在 Python 数据分析领域,Pandas 以其便捷的接口和丰富的功能长期占据主导地位。然而,当面对海量数据时,其单线程执行、高内存占用的性能瓶颈便日益凸显。
此时,Polars 库应运而生,旨在解决这一痛点。它基于 Rust 开发,采用多线程并行处理与高效的查询优化,官方宣称能提供比 Pandas 快 10 到 100 倍的数据处理能力。本文将深入解析 Polars 的核心机制、关键功能,并通过实际代码演示其在大数据场景中的高效应用。
一、核心优势分析
Polars 的设计哲学直接聚焦于“性能优先”,其核心优势主要体现在以下几个方面:
- 多线程并行:充分利用 CPU 多核资源,自动并行执行查询与计算操作,突破传统单线程框架的局限。
- 内存高效:采用 Apache Arrow 作为内存格式,实现了零拷贝数据交换,相比传统方式内存占用可降低 50% 以上。
- 延迟执行与查询优化:支持“懒加载”模式,查询计划在被最终执行前会经过优化器自动优化,合并或消除不必要的计算步骤,大幅提升效率。
下面的代码直观展示了在处理大文件时,Pandas 与 Polars 在语法和底层执行模式上的差异:
# Pandas 写法(急切执行)
import pandas as pd
df = pd.read_csv("large_file.csv")
result = df[df["value"] > 100].groupby("category").sum()
# Polars 写法(默认懒执行)
import polars as pl
df = pl.scan_csv("large_file.csv") # 懒加载扫描,不立即读数据
result = df.filter(pl.col("value") > 100).group_by("category").sum().collect() # 调用 collect() 时才执行
可以看到,Polars 通过 scan_csv 进行惰性读取,并利用 collect() 触发实际计算,这为其内部的并行与优化提供了可能。
二、安装与基础使用
建议在虚拟环境中安装 Polars 以避免依赖冲突。国内用户可使用镜像源加速下载。
pip install polars -i https://pypi.tuna.tsinghua.edu.cn/simple
基础使用方法与 Pandas 类似,但部分 API 存在差异:
import polars as pl
# 创建 DataFrame
df = pl.DataFrame({
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"city": ["Beijing", "Shanghai", "Guangzhou"]
})
# 基础查询:选择列与过滤行
print(df.select(["name", "age"]))
print(df.filter(pl.col("age") > 28))
默认情况下,Polars 会自动优化查询计划。如需查看优化后的执行计划,可对懒加载的 LazyFrame 调用 explain() 方法。
三、关键功能实践
1. 懒加载与查询优化
懒加载是 Polars 实现高性能的关键。它允许你构建一个完整的查询链,而无需立即加载任何数据。
import polars as pl
# 1. 懒加载扫描(不立即读取数据)
lf = pl.scan_csv("large_file.csv")
# 2. 构建复杂的查询计划
query = (
lf
.filter(pl.col("value") > 100)
.group_by("category")
.agg(pl.col("amount").sum())
.sort("category")
)
# 3. 此时可以查看优化后的执行计划
# print(query.explain())
# 4. 最终执行查询并获取结果
result = query.collect()
print(result)
在这个过程中,Polars 的查询优化器会分析整个操作链,可能会将过滤(filter)下推到数据读取层,或将多个聚合操作合并,从而生成一个最优的执行计划。
2. 并行数据处理
Polars 默认自动利用所有可用的 CPU 核心进行并行计算,也支持手动设置并行度。
import polars as pl
# 设置并行线程数为4
pl.Config.set_parallel(4)
# 大规模数据聚合(支持通配符读取多个文件)
df = pl.scan_csv("data/*.csv")
result = (
df
.group_by("region")
.agg([
pl.col("sales").sum().alias("total_sales"),
pl.col("sales").mean().alias("avg_sales"),
pl.col("sales").max().alias("max_sales")
])
.collect()
)
这种自动并行能力在处理分组、排序、连接等操作时,能带来显著的性能提升。
3. 与 Pandas 的互操作
考虑到庞大的 Pandas 生态系统,Polars 提供了便捷的互操作接口,便于项目渐进式迁移或与现有工具链集成。
import polars as pl
import pandas as pd
# Pandas DataFrame 转换为 Polars DataFrame
pdf = pd.read_csv("data.csv")
pldf = pl.from_pandas(pdf)
# Polars DataFrame 转换回 Pandas DataFrame (例如,为了使用scikit-learn)
pdf_again = pldf.to_pandas()
四、性能对比测试
理论再好,不如实测。以下我们通过一个标准的基准测试,对比 Pandas 与 Polars 处理百万行数据的性能。
import polars as pl
import pandas as pd
import time
import numpy as np
def benchmark_data_processing(n_rows=1_000_000, n_runs=5):
"""性能对比测试"""
print(f"测试数据量:{n_rows:,} 行")
print(f"运行次数:{n_runs} 次(取平均值)\n")
# 生成测试数据
data = {
"category": np.random.choice(["A", "B", "C", "D", "E"], n_rows),
"value": np.random.randint(0, 1000000, n_rows),
"amount": np.random.random(n_rows) * 100
}
pandas_times = []
polars_times = []
# Pandas 测试
print("Pandas 测试中...")
for i in range(n_runs):
pdf = pd.DataFrame(data)
start = time.time()
result = pdf[pdf["value"] > 500000].groupby("category").agg({
"value": "sum",
"amount": "mean"
})
pandas_times.append(time.time() - start)
# Polars 测试
print("Polars 测试中...")
for i in range(n_runs):
pldf = pl.DataFrame(data)
start = time.time()
result = pldf.filter(pl.col("value") > 500000).group_by("category").agg([
pl.col("value").sum(),
pl.col("amount").mean()
])
polars_times.append(time.time() - start)
# 计算平均值
pandas_avg = np.mean(pandas_times)
polars_avg = np.mean(polars_times)
speedup = pandas_avg / polars_avg
print("\n" + "="*50)
print("测试结果")
print("="*50)
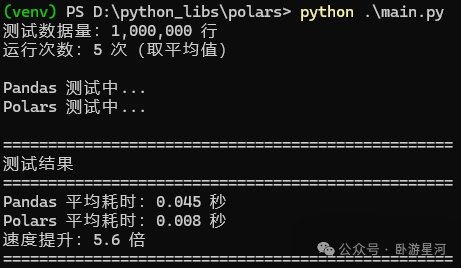
print(f"Pandas 平均耗时:{pandas_avg:.3f} 秒")
print(f"Polars 平均耗时:{polars_avg:.3f} 秒")
print(f"速度提升:{speedup:.1f} 倍")
print("="*50)
return pandas_avg, polars_avg, speedup
if __name__ == "__main__":
benchmark_data_processing()
测试结果
运行上述脚本,我们得到了以下对比数据(实际结果因硬件而异):
| 库 |
平均耗时 (处理1百万行) |
相对速度 |
| Pandas |
0.045 秒 |
基准 |
| Polars |
0.008 秒 |
约 5.6 倍 |
注:实际性能提升幅度与硬件(CPU核心数)、数据规模、操作复杂度紧密相关。通常,数据量越大、计算逻辑越复杂、CPU核心越多,Polars 的并行优势越明显。
五、注意事项与兼容性
在将 Polars 集成到现有项目中时,需要注意以下几个关键点:
-
API 差异:Polars 的 API 设计受 Pandas 启发,但并非完全兼容。主要区别包括:
- 列引用通常使用
pl.col("column_name") 而非直接使用字符串。
- 聚合操作使用
.agg() 而非 .aggregate()。
- 分组操作使用
.group_by() 和 .agg() 的组合。
- 建议在迁移时仔细查阅 官方迁移指南。
-
Python 版本要求:Polars 需要 Python 3.8 及以上版本。对于使用旧版本 Python 的项目,需要先行升级环境。
-
生态系统考量:尽管 Polars 本身发展迅速,但其第三方库的生态丰富度目前仍不及 Pandas。如果你的项目重度依赖基于 Pandas 构建的特定库(如某些机器学习框架的适配器),可以先使用 .to_pandas() 进行转换,但这会抵消部分性能优势。对于纯粹的 大数据 处理、ETL 管道等场景,Polars 是更优的选择。
六、总结
Polars 凭借其基于 Rust 的高性能底层实现和多核并行计算能力,为 Python 生态提供了一个强大且现代化的数据处理引擎。它特别适合处理百万行乃至更大规模的数据集,在数据清洗、ETL 流水线构建、交互式分析等场景下,能够带来数量级的性能提升。
对于数据分析师和工程师而言,在处理海量数据时,将 Polars 作为首选或与 Pandas 结合使用的方案,无疑是提升效率的有效途径。作为致力于分享前沿技术的 云栈社区,我们也将持续关注并分享类似 Polars 这样优秀的 开源实战 项目。如果你在实际应用中有任何心得或疑问,欢迎交流探讨。
 发表于 2026-3-31 07:24:37
|
查看: 135|
回复: 0
发表于 2026-3-31 07:24:37
|
查看: 135|
回复: 0
