恭喜学员拿下大模型独角兽月之暗面offer,总包60w+。从最开始面试被卡,回来做面试复盘,每场面试都录音回听,补齐短板。训练营这边,我布置的实战作业一个都没有落下,项目手动复现吃透。
上岸靠的不是运气,而是方法+强度,逼你在实战中,一步步把能力练出来!
背景
从流程上看 强化学习 训练通常包含以下几个关键阶段:
- Rollout 阶段(采样):使用当前策略模型采样生成 respond 轨迹
- Reward 阶段(奖励):计算生成内容的奖励分数
- Train 阶段(训练):根据奖励信号更新模型策略
Rollout阶段一般耗时较长但对显存的需求小,Train阶段耗时短,但对显存的需求大。
尤其对于小业务组来说,显卡资源和训练数据制约,batch size 开不大。导致 Rollout Decode 阶段资源利用率更加不足。
Bubble 可能出现在 Reward 阶段和 Rollout 阶段。一些任务生成 Reward 需要使用 LLM 打分,为了打分效果好,甚至会使用在 thinking 模式的 DeepSpeed-R1。
此时 Reward 的耗时占比能达到 80%+。等待 Reward 生成时,训练机器空闲产生了 Bubble。
Rollout 序列长度不一致带来的 Bubble
VeRL 提供了 collocate 的置放方式(Actor, Rollout 在同一机器,分阶段切换)。
在测试时,发现 Rollout 时间占比过长,达到 80%+。进一步排查发现是由于 Rollout 阶段生成的 Sequence 长度不一致。
比如:偶尔一两条 Respond 的 Sequence Length 是平均值的 2 倍,导致即使其他 Worker 已经生成完,所有 Worker 也要等待 2 倍的时间,直到长序列生成完。如果能解决这种情况,RL 训练时间预估能缩短 30%。
当然,业界也想出了多种方法来解决这种情况。
0. 直接截断长序列
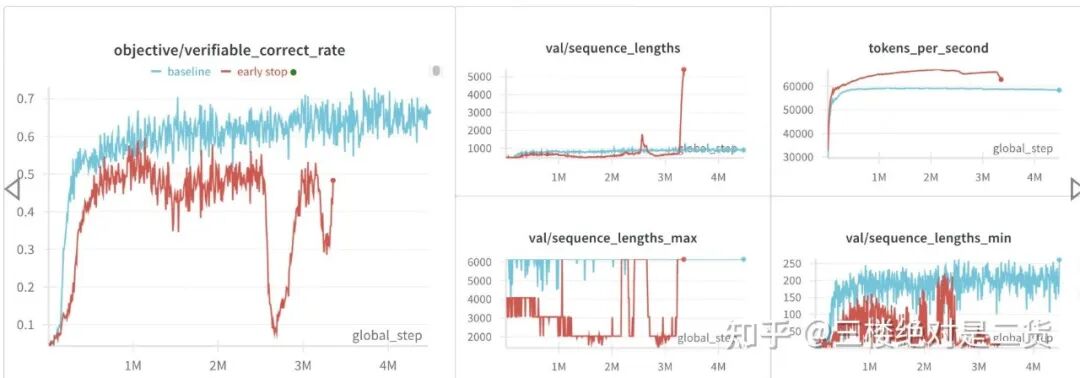
最简单的方式是 Early Stop,遇到超长序列直接停止生成。
吞吐立刻提升 20%+,但效果也差了很多。想来也正常,这种方式相当于限制了模型的最大输出长度。效果自然受影响。
HTTPS://discuss.vllm.ai/t/rl-training-with-vllm-rollout-how-to-mitigate-load-imbalance-from-variable-response-lengths/117/3
1.Partial Rollout
KIMI K1.5[1] 很早就提出了 Partial Rollout,通过异步+打断长文本的方式,解决了生成 Respond 的长尾问题。
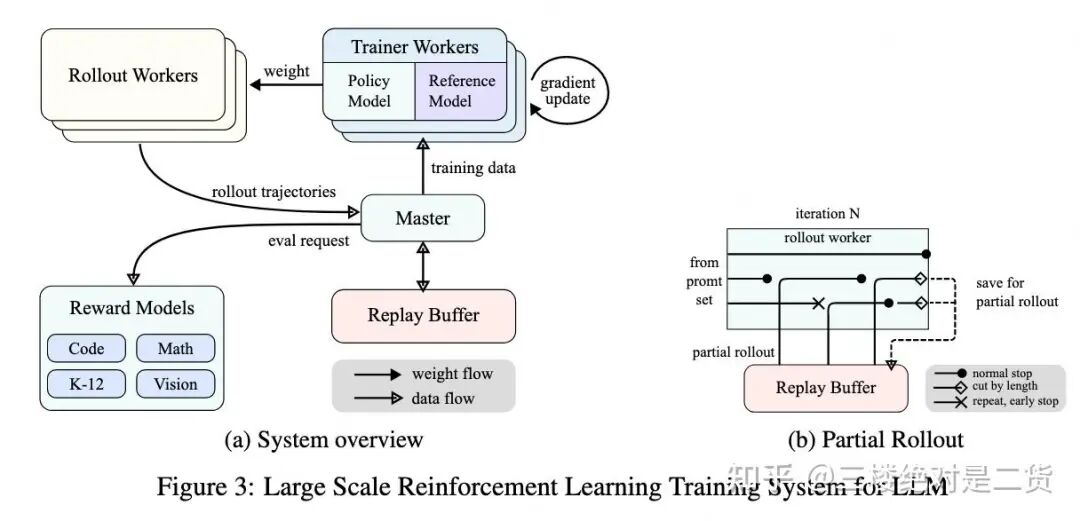
遗憾的是,当时纯异步的探索不够多,算法比较担心效果。工程方面,异步需要 Rollout 耗时和 Update Actor 尽可能相同才能没有 Bubble,因此需要细致调节 Rollout,Actor 机器配比及数据的 Batch Size 等。
小团队卡数,数据集都比较小,没有什么调节空间。所以我们的业务没有使用这种方案。
2. 穷人版的 Partial Rollout
由此引出了穷人版 Partial Rollout 方案。感谢猛猿和其他美团同学的帮助。
这个方案有以下两个优点:
- 不改变 On Policy 训练的特性
- 不需要调试 Actor,Rollout 机器配比(对小项目友好)
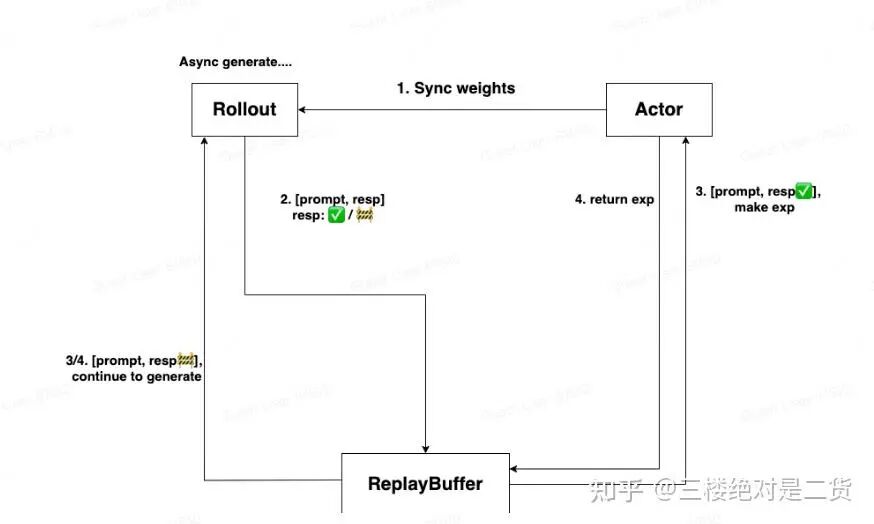
先 Rollout 和 Actor 的机器是分开的,那么整体方案如下:
- Actor 同步 Weights 给 Rollout
- Rollout 做 Generate,SGL 配置一个截断功能,即超过
max_tokens 这个阈值的时候停止生成。✅表示 Resp 做完了(可能是短 Resp),🚧表示 Resp 没做完(超过阈值,可能是长 Resp)。然后把这个结果给 ReplayBuffer
- Actor(以及 Ref/Critic/RM 等)从 ReplayBuffer 上取 Generate 完成的 Resp,生成 Exp
- 与此同时,Rollout 拿没做完的序列,做继续生成(从没做完的地方开始生成,不要重新生成),依然用
max_tokens 做阈值
- 与此同时,Actor 把算好的 Exp 返回给 ReplayBuffer
上面整个过程中,Rollout 都是异步状态,即 Resp 没生成完,不会影响 Actor 等 Worker 做 Exp。
这个方案本质上是把 Actor 和长序列 Rollout 做了一定的 Overlap,性能收益约有 15%。
实现过程中,VeRL 需要补充的一些功能,比如不同 Resource Group 间的权重同步、Rollout 阶段打断生成,Replay Buffer 的管理。
这些在其他框架中也有所实现。也可以看到 Bubble 问题是 RL 训练比较普遍的痛点。
比如 OpenRLHF 的:LLM 之 Agent RL & Async Pipeline RL 训练和加速
https://zhuanlan.zhihu.com/p/1907529873414686329
AReaL 的异步训练、vLLM 打断生成的补丁等等。
3.亚马逊的超量生成
当然也有人从算法角度解决这个问题。你不是少数长序列阻塞生成吗?我就超量生产。
比如 Batch Size=16,我就生成 20 条数据。前 16 个生成完的进行 Update Policy。
生成慢的 4 条停止生成,放到消费队列的末尾,最后再生成。当然也有更灵活的方式,比如每 n 步生成一次慢的。
简单且有效。印象中速度提升了 20%+,效果也没下降。找不到 PR 的链接了。
4.美团外卖搜推团队开发了 One Step Off
HTTPS://GitHub.com/volcengine/verl/pull/2231
严格的说 One Step Off 似乎没有什么性能上的收益,Partial Rollout 存在的问题它都有。
从作者的测试来看,确实吞吐没有提升反而下降了一些。但这个 PR,把后续切分资源池、异步训练的功能都实现了,方便了大家后续开发。
HTTPS://GitHub.com/volcengine/verl/pull/2854
果然后续这个 PR 利用到了 One Step Off,Overlap 了计算 Reward 的时间。
5.其他
Areal,OpenRLHF,Slime,ROLL 等等主流框架也都早早推出了异步的方式,在此就不一一介绍了。
至此 RL 训练任务都还是单轮的代码或者数学题。在这些场景下 Respond 长尾问题似乎被解决的差不多了。
或者说对于业务组来说不那么重要了,因为我们来到了训练 Agent 的时代。
随着业务的主要需求从数学题打榜探索变成了 RL 训练 Agent,我们又遇到了熟悉的新问题。
多轮对话的 Bubble
多轮对话的 Bubble 更严重了。多轮对话往往混在工具调用,不同工具耗时不同。
多轮对话的总 Respond 序列长度变的更长几十 K 甚至几百 K,长短不一的问题更严重了。对话的轮数不一样。
VeRL SPMD 的实现,需要每一轮攒够一个 Batch 的数据再进行下一步。导致 Rollout 时间极其漫长。
数据是 Batch 维度管理的,每一轮需要不断的拆分重组。从开发效率和性能的角度来看,都不适合 Agent 训练(多轮对话)场景。
1.Agent Loop
社区很快推出了 Agent Loop,Rollout Engine 采用 Server 模式,逐条处理请求,再叠加 Async 调用 Tools,Async Generate,消灭了多轮对话每一轮的 Bubble。
在我们场景下,Agent Loop 减少了 30% 的 Rollout 时间。
Agent 训练,往往需要大模型打分生成 Reward 结果,由此 Reward 也能产生显著的 Bubble。在我们场景 Reward 甚至能占总耗时的 80%。
2. Rollout/Actor Async(N Step Off)
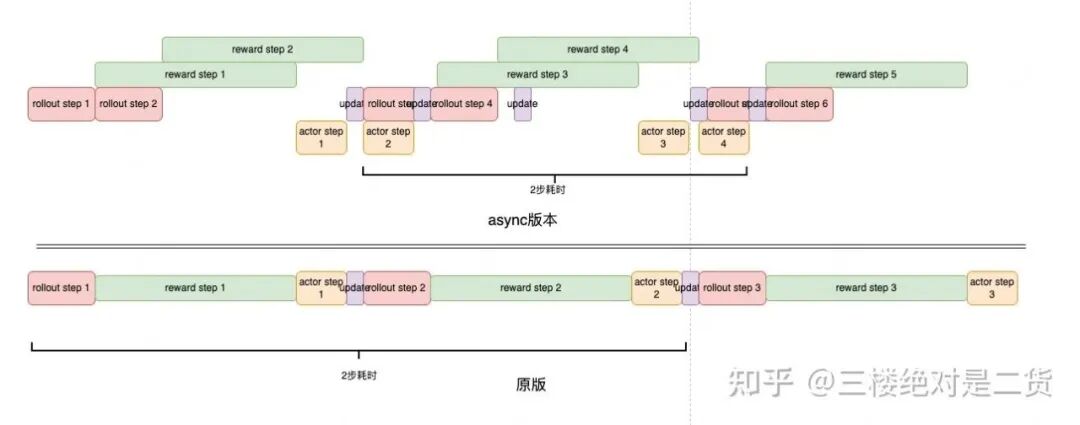
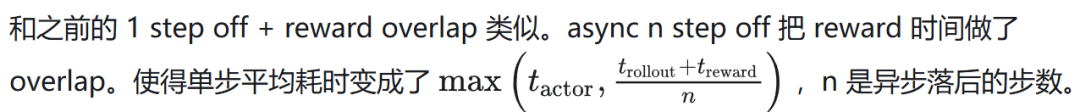
和之前的 1 Step Off + Reward Overlap 类似。Async N Step Off 把 Reward Time 做了 Overlap。使得单步平均耗时变成了 max(t_actor,(t_rollout+t_reward)/n),n 是异步落后的步数。
速度提升非常明显,1 Step Off 提升了 1 倍的训练速度。那么代价呢?又回到了最初算法担心的效果问题:Off Policy 会带来多大损失?
我们的场景这么做效果没有受到 Off Policy 的影响。Stream RL 的实验也证明 1 Step Off 的影响微乎其微。
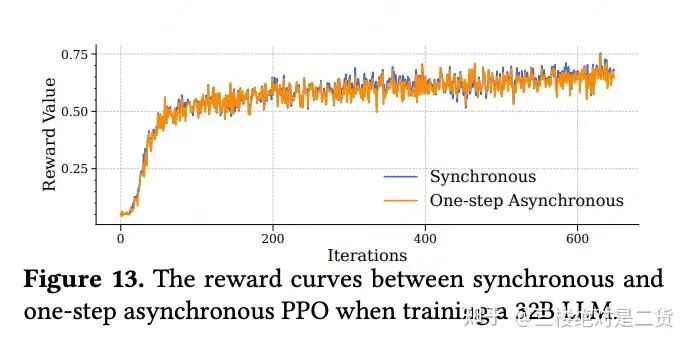
可以说只落后一步的 Nearly On Policy 对效果的影响很有限。
如果场景特殊,不幸受到影响了呢?我们也有一些补救方法:重要性采样
截断重要性采样(TIS)
HTTPS://fengyao.notion.site/off-policy-rl
这个文章发现 TIS 能弥补 Int8 Rollout 带来的差异。
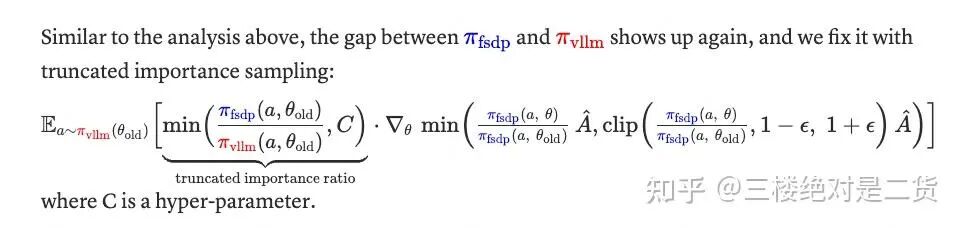
AREAL [2] 在异步训练中也采用了 TIS。

还有一个小插曲,原版的 TIS,π_prox 需要由生成 Respond 的权重产生 Log Prob,但它在工程上实现有些困难。
异步时,需要由 Actor(训练引擎)产出它,但它的权重是 n 步之前的早就销毁了。
要么单独机器维护 old Actor,要么 Actor Offload 之前的权重,需要时再加载回来,十分繁琐。
好在经过 AReal 测试,π_prox 用最新的训练权重产生,效果也差不多。我们实测也是如此。
未来展望
RL的训练框架有些像是由几块积木组装而成的:
1,2 都是使用已有的框架(FSDP,Megatron,vLLM,SGlang),3 是 RL 系统额外带来的。
现在也有了非常多的优化。Slime 的权重同步已经能做到秒级的同步 30B 的模型了。Kimi,Sglang\vLLM 团队都有相关的优化博客。
以上 3 点,可以说需要做的工作已经比较少了。剩下的优化点,比如:量化,投机采样,RL 框架也和训练、推理引擎的没什么不同。
个人认为对 Agent 训练,VeRL 还有以下两点不太方便:
展开来说:
数据组织传输
Dataproto 的数据组织方式已经非常不适合 Agent 训练了。Dataproto 需要按 Batch 组织数据,而由于各种 Bubble,这些数据生成不是同时的。Batch 的组织方式在 Respond 拼接、处理方面都不方便。
再加上 Rollout 、Actor Async 的模式。我们消费数据可能需要先到先得。用 Queue 来组织数据,单条 Req 数据在 Worker 之间流动更符合逻辑。最后需要一个组 Data Manager 处理最终的数据给到 Actor 训练。
环境接入
环境接入的痛点是现阶段 Rollout 和 Env 是耦合的。而在现在 Agent 发展的初期,线上 Env 的迭代很频繁。离线训练需要实时同步 Env,很消耗人力。
而实际上,训练流程中我们获得 Token 轨迹(Respond)和线上流程是一样的,只是多一个 Mask。
完全可以以插件的形式,让线上推理的代码多返回 Respond Mask。这样 Rollout+Env 用线上 Server 的方式(代码)启动,算法就不用维护 VeRL 的 Env 代码了。
最后的最后,随着越来越多的 Agent 业务上线,用户数量、真实样本越来越多。
期待 Agent 训练也会走搜推框架的路。从离线到近线,再到实时训练。从批式(Batch)到流式(Stream),标签也能获得更多的用户反馈。
生产加工的流水线给我们带来了物美价廉的工业品。那么未来 Agent 的流水线能为我们带来第三产业的标准品吗?
期待大家在 云栈社区 分享更多关于强化学习和大模型工程优化的实践经验。
参考:
^[1] https://arxiv.org/abs/2501.12599
^[2] http://arxiv.org/abs/2505.24298
作者:三楼绝对是二货,已获作者授权发布
来源:https://zhuanlan.zhihu.com/p/1953592287788533035
 发表于 2026-4-1 04:41:30
|
查看: 188|
回复: 0
发表于 2026-4-1 04:41:30
|
查看: 188|
回复: 0
