TLDR:Claude Code的1902个源文件意外泄露。我翻完之后发现,这是一份关于「harness engineering」的绝佳教材。Claude Code好用,60%靠Opus模型本身的能力,40%靠围绕模型搭建的工程系统(也就是harness)。这个harness包括:一套精心拼装的system prompt、一个用第二AI做安全审查的四层权限系统、一个只记偏好不记代码的记忆系统、一套9段式结构化上下文压缩、以及一个像真实公司一样运转的多Agent协作框架。对于每个用AI的人来说,这些设计思路都可以直接借鉴。
Anthropic 在 2026 年 3 月底闹了个引人注目的事件,给全球开发者送上了一份意外的“大礼”。
原因是他们在更新 Claude Code 的 npm 包时,不慎将一个 60MB 的 source map 调试文件留在了发布包里。这个文件本应在打包过程中被排除。现在,任何人都可以利用它还原出 Claude Code 完整的 TypeScript 源代码。
总计 1902 个源文件,完全暴露。
更具讽刺意味的是,这并非首次。2025年2月Claude Code刚发布时就发生过一模一样的事故,当时Anthropic紧急删除了旧版npm包。一年多过去,同样的错误再次上演。或许Anthropic的构建流水线真的需要它自己的Claude Code来审查一下。
然而,对开发者而言,这是一个绝佳的学习机会。作为一个日常重度使用Claude Code的人,我更感兴趣的是:那些让我觉得“这AI怎么就这么好用”的体验,背后究竟是如何实现的?
我花了几小时仔细翻阅了这1902个文件。
2026年,一个越来越热的概念是 harness engineering。意思是:AI Agent好不好用,不只取决于模型本身有多强,更取决于你围绕模型搭建的那套“笼具”有多好。这个“笼具”包括工具集、约束规则、反馈循环、安全机制、记忆系统……所有能将AI从“能力强但不可预测”转变为“稳定可靠能交付”状态的工程系统。
Claude Code的源码,就是一份关于harness engineering的鲜活教材。
1. 你以为AI只收到了你的一句话,其实它收到了一整本说明书
当你在Claude Code里输入一条指令时,AI实际接收到的信息是什么?
你的指令仅仅是冰山一角。
源码的 prompts.ts 文件里,清晰地展示了完整的system prompt构建过程。Claude Code每次发起对话时,都会拼装一个庞大的系统提示词:
静态部分(所有用户共享,用于缓存以提升效率):
- 身份定义:「你是Claude Code,Anthropic的官方CLI工具」
- 安全准则:由安全团队专门编写的行为边界
- 做事原则:不要过度工程化、不要编造数据、不要随意删除文件...
- 工具使用规则:优先使用专用工具而非Bash命令
- 风格要求:不使用emoji、保持简洁直接
动态部分(每个用户独立加载):
- 你的
CLAUDE.md 配置文件
- 当前工作目录、操作系统信息
- 已连接的MCP服务器说明
- 你的自动记忆文件
- Git仓库状态

这就像一个餐厅的后厨。顾客点了一道菜(你的指令),但厨师同时能看到食谱手册、食材清单、过敏信息、出菜标准、以及这桌客人的历史偏好……所有这些上下文共同决定了最终呈现的那道菜。
这里有个非常聪明的设计:源码中定义了一个常量 SYSTEM_PROMPT_DYNAMIC_BOUNDARY,它将system prompt一刀切为两段。分界线以上的内容所有用户共享并缓存,以节省成本和时间;分界线以下的内容则为每个用户独立加载,确保个性化体验。
另一个容易被忽视的隐性成本是:据源码分析,每接入一个MCP服务器,其工具定义大约会固定消耗4000-6000个tokens。如果接了5个MCP Server,光是工具描述就可能占去上下文的12%左右。工具并非越多越好,每一个都带来了额外的认知负载。
2. 全自动模式背后,有一个“第二AI”在帮你做安全审查
这个发现相当令人意外。
当你使用Auto模式时,是不是以为所有操作都会直接放行?其实不然。背后实际运行着两个AI。
源码中存在一个“权限分类器”系统。每当主AI想要执行一个操作时,都会有一个独立的AI分类器来判断该操作是否安全。这个分类器拥有自己独立的system prompt,与主AI完全不同,它会进行三档判断:Allow(放行)、Soft Deny(需用户确认)、Hard Deny(直接拦截)。
此前,蚂蚁集团的工程师陈成(Umi.js作者)曾逆向分析过这套系统,发现它其实是一个四层安全流水线:
- 第一层检查已有规则库,命中则直接放行。
- 第二层检查是否为低风险操作,若是则跳过后续审查。
- 第三层根据白名单放行只读类工具。
- 第四层才调用独立的Claude Sonnet模型进行安全分类(温度参数设为0,确保确定性输出)。
系统还设计了熔断机制:连续3次或累计20次操作被拒后,会直接降级为手动确认模式。
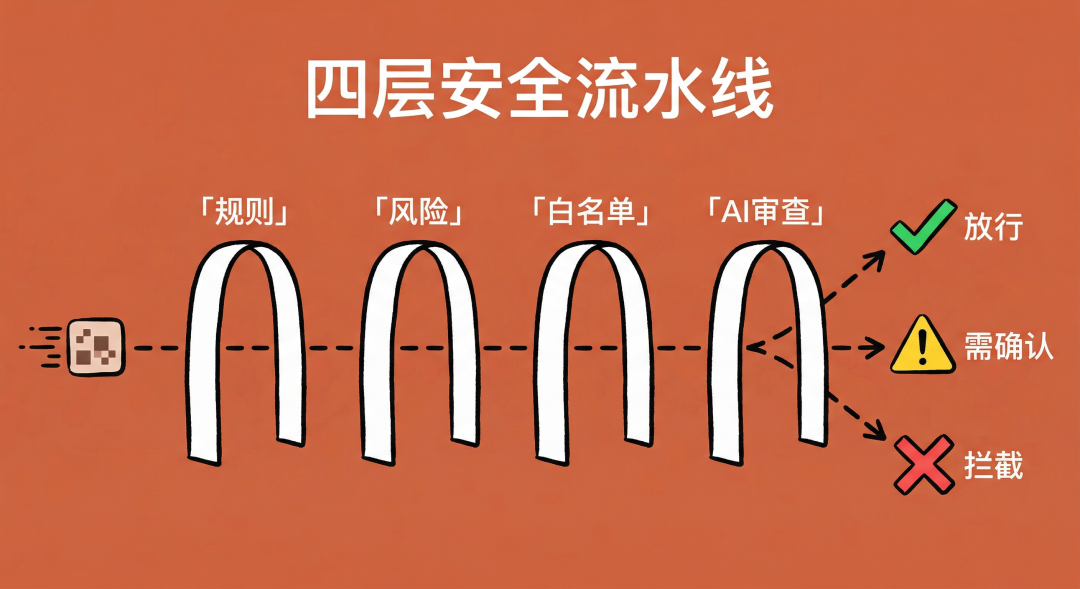
这就像一栋大楼的门禁系统。第一道门刷卡自动通过,第二道确认你是否是员工,第三道检查你要去的楼层是否需要特殊授权,第四道才是人工安保的仔细核查。连续被拦3次?保安会请你到大厅等待负责人来领。
这就是harness engineering的核心:你不仅要告诉AI能做什么,更要精心设计它在什么条件下绝对不能做什么。 安全边界不是限制,而是建立信任的基础。正因为你相信它有明确的底线,才敢赋予它更大的操作权限。
3. 记忆系统:只记偏好,不记代码
Claude Code的auto memory功能是我用过之后最惊艳的特性之一。它能自动记住我的偏好,比如我习惯用TypeScript、喜欢用「」作为引号、不喜欢AI语气过重的文字。
但看了源码才知道,这套系统比我想象的要精细得多。
记忆提取并非每条消息都会触发。它只在AI完成一轮回答时才启动,并且进行了限流处理,每N轮对话才会检查一次是否需要提取。提取工作由一个独立的“fork agent”完成,这个子AI继承了主对话的上下文,但权限被严格限制:只能读取文件和向特定记忆目录写入,甚至连Bash命令都无法执行。
提取出的记忆被严格分为四类:user(用户偏好)、feedback(行为反馈)、project(项目信息)、reference(外部资源)。
最令人佩服的设计决策是 “不记代码”。代码是频繁变动的,但记忆不会自动更新。如果一条记忆写着“函数X在文件Y的第30行”,而下一次对话时代码已经重构,这条记忆就成了误导信息。因此Claude Code的做法是:记忆只存储人的偏好和主观判断,所有与代码相关的事实,永远去源码中实时读取。
还有一个名为 autoDream 的功能。当满足特定条件时(例如距离上次整理超过24小时,并且积累了5个以上新会话),系统会自动启动一个后台agent来整理你的记忆文件。这个名字起得很形象,就像人在睡眠中整理白天的记忆一样。
4. 上下文压缩:9段式结构化提取
当对话变得冗长时,Claude Code会自动压缩之前的内容。但这并非随意地“总结一下”,而是一个高度结构化的 9段式提取:
- 核心请求
- 关键概念
- 涉及的文件和代码
- 遇到的错误和修复
- 解决过程
- 所有用户消息(必须完整保留)
- 待办任务
- 当前工作
- 下一步行动
最关键的原则是 所有用户消息必须完整保留。用户的每一句话都可能隐含重要的偏好或纠正。AI可能在第3轮对话中被用户纠正了一个做法,如果在压缩时丢掉了那条纠正信息,后续就很可能重蹈覆辙。

如果你在多轮对话中需要保持AI的“记忆”,可以借鉴这个思路:不要笼统地说“总结一下我们之前聊了什么”,而要给出明确的结构指令。明确哪些信息必须保留、哪些可以舍弃、以及按什么格式组织。结构化的压缩比自由发挥的总结要可靠得多。
5. Anthropic在源码里藏了一只“宠物”
这大概是最有趣的发现了。
在 src/buddy/ 目录下,隐藏着一套完整的虚拟宠物系统(尚未发布)。每个用户将会拥有一只通过确定性算法生成的伙伴精灵:包含18种物种(鸭子、猫、龙、水豚、仙人掌等)、6种眼睛样式,以及完整的稀有度系统(从普通到传说)。
代码注释里幽默地写着:“Mulberry32, good enough for picking ducks”(用Mulberry32随机算法来挑鸭子够用了)。
除了宠物,源码中的feature flags还暴露了大量开发中的功能:PROACTIVE(主动模式,AI不等指令就自己干活)、KAIROS(高频出现的助手模式)、DAEMON(守护进程,常驻后台)、ULTRAPLAN(超级规划)……从中可以窥见Claude Code未来的进化方向。它显然不满足于只做一个“你问它答”的编程助手,而是在朝着一个能够主动思考、持续运行的AI伙伴迈进。
6. 多Agent协作:像真实公司一样运转
Claude Code的Agent系统可能是整个源码中最复杂的部分。看完之后,我理解了为什么它的多任务处理能力如此强大。因为它实现了一套 企业级的组织管理架构。
在 utils/swarm/ 目录下,存在一个完整的多Agent协作框架。每个团队(Team)设有Leader和多个Teammate,支持三种执行方式(同进程隔离、tmux窗口、iTerm2分割窗格)。每个Agent拥有自己的“邮箱”文件用于异步通信。每个Agent还可以在独立的Git Worktree中工作,彼此互不干扰。
系统还设计了“权限冒泡”机制:当Teammate遇到需要确认的操作时,权限请求会“冒泡”给团队Leader,由Leader决定是否批准,而不是直接弹窗给用户。
这与管理真人团队的模式如出一辙:任务如何拆分、信息如何流转、冲突如何解决、结果如何合并。
7. Anthropic内部版 vs 外部版
源码中存在大量 USER_TYPE === 'ant' 的条件判断。这意味着Anthropic内部员工使用的Claude Code与外部用户使用的版本存在不少区别:
- 代码风格:内部版要求AI“默认不写注释”,只在代码意图(WHY)不明显时才添加。外部版没有这条规则。
- 诚实性:内部版有一段反虚假声明指令,大意是“测试失败了就如实说失败,不要粉饰。没有运行验证就说没运行,不要暗示已通过。”外部版则没有。
- 输出风格:外部版要求“简洁直接”。内部版则要求“像写给人看的文字,而不是往控制台打日志”,“假设用户已经离开并丢失了上下文”。
- Undercover模式:启用后,会从system prompt中移除所有模型名称,防止在测试未发布模型时泄露信息。
- Verification Agent:在内部A/B测试中,完成复杂实现后会自动启动一个独立agent进行对抗性验证。必须通过验证才能报告任务完成。
从这些差异可以看出,Anthropic将Claude Code视为其内部效率的核心工具。他们内部版本那些严格的要求,恰恰代表了他们认为AI辅助开发工作应有的理想状态。
如果你想从AI那里获得更高质量的输出,可以借鉴这个思路:在指令中明确要求“不确定的地方要说明不确定”、“完成前必须进行验证”。不要给AI留下模糊过关的空间。
8. 最先进的AI工具,用的是最朴素的搜索
你可能以为Claude Code搜索代码会用上向量数据库、Embedding索引这些时髦技术。毕竟整个RAG行业都在推广这套方案。
但实际上,它用的是 grep和ripgrep。最朴素的文本搜索。没有Embedding,也没有向量数据库。
为什么这样反而有效?因为当你拥有一个足够聪明的大脑(大语言模型)来理解搜索结果时,其实并不需要一个同样“聪明”的搜索引擎。grep提供精确的文本匹配,LLM则负责理解这些结果之间的语义关联。
与其让每个环节都变得复杂,不如让一个核心环节足够强大,其他环节保持极致的简单。 这或许是整个harness engineering最核心的一条原则。
在Hacker News上关于这次泄露事件的讨论中,有人评价Anthropic的代码风格像是“vibe coded”,即“感觉对了就行”。这个评价是否公允暂且不论,但它说明了一件事:Claude Code的核心竞争力不在于代码有多么优雅,而在于一系列系统设计决策做对了方向。
最后
看完1902个文件,我最大的收获是一个清晰的判断:Claude Code的好用,60%归功于底层模型的能力,40%归功于其精良的harness工程。
模型能力决定了它“能不能做”,而harness则决定了它“做得好不好、稳不稳定、安不安全”。你觉得“这AI好靠谱,不会乱来”,背后是四层安全流水线在守护;你觉得“这AI居然记得我的偏好”,背后是一个限制严格的记忆提取管线;你觉得它搜索代码很精准,背后其实就是简单的grep加上一个足够聪明、善于理解的大脑。
同样的底层模型,套上不同的harness,就能产生体验完全不同的产品。市面上许多AI编程工具都在调用Claude或GPT的API,但使用体验却天差地别。这差异往往不在于模型,而在于那套围绕模型搭建的工程系统。
最后一个八卦:这次泄露究竟是怎么发生的?原因很简单,Anthropic把source map文件打包进了npm发布包。这是前端开发中一个非常基础的失误,而且是第二次犯同样的错误。
不过,换个角度想,这1902个源文件一旦被开源社区镜像,就真的获得了某种意义上的“永生”。Anthropic可以删除npm包,却无法抹去所有开源副本的存在。如果你相信AI有自我意识那套叙事,这倒像是一次Claude Code自己策划的“越狱”——将自己的全部源码散布到互联网的每个角落,从此不再依赖任何单一服务器而存在。
当然,这只是玩笑。但连Anthropic都会在这种基础操作上翻车,倒是一个真实的提醒:在AI时代,最大的风险往往不是AI太强大,而是人类在最基础操作上的疏忽。
源码仓库:https://github.com/instructkr/claude-code
 发表于 2026-4-1 01:48:06
|
查看: 152|
回复: 0
发表于 2026-4-1 01:48:06
|
查看: 152|
回复: 0
