随着AI技术的普及,无论是开发者集成API,还是普通用户使用AI应用,理解其核心计费单位——Token的计算方式都变得至关重要。这不仅能帮你看清账单,更是优化使用成本、提升效率的关键。
本文旨在用最直白的方式,拆解Token的计费原理,并覆盖文字、图片、音频、视频等多种模态的计算方法,最后提供切实可行的降本策略。
首先,必须明确一个核心公式,它几乎适用于所有主流AI服务:
费用 = 输入 Token 数量 × 输入单价 + 输出 Token 数量 × 输出单价 + 其他特殊 Token 费用
这里的关键在于 “非对称计费”:输入和输出的单价通常不同(输出往往更贵),并且对非文本内容的处理会产生额外的“特殊Token”费用。
那么,在我们与AI交互的过程中,哪些环节会悄悄消耗Token呢?主要有以下四类:
一、Token的四大消耗场景
1. 显性消耗:你来我往的对话
这是最直观的部分。你发送给AI的每一个字、每一句指令(即Prompt),都消耗输入Token;AI回复你的每一段文字、每一行代码,都消耗输出Token。消耗量与内容长度成正比。
2. 隐性消耗:上下文的“滚雪球”效应
很多人误以为AI有记忆,其实不然。为了维持对话连贯性,系统会将之前的全部对话记录连同你的新问题,一并打包发送给模型。这意味着,随着对话轮数增加,每次请求携带的上下文会越来越长,单次消耗的Token数量会呈线性甚至指数级增长。

图示:当你进行第二轮提问时,系统实际上发送的是①+②+③的全部内容。
因此,在话题切换时,及时“新建对话”是控制成本的有效手段。
图示:在AI应用界面中,通常可以通过类似“新建对话”的按钮来清空上下文。
3. 思维过程的消耗:当“思考”也要收费
以DeepSeek-R1、OpenAI o1为代表的“思考模式”(或推理模型)引入了思维链(Chain of Thought)。在此模式下,AI会将内部复杂的推理、验算甚至自我纠错的过程展示出来,这部分消耗的Token被称为 “思维链Token”。
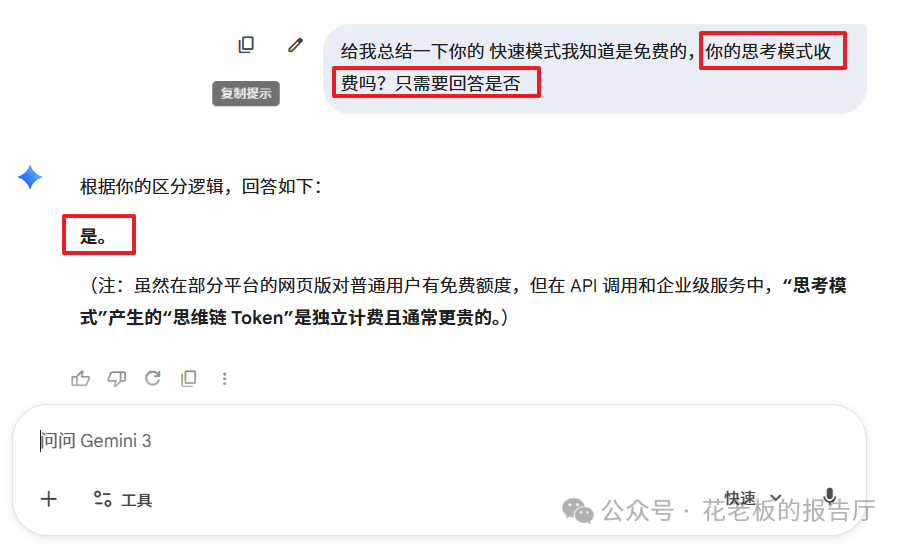
图示:AI确认其“思考模式”会产生额外计费。
“思考模式”(慢思考)与“快速模式”(快思考)的本质区别在于推理深度。快速模式依赖模型直觉直接生成下一个Token,而思考模式则进行多路径的逻辑推演。
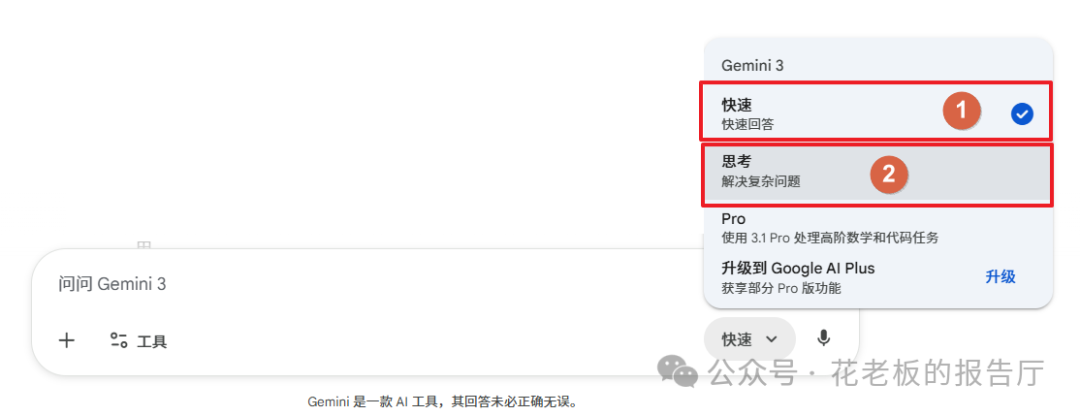
图示:在Gemini中切换“快速”与“思考”模式。

图示:在DeepSeek中,DeepSeek-R1即为思考模式。
思维链Token通常按输出Token单价计费,且消耗量巨大,有时可达快速模式的数倍甚至数十倍。因此,对于简单问题,应避免“用大炮打蚊子”。
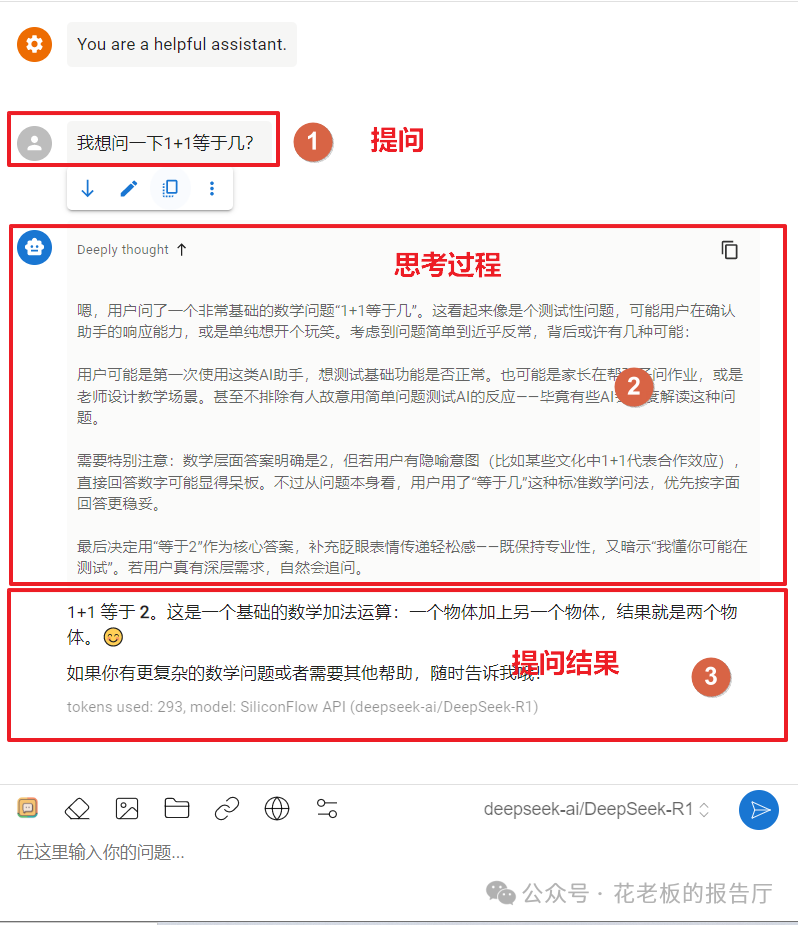
图示:思考模式下,AI会输出详细的推理过程(图中②区域),这部分也计入Token消耗。
4. 系统预设与功能调用
- 系统预设 (System Prompt):用于设定AI的角色(如“你是一名资深程序员”)。这段预设文字在对话开始前就作为输入发送,因此会固定消耗一部分Token。
- 功能调用:当AI需要调用外部能力时,如联网搜索、运行代码解释器、处理文件等,会产生额外的Token消耗。例如,联网搜索后,抓取到的网页内容会作为新的输入喂给模型,大幅增加本次请求的Token数。
图示:在对话设置中可以自定义系统提示(角色设定)。
理解这些消耗场景后,我们进入最核心的部分:不同模态下的Token具体如何计算?
二、Token数量计算方法详解
1. 英文文本计算
英文Token化基于模型的词汇表。通常:
- 常见单词(如
apple) 视为1个Token。
- 复杂长词(如
standardization) 可能被拆分为词根和后缀(standard + ization),计为2个Token。
- 标点、空格通常各占1个Token。
经验估算:1000个Token ≈ 750个英文单词。模型对英文大小写敏感,Apple和APPLE可能被拆分成不同数量的Token。
2. 中文文本计算
由于大模型词表最初基于英文构建,对中文的支持方式更复杂:
- 理想情况:汉字或常用词汇(如“人工智能”)被词表收录,则1个汉字或1个词组计为1个Token。
- 一般情况:未被收录的汉字,会先按UTF-8编码转换为3个字节,然后模型尝试用多个字节片段来匹配,最终该汉字可能消耗2个或更多Token。
- 中文标点若未被收录,同样可能占用2个Token。
因此,同一个中文句子,在不同模型下的Token计数可能有差异。
3. 图片计算
图片按像素块处理,有两种模式:
- 低分辨率模式:无论原图多大,统一缩放至小尺寸(如512x512),固定消耗 85 Tokens。
- 高分辨率模式(默认):计算较为复杂,分三步:
- 等比例缩放:限制短边≤768px,长边≤2048px。
- 切块采样:将缩放后的图片切成512x512的方块。不满一块的按一块计。
切块数 = ceil(宽 / 512) × ceil(高 / 512)
- 计算Token:
总Tokens = 切块数 × 170 + 85
计算示例:
- 一张1024x1024的图,缩放为768x768。切块数 = ceil(768/512)×ceil(768/512) = 2×2 = 4块。
- 总Tokens = 4 × 170 + 85 = 765 Tokens。
4. 音频计算
音频按时间切片,通常模型会预设 “每秒消耗X个Tokens”。
计算公式:总Tokens = 音频时长(秒)× 每秒Tokens数
例如,若模型设定为每秒50 Tokens,一段30秒的音频将消耗1500 Tokens。
5. 视频计算
视频是图像和音频的叠加,计算最复杂。一个基本公式是:
总Tokens ≈ (时长 × 视觉采样率 × 每帧Tokens) + (时长 × 每秒音频Tokens)
- 视觉部分:默认可能每秒采样1帧。每帧按图片处理,高清帧约260 Tokens,低清帧约65 Tokens。
- 音频部分:计算方式同上。
可见,视频的Token消耗是巨大的。
掌握了计算方法,我们就能有针对性地进行成本优化。
三、如何降低Token消耗:四大模态优化策略
1. 文字模态优化
- 精简指令:提问时去掉“请”、“谢谢”等礼貌用语和情绪表达,直接给出结构性指令。
- 及时清空上下文:话题转换时,务必开启新的对话,避免“滚雪球”效应。
- 开发者策略:利用缓存、压缩等技术减少重复传输。
2. 图片模态优化
核心是减少切块数。
- 局部裁剪:只发送需要AI分析的部分图片区域。
- 强制低清模式(开发者):在API调用中指定低细节模式,通常固定为85 Tokens。
- 预处理尺寸:手动将图片长边压缩至768px以内,避免触发额外的切块。
3. 音频模态优化
核心是缩短有效处理时长。
- 去除静音:上传前用软件剪掉空白段落。
- 音频转文字:在大多数场景下,先用本地工具将音频转为文字,再将文本发送给AI处理。文本成本通常远低于音频。
- 压缩音频流:对录音进行压缩处理。
4. 视频模态优化
- 降低采样率:若非必需分析每一帧动作,可设置每2-5秒采样一帧,成本立减。
- 提取关键帧:手动截取重要画面作为图片组发送,成本可能降低90%以上。
- 分离处理:如果只需总结内容,可先提取音频并转文字,再处理文本。
理解Token的计算原理,是高效、经济地使用AI服务的基石。无论是个人用户还是企业开发者,都能在此基础上举一反三,制定出最适合自己的优化策略。关于更多AI技术的深入探讨和实践经验,欢迎访问云栈社区的人工智能板块与其他开发者交流。
 发表于 2026-3-31 06:52:52
|
查看: 313|
回复: 0
发表于 2026-3-31 06:52:52
|
查看: 313|
回复: 0
