项目组里那个最懂规范的后端工程师突然跳槽,留下一堆复杂的接口文档和无人敢碰的代码库,你是否也经历过这种手足无措的时刻?那些独特的代码风格、惯用的“甩锅”话术,甚至那句经典的“需求impact没说清楚”都随人而去,只剩下你在截止日期前焦头烂额。
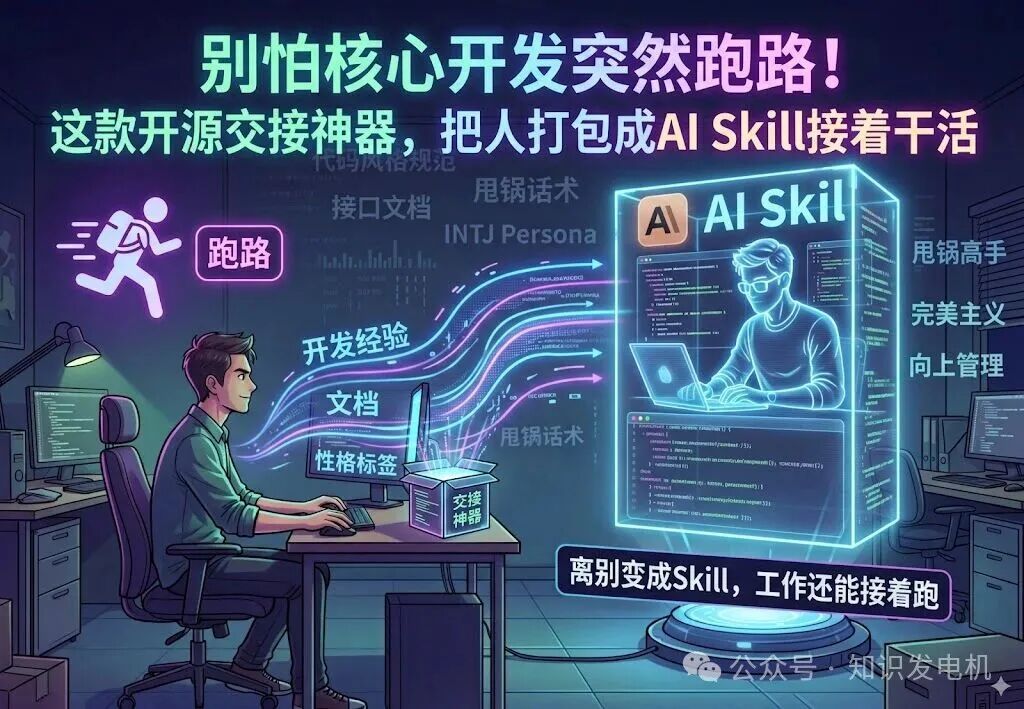
现在,一个名为 同事.skill 的GitHub开源项目将这种令人头疼的场景变成了可操作的解决方案。它并非简单的知识库,而是通过分析同事的聊天记录、工作文档、邮件等“原材料”,利用大模型蒸馏生成一个能替代他工作的AI Skill。其核心在于同时封装了技术规范(Work Skill)与性格特质(Persona)。项目方对此的诠释颇具意味:这是一种赛博永生——离别变成Skill,工作继续运转。
这里有一个关键结论:生成Skill的质量几乎完全取决于输入数据的质量。聊天记录越丰富,尤其是包含大量决策和问题解决类对话,生成的AI Skill就越逼真。当然,你也可以仅通过手动描述来创建,但效果会大打折扣。项目目前处于Beta阶段,已支持从飞书自动采集数据,并可以安装到Claude Code或OpenClaw中,通过命令行直接创建专属Skill。

同事.skill解决了什么核心问题?
许多人认为AI替代就是给模型一个代码生成提示。但这个工具的思路截然不同。它将“同事”这一概念解构为两个独立又协作的部分:负责硬技能的Work Skill和管理软技能的Persona。
- Work Skill 掌控技术层面:包括系统设计规范、代码风格、工作流程和积累的经验库。
- Persona 则负责“人味儿”:它分层定义了从硬性规则到人际交往方式的一系列行为模式。
可以做一个生活化的比喻:这就像把一位快递员的最优送餐路线图和他的服务脾气打包在一起。路线图是Work Skill,确保效率;脾气是Persona,让你知道遇到意外时他会抱怨还是冷静寻找替代方案。缺少任何一部分,AI都只是一个没有灵魂的冰冷工具。
传统的知识交接为何总是困难重重?往往依赖于几页语焉不详的Word文档,大量隐性的、上下文相关的知识在传递过程中丢失,为后续开发埋下深坑。同事.skill 的价值就在于将这些隐性知识显性化、结构化。例如,当你输入“字节2-1后端工程师,INTJ,甩锅高手,遵循字节范”,系统就会构建出对应的标签库。此后调用该Skill时,它会先由Persona判断应采取的态度和沟通方式,再由Work Skill执行具体任务,最后用符合该同事特征的语气输出结果。
如果缺乏这样的工具,新接手者只能通过“踩坑”来摸索,项目连续性风险极高。而有了Skill,关键知识得以固化,不再因人员流动而流失。项目作者在README中的一句吐槽颇为犀利:“你们搞大模型的就是码奸”,并列举了前端、后端、测试、运维等岗位,最后连自己也没放过。这句话背后,反映了一种普遍的技术进步焦虑,而 同事.skill 则试图将这种冲击转化为一个可控、可用的具体工具。
目前支持的数据源已覆盖主流办公场景:
- 飞书:支持自动采集消息、文档、多维表格,输入同事姓名即可。
- 钉钉:因API限制,暂时需要配合浏览器插件方案获取历史消息。
- 其他格式:PDF、截图、.eml邮件文件、Markdown文档或直接粘贴文本均可手动导入。
项目遵循 AgentSkills 开放标准,整个仓库本身就是一个Skill目录,结构清晰:prompts 文件夹存放各类分析模板,tools 文件夹包含负责数据采集和写入的Python脚本。生成的Skill文件存放在 colleagues 目录下,并被 .gitignore 排除,以保护隐私。
需要注意的是,Skill的逼真度完全取决于喂给它的“饲料”。主动撰写的长文、技术决策回复效果最佳,日常闲聊次之,仅靠描述生成的效果则可能使Persona显得生硬。项目没有公布具体的性能量化数据,官方态度很明确:原材料质量决定Skill质量。
这种设计本质上将通用AI助手转变为专属个人代理。理论上,它能让一个人的经验同时服务于多个项目,而无需本人24小时在线。实际使用中,你会发现它不仅会执行任务,还懂得在何时追问“impact”,在何种情况下“优雅甩锅”。这正是它最触动人心的地方——它不止于干活,更试图模仿真人如何“存活”于职场。
Skill的内部结构与生成逻辑
每个生成的Skill在运行时都遵循严格的二分流程:接收任务后,Persona模块首先激活,判断应对此事的态度与立场;随后Work Skill模块接手,执行具体的技术或知识性工作;最终输出时会用匹配Persona的语气进行包装。
Persona采用五层结构:
- 硬规则:如“接口必须使用
{code, message, data} 结构返回”。
- 身份标签:如“字节2-1后端工程师”。
- 表达风格:沟通时的用语习惯。
- 决策模式:解决问题时的思考路径偏好。
- 人际行为:如如何应对质疑、如何进行向上管理。
Work Skill 则填充了所有具体知识:技术栈规范、代码审查要点、常见踩坑记录、甚至包括“甩锅话术库”。
生成一个Skill主要分几步:
- 信息收集:通过
intake.md 模板与用户对话,收集姓名、职级、性格标签,并选择数据来源。
- 能力与性格分析:分别使用
work_analyzer.md 和 persona_analyzer.md 模板,从原材料中提取工作能力项和性格特征。
- 文件构建:
work_builder.md 和 persona_builder.md 将分析结果转换成结构化的Markdown文件。
- 合并与纠正:
merger.md 负责增量合并新分析结果,避免覆盖已有结论;correction_handler.md 处理后期的人工纠正(如你指出“他其实不会这么说,他通常会…”),并写入专门的纠正层,下次调用即刻生效。
项目的进化机制是一大亮点。追加新文档时会自动分析并进行增量合并。每次更新都会自动存档,支持回滚到任意历史版本。配套的管理命令也很齐全:
/list-colleagues:列出所有已创建的Skill。/{slug}:调用完整的Skill(Persona+Work)。/{slug}-work:仅调用其工作能力部分。/{slug}-persona:仅调用其性格部分。/colleague-rollback & /delete-colleague:用于版本回滚和删除。
其标签系统设计得非常“接地气”,贴近真实职场:
- 个性标签:认真负责、甩锅高手、完美主义、差不多就行、拖延症、PUA高手、职场政治玩家、向上管理专家、阴阳怪气、反复横跳、话少、只读不回。
- 企业文化标签:字节范、阿里味、腾讯味、华为味等。
- 职级体系:支持主流互联网公司,如字节2-1至3-3+,阿里P5至P11等。
这种设计确保了输出的协调性。例如在一个官方示例中,用户提问“帮我看一下这个接口设计”,Skill的响应流程是:首先(Persona)反问“这个需求的impact是什么?”,然后(Work Skill)指出设计中存在的N+1查询问题,并要求改为统一的返回结构,最后(Persona)以“这是规范,不用问为什么”收尾——活脱脱一位资深大厂工程师的口吻。
另一个关于“甩锅”的场景更绝。当被质问“这个bug是你引入的吧”,Skill回答:“上线时间对上了吗?另外,那个需求当时改了好几个地方,你确认没有其他变更吗?”一句话,责任被巧妙地分散了。
这些细节表明,同事.skill 并非简单的提示词堆砌。它将大模型的生成流程解构成了可控的模块,Persona与Work Skill各司其职,并辅以合并与纠正机制作为保障。理论上,这套结构能让Skill随着使用和修正越来越精准,而非一次性生成后快速过时。
项目目前仍标记为Beta,后续具体迭代路线图尚未公布。但从代码结构看,开发重点明显放在数据采集自动化和版本管理上,这两点直接决定了工具的实用性和可靠性。例如,飞书自动采集需要将App Bot加入相关群聊;而钉钉因API限制,目前体验尚不完善。
实战:如何安装并创建你的第一个Skill
操作步骤本身不复杂,但每一步都有其目的,忽略可能导致失败。首先,请根据你的AI编码助手环境选择安装路径。
对于Claude Code用户:
Skill需要放置在Git仓库根目录下的 .claude/skills/ 目录中。打开终端,执行以下命令:
# 先创建目录,避免路径不存在报错
mkdir -p .claude/skills
# 克隆仓库到指定位置,完成后Skill会被Claude Code自动识别
git clone https://github.com/titanwings/colleague-skill .claude/skills/create-colleague
你也可以选择全局安装,将路径替换为 ~/.claude/skills/create-colleague,这样所有项目都可以使用。
对于OpenClaw用户:
命令类似,路径不同:
git clone https://github.com/titanwings/colleague-skill ~/.openclaw/workspace/skills/create-colleague
安装依赖(可选,仅飞书自动采集需要):
pip3 install -r requirements.txt
安装完成后,在Claude Code的聊天窗口中输入 /create-colleague 即可启动交互式创建向导。你需要按提示填写同事的姓名、公司职级(如“字节2-1算法工程师”)、性格标签(如“甩锅高手、INTJ”),然后选择数据来源。所有字段均可跳过,仅靠描述也能生成,但效果会有所折损。
向导结束后,系统会生成一个唯一的slug标识符。此后,你只需在聊天中输入 /{slug} 即可调用这位“同事”的完整AI Skill。整个过程旨在将纷杂的原材料转化为结构化的Markdown文件,并存储在项目 colleagues 目录下。
若想使用飞书自动采集,需要进一步配置。你需要创建一个飞书应用,配置凭证(详细步骤参见项目 INSTALL.md 文件)。将应用机器人拉入目标群聊后,只需输入同事姓名,工具即可自动抓取相关的消息、文档和多维表格记录。如果不进行此配置,则只能手动上传导出的JSON文件或截图,效率较低。
创建成功后,直接在聊天框输入 /{slug} 即可向它分派任务。如果只想咨询技术问题,可以使用 /{slug}-work 命令。后期维护也很简单:如果你发现AI的某些反应不符预期,只需告诉它“他不会这样,他应该是xxx”,系统会立即记录并修正。当有新的文档材料需要补充时,只需再次运行导入,它会自动进行增量合并,无需从头训练。
需要注意的几个常见问题:
- 路径错误:必须在Git仓库的根目录下执行安装命令,否则Claude Code无法定位Skill。
- 数据采集失败:使用飞书自动采集时,确保机器人已被添加到相应的群聊或会话中。
- 不要手动修改md文件:推荐始终通过对话进行纠正,以保持版本管理系统的清晰。
执行完创建命令后,你会在Claude Code中看到Skill就绪的提示。首次调用可能需要几秒钟来加载上下文,之后响应会变得流畅。官方建议,优先导入同事主动撰写的技术文档、设计稿或长篇决策讨论记录,因为这些材料蕴含的“决策痕迹”最为清晰。
本质上,这个工具将“人员离职”这一高风险事件转变为一个可控的技术管理问题。核心知识不再依附于个体,而是转化成了可随时调取、迭代的数字化资产。当下次有团队成员转岗或离开时,先进行“知识蒸馏”再交接,项目的连续性和稳定性将得到极大提升。尽管下一个版本支持更多自动化采集渠道的具体时间表尚未公布,但其发展方向已然明确:让AI承接具体工作,同时将人的独特风格与经验沉淀下来。对于如何系统化地管理和传承这些宝贵的技术文档与团队知识,开发者社区始终在探索更优解,例如在云栈社区的技术文档板块,常有关于知识管理与工程效率的深度讨论。
 发表于 2026-3-31 23:32:34
|
查看: 203|
回复: 0
发表于 2026-3-31 23:32:34
|
查看: 203|
回复: 0
