作序列与观测序列进行联合建模。这让模型不仅理解环境如何演变,更理解了特定动作指令会如何干预并改变环境走向,为后续的策略学习搭建了底层架构。
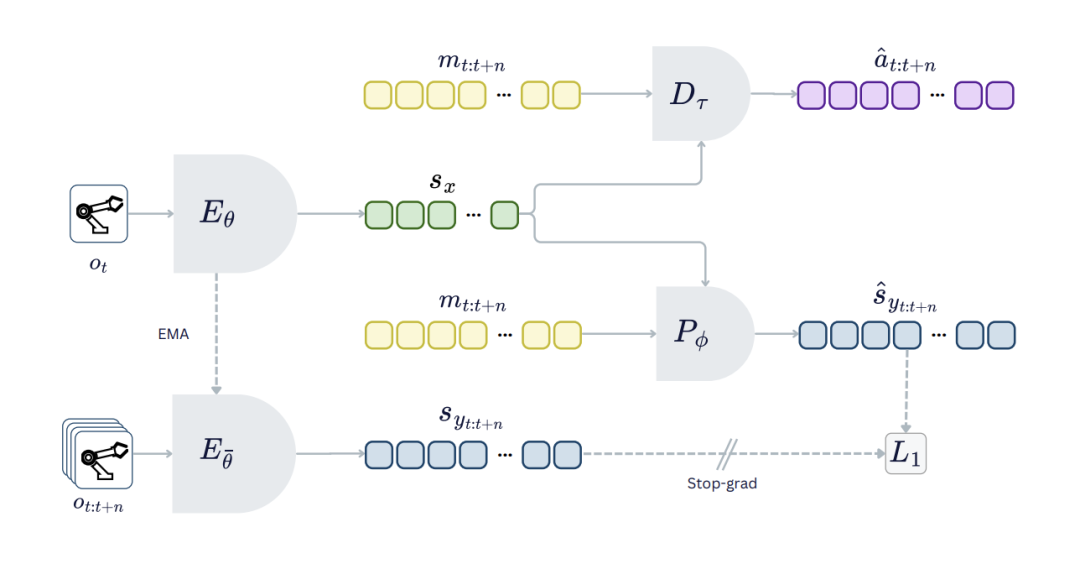
ACT-JEPA 架构流程图
V-JEPA 2:具备零样本规划能力的显式世界模型
V-JEPA 2 是该系列的决定性里程碑。此时,JEPA 正式演变为一个能够执行理解、预测与规划的 显式世界模型。其核心突破在于展现了 零样本机器人规划能力:在未经特定环境微调的情况下,模型能在一个未知的物理环境中,利用视觉子目标进行多步动作推演。系统在隐空间中模拟不同动作对应的未来状态,并筛选出达成目标的最佳路径,证明了基于预测的世界模型在具身智能领域的巨大潜力。
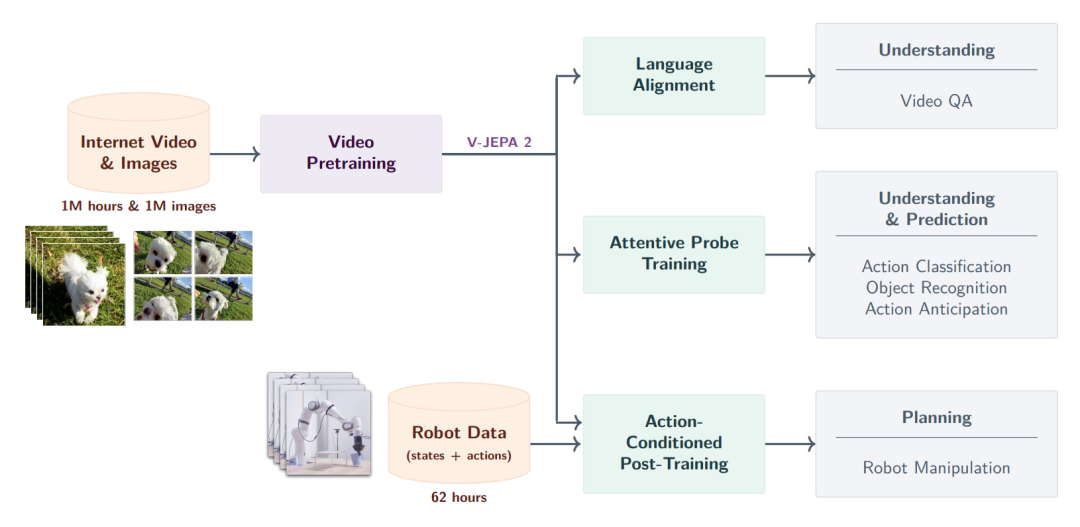
V-JEPA 2 训练与规划流程图
阶段五:底层重构与端到端演进
随着架构在感知和控制领域得到验证,研究重心开始向两个方向聚拢:一是清理早期工程技巧,回归数学本质;二是挑战更复杂的端到端训练和长周期推理。
LeJEPA:回归数学本质的简化
早期JEPA依赖指数移动平均、停止梯度等技巧防止表示坍塌。LeJEPA 从底层数学出发,引入 各向同性高斯正则化(SIGReg),直接约束隐空间的数据分布,移除了复杂的教师-学生网络和繁琐的超参数,让训练流程变得纯粹而稳定。
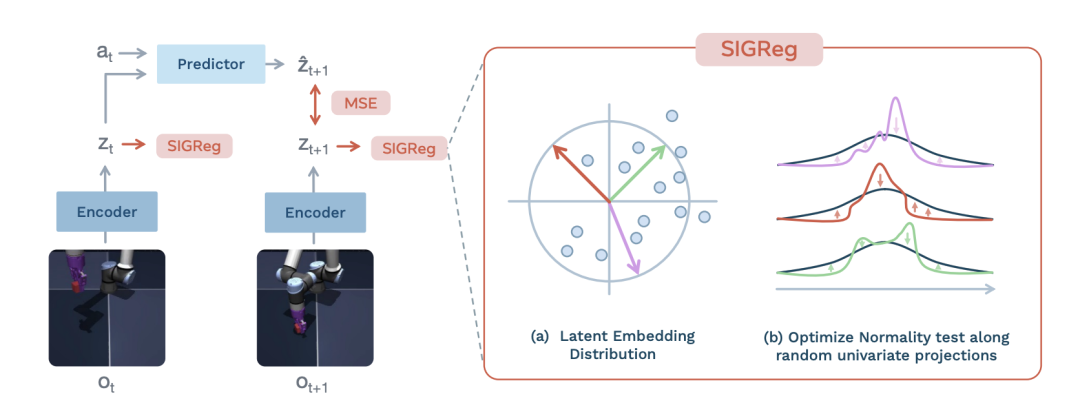
LeJEPA 中 SIGReg 模块工作原理
V-JEPA 2.1:极致打磨表征质量
在建立规划能力后,V-JEPA 2.1 回过头来极致打磨表征质量。它引入了密集预测损失,让所有token都参与损失计算,强化了模型对时空的精确定位能力。同时,在编码器的多个中间层级应用深度自监督,迫使网络在较浅层就开始理解复杂物理逻辑。
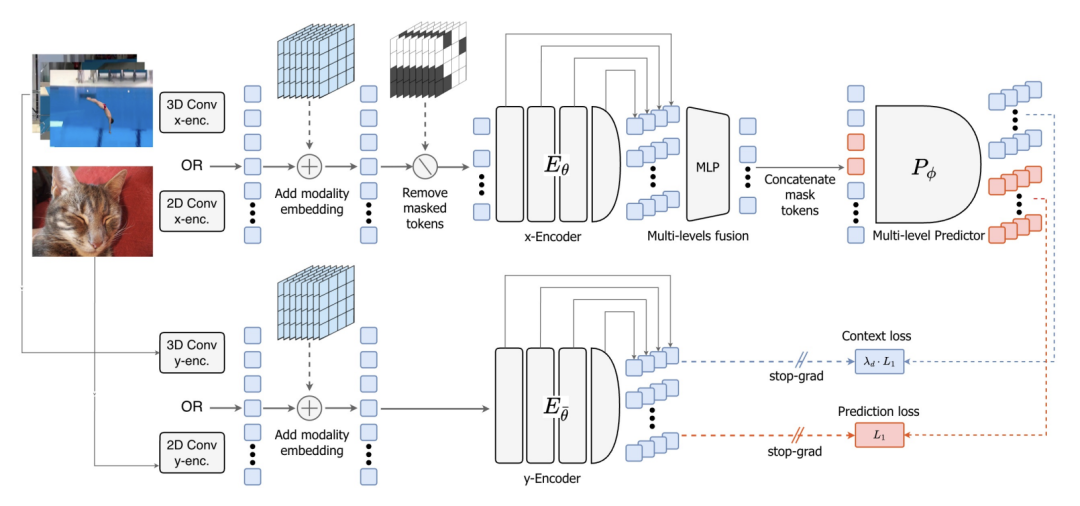
V-JEPA 2.1 架构流程图
LeWorldModel:极简的端到端世界模型
构建世界模型的传统难点在于保持特征空间稳定,常需拼接多项辅助损失。LeWorldModel 首次实现了完全从原始像素端到端稳定训练的极简架构。整个系统仅依靠 下一步特征预测 和 高斯正则化 两个目标驱动。这种轻量设计不仅降低了工程复杂度,更使其在控制任务中的规划速度远超传统流水线模型。
ThinkJEPA:融合语义思考的长周期规划
单纯的隐空间预测在处理长视野任务时易陷入低级特征外推。作为最新探索,ThinkJEPA 代表了向复杂推理的迈进。它将视觉语言模型中的深层语义知识,编织进隐式世界模型的预测路径中。有了语义维度的引导,系统不仅能捕捉短期物理动态,更能完成长周期的复杂逻辑链推演与任务统筹。
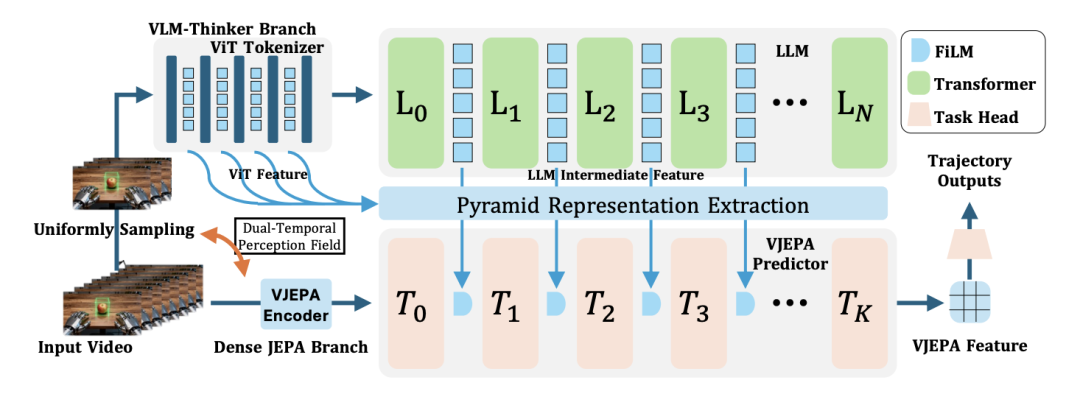
ThinkJEPA 整体架构图
结语:一条通向理解物理世界的道路
从图像上的隐空间预测,扩展到视频、音频与三维几何,最终实现端到端的动作与长周期规划,JEPA 架构的演进路线图清晰地展示了一条不同于主流自回归模型的技术路径。
面对大语言模型在物理常识和长序列规划上的内在局限,彻底放弃像素重建、转而在抽象特征空间中直接推演环境演变,已被证明是一条切实可行且潜力巨大的路线。这套机制让AI系统开始跳出单纯的模式匹配,尝试真正理解物理世界的运作规律,并最终获得执行复杂决策与规划的能力。对于关心 人工智能 前沿,特别是 世界模型 与具身智能发展的开发者和研究者而言,深入理解JEPA的演进脉络至关重要。如果你想与其他技术同行交流这类前沿话题,欢迎来 云栈社区 的相关板块一起探讨。
参考文献
- A Path Towards Autonomous Machine Intelligence
- Self-supervised learning from images with a joint-embedding predictive architecture
- Motion-Content JEPA
- V-JEPA: Latent Video Prediction for Visual Representation Learning
- Audio-JEPA: A Latent Predictor for Self-Supervised Audio Representation Learning
- Point-JEPA: A Joint Embedding Predictive Architecture for Self-Supervised Learning on Point Clouds
- 3D-JEPA: A Unified 3D Joint-Embedding Predictive Architecture for General 3D Representation Learning
- ACT-JEPA: Action-Conditional Joint-Embedding Predictive Architecture
- V-JEPA 2: Scaling Visual World Models for Zero-Shot Robotic Planning
- LeJEPA: Least-Constraint JEPA with Isotropic Gaussian Regularization
- Causal-JEPA: Causal World Modeling with Object-Centric Masking
- V-JEPA 2.1: Scaling Visual World Models with Dense and Deep Self-Supervision
- LeWorldModel: Learning World Models at Scale from Pixels
- ThinkJEPA: Integrating Semantic Abstraction into Visual World Models
 发表于 2026-3-31 05:59:15
|
查看: 249|
回复: 0
发表于 2026-3-31 05:59:15
|
查看: 249|
回复: 0
