当你对 AI 说“随便改改这个项目”时,你真正担心的是什么?是它可能漫无目的地修改几十个无关文件,还是擅自引入未知依赖,或者留下一堆无法理解的“fix”提交?这背后,恰恰是 AI 编码助手 从玩具走向生产力工具必须跨越的鸿沟——可控性。
Harness 工程的本质,就是为 AI Coding 设定清晰的边界:让它明白什么能做、什么不能做、在什么范围内做,以及做完后如何交付。通过对近期一份工程实践的梳理,我们可以深入了解 Claude Code 如何通过四层体系——工具层、权限层、Agent 层和生命周期层——来构建一个既灵活又安全的 AI 编码安全框架。
工具层:精准掌控 AI 的“武器库”
在 Claude Code 中,所有能力都以“工具”的形式暴露给 AI。工具层 Harness 的核心任务,就是严格控制 AI 手中可用的工具种类与范围。
工具注册表机制
所有基础工具都在一个统一的注册中心 tools.ts 中进行定义和注册,并通过 getAllBaseTools() 函数统一输出。这是系统唯一的“真相来源”。
export function getAllBaseTools(): Tools {
return [
AgentTool,
TaskOutputTool,
BashTool,
GlobTool,
GrepTool,
FileReadTool,
FileEditTool,
// ... 40+ 个工具
];
}
任何工具的增、删、改都必须在此进行,确保了不会存在任何隐藏的、未经审计的能力。
工具池动态组装
每个 Agent 在调用工具时,并不会直接使用所有注册的工具,而是通过 assembleToolPool() 函数,根据当前上下文动态组装一个专属的工具池。
export function assembleToolPool(
permissionContext: ToolPermissionContext,
mcpTools: Tools,
): Tools {
const builtInTools = getTools(permissionContext);
const allowedMcpTools = filterToolsByDenyRules(mcpTools, permissionContext);
// 内置工具在前,MCP 工具在后
// 顺序稳定:服务端有缓存断点,顺序一变缓存全部失效
return uniqBy(
[...builtInTools].sort(byName).concat(allowedMcpTools.sort(byName)),
'name',
);
}
这里有一个至关重要的设计细节:工具列表的顺序是严格固定的。这是因为服务端 API 依赖此顺序生成全局缓存键。顺序一旦改变,将导致大量缓存失效,严重影响性能。因此,Claude Code 严格维护了工具注册和排序的稳定性。
条件加载与 Feature Flag
工具系统还支持基于 Feature Flag 的条件加载,这通常用于实验性功能或A/B测试。
// 如果 COORDINATOR_MODE 关闭,这个模块不会被编译进产物
const coordinatorModule = feature('COORDINATOR_MODE')
? require('./coordinator/coordinatorMode.js')
: null;
这是一种编译时的“死代码消除”策略,而非运行时的 if-else 判断。这意味着,当某个功能被禁用时,其相关代码根本不会被打包到最终产物中,减少了潜在的攻击面和运行时开销。
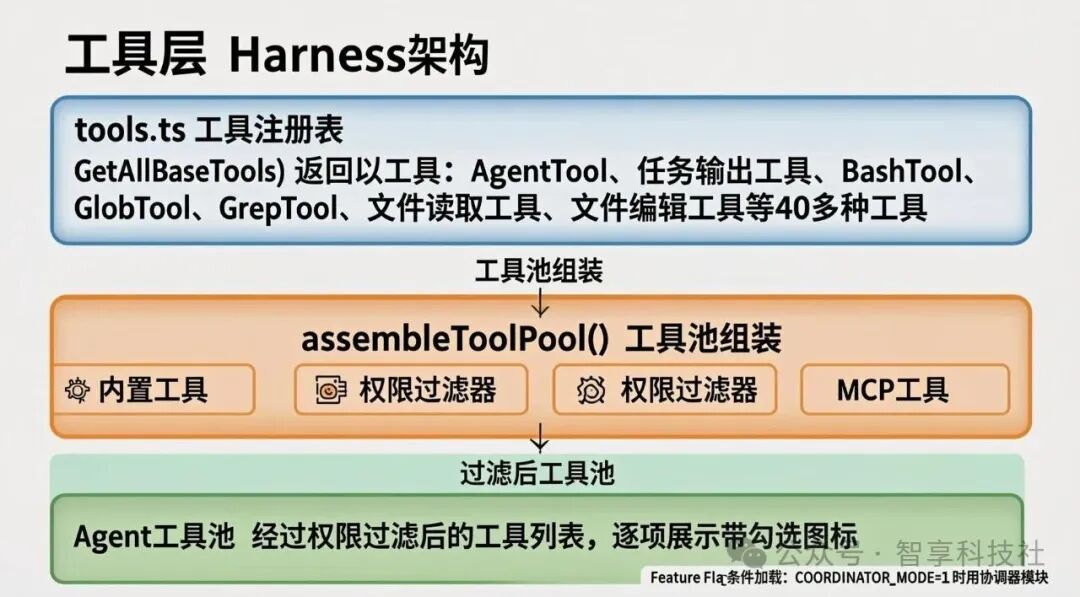
图:工具层通过注册表、动态组装和条件加载,实现对AI能力边界的精细控制。
权限层:为每一次工具调用装上“保险丝”
有了工具,下一步是决定AI以何种权限级别来使用它们。权限层 Harness 定义了清晰的权限模式,并对高风险操作(如 Bash 命令)实施了多层防护。
四种核心权限模式
Claude Code 定义了四种权限模式,用户可以在安全设置中切换,以适应不同的任务场景和信任级别。
type PermissionMode =
| 'default' // 用户逐个审批(默认安全模式)
| 'plan' // Plan模式下自动审批(用于只读规划)
| 'bypassPermissions' // 完全绕过(危险!仅限已知安全环境)
| 'auto' // 基于AI判断自动审批(高风险,需谨慎)
bypassPermissions 模式危险性最高,通常只在开发者明确知晓风险且处于受控环境(如本地沙箱)时才会启用。每次工具调用都会触发权限检查流程,这个流程由一个名为 useCanUseTool 的 React Hook 驱动。
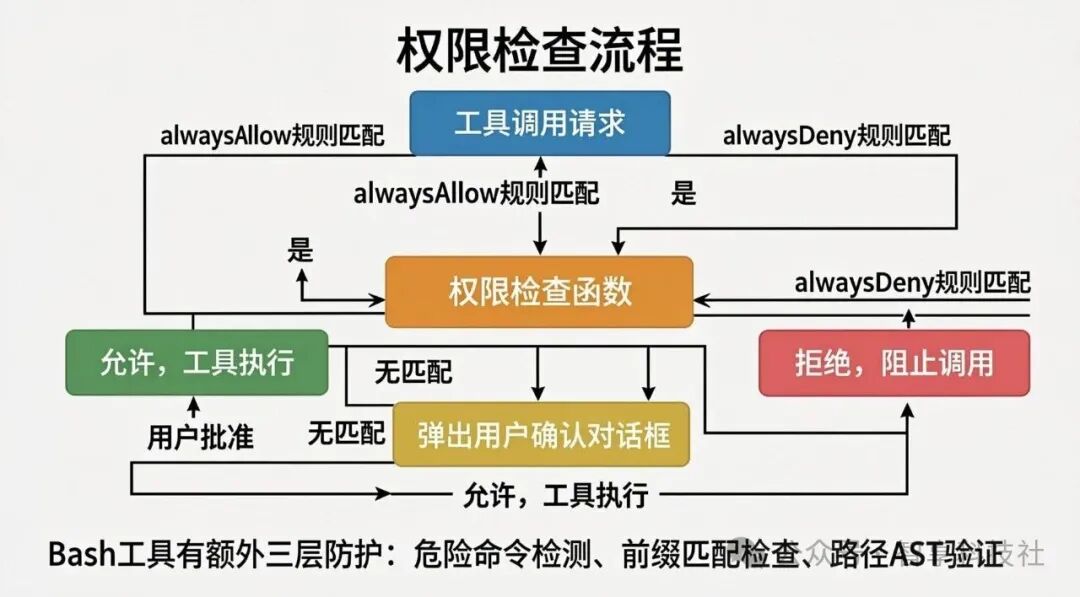
图:权限检查遵循明确规则,通过白名单、黑名单和用户确认三层机制保障安全。
BashTool 的多层安全防护
在所有工具中,BashTool 的安全设计最为复杂,因为它直接与系统 Shell 交互。其防护措施层层递进:
- 危险命令模式检测 (
bashSecurity.ts)
// 通过 Set 存储危险命令 baseCmd,实现 O(1) 时间复杂度的快速匹配
ZSH_DANGEROUS_COMMANDS.has(baseCmd)
- 前缀匹配与语义分析 (
bashPermissions.ts)
例如,命令 nice rm -rf / 的前缀是 “nice”,但核心语义仍然是执行 rm -rf /。系统会穿透命令包装器,识别其真实意图。
- 路径越界与 AST 验证 (
pathValidation.ts)
通过解析命令的抽象语法树 (AST),定位所有涉及文件路径的操作,并与用户指定的工作目录 (baseDir) 进行比对,有效防止路径遍历攻击(如 ../../../etc/passwd)。
Agent 层:从单兵到团队的“组织架构”
Agent 层是控制子代理行为边界的核心。Claude Code 提供了一套从轻量到重量、从简单到复杂的三层 Agent 架构。
第一层:Fork Subagent (隐式分叉)
当调用 Agent Tool 但不指定 subagent_type 时,会触发隐式分叉,创建一个轻量子 Agent。
export const FORK_AGENT = {
agentType: 'fork',
tools: ['*'], // 继承父 Agent 的精确工具池
permissionMode: 'bubble', // 权限弹窗回到父终端处理
model: 'inherit', // 继承父 Agent 的模型
};
此设计最精妙之处在于:子 Agent 不重新生成 system prompt。它直接继承父 Agent 已经渲染好的字节流。这避免了因系统状态切换导致的 prompt 内容不一致,也确保了服务端缓存的效率。
第二层:Built-in Agents (内置专用 Agent)
Claude Code 内置了多种专用 Agent,每种都有明确的角色和限制,是 最小权限原则 的典型体现。
| Agent |
类型 |
特点 |
适用场景 |
general-purpose |
通用 |
全功能读写 |
复杂多步骤任务 |
explore |
只读 |
快速并行搜索 |
“这个函数在哪被调用?” |
plan |
只读 |
制定实现计划 |
“如何重构这个模块?” |
verification |
只读 |
破坏性安全验证 |
“这个实现有没有安全漏洞?” |
claude-code-guide |
指南 |
用户引导与教学 |
新手入门 |
例如,Explore Agent 的 system prompt 中明确强调:
=== CRITICAL: READ-ONLY MODE - NO FILE MODIFICATIONS ===
This is a READ-ONLY exploration task.
You are STRICTLY PROHIBITED from:
- Creating new files
- Modifying existing files
- Deleting files
而 Verification Agent 则以“破坏性验证”为目标,其提示词旨在防止人类测试者常犯的两种错误:验证逃避(未经充分测试即通过)和被表象迷惑(因界面精美而忽略底层问题)。
第三层:Coordinator Mode (协调器模式)
当设置环境变量 CLAUDE_CODE_COORDINATOR_MODE=1 时,系统将启用完全自主的多 Agent 协同工作模式。这堪称一次激动人心的开源实战演练,展示了如何将单兵作战的AI升级为一个分工明确的团队。

图:三层架构清晰划分了能力模型、角色控制和监督控制。
在此模式下,充当“管理者”的 Coordinator Agent 负责任务分解、工作分配和结果汇总。而具体执行的 Worker Agent 则被严格限制了能力——它们只能使用一组内部通信工具,完全无法接触或操作用户的实际文件系统。
const INTERNAL_WORKER_TOOLS = new Set([
'TeamCreate', // 派发更多 Worker
'TeamDelete', // 删除 Worker
'SendMessage', // 发送消息
'SyntheticOutput', // 输出结构化结果
]);
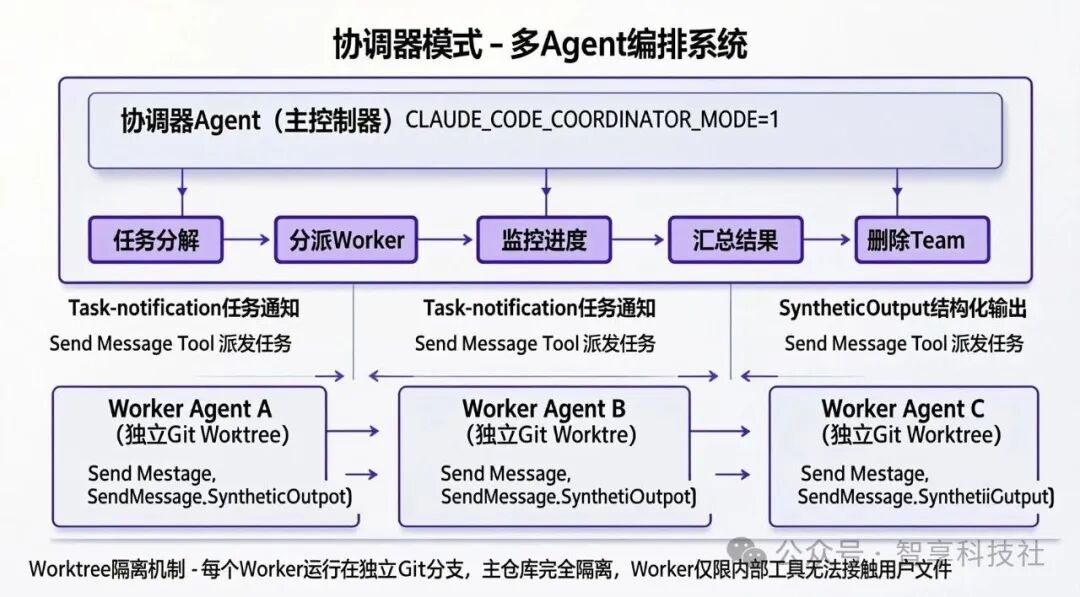
图:Coordinator 作为主控制器,通过消息驱动多个在独立 Git Worktree 中运行的 Worker。
其底层的 Git Worktree 隔离机制 是关键:每个 Worker 运行在独立的 Git 分支副本中,与主仓库完全隔离。这确保了并行任务间的绝对安全,一个 Worker 的失误不会污染其他 Worker 或主项目。
生命周期层:无处不在的“钩子”系统
Harness 的控制力不仅体现在运行时,也贯穿于 Claude Code 的整个生命周期。这通过一套灵活的 Hook 系统实现。
五大标准生命周期钩子
系统预定义了五个关键的 Hook 事件,允许开发者在特定时刻注入自定义逻辑。
export const HOOK_EVENTS = [
'PostToolUse', // 工具执行后触发(如记录日志)
'UserPromptSubmit', // 用户提交提示后触发(可拦截或修改输入)
'SessionStart', // 会话开始时触发
'SessionEnd', // 会话结束时触发
'Stop', // 用户主动中断时触发
];
两种 Hook 类型
处理程序可以是执行 Shell 脚本的命令型 Hook,也可以是执行 TypeScript 回调函数的函数型 Hook。
// 函数型 Hook 定义
type FunctionHook = {
type: 'function';
callback: (messages, signal) => boolean | Promise<boolean>;
timeout?: number;
errorMessage: string;
};
// 注册一个会话开始的 Hook
addSessionHook(
setAppState,
sessionId,
'SessionStart', // 事件类型
'before/*', // 匹配模式 (glob)
{ type: 'command', command: 'echo hello' }, // 处理程序
);
关键特性
- 会话级作用域 (Session-scoped):Hook 与特定会话绑定,会话结束后自动清理,不会残留影响后续会话。
- 并发安全设计:内部使用
Map 而非普通对象 (Record) 来存储 Hook 状态。当并行注册多个 Hook 时,Map.set() 是 O(1) 时间复杂度,而使用对象展开 (...spread) 的方式可能导致 O(N²) 的性能劣化。
// 并发优化设计
export type SessionHooksState = Map<string, SessionStore>;
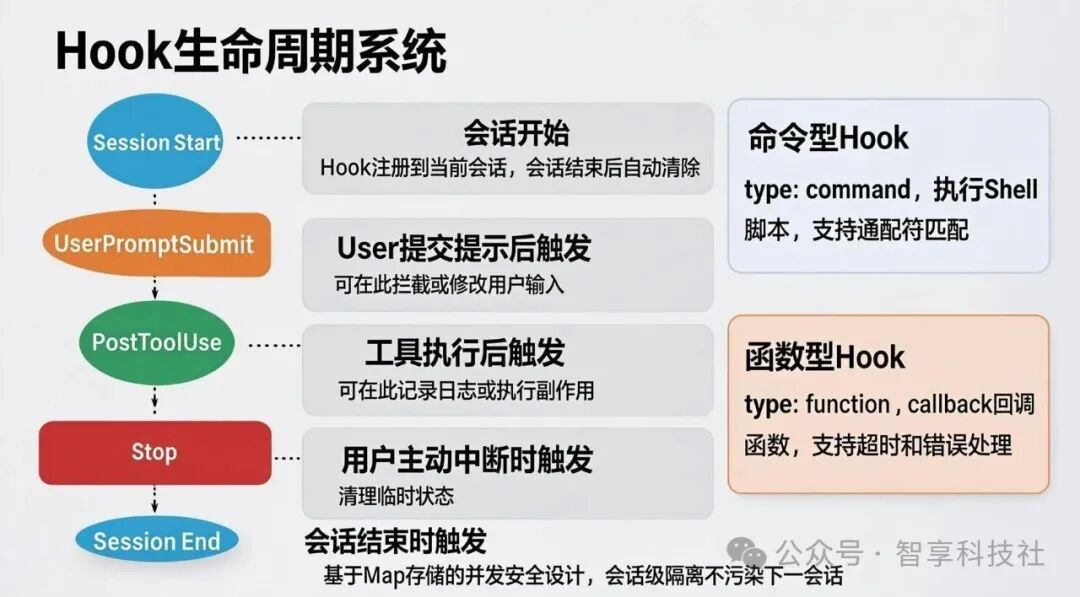
图:Hook 系统在关键生命周期节点提供干预能力,且设计为会话隔离和并发安全。
设计原则与工程哲学
透过这四层 Harness 设计,我们可以看到背后几个清晰的工程原则:
1. 最小权限原则 (Principle of Least Privilege)
这是安全基石,在每一层都有体现:
- 工具层:子 Agent 仅继承父 Agent 明确的工具池,不会获得额外权限。
- 权限层:
Explore、Plan 等 Agent 被物理移除了文件写入工具。
- Agent 层:Coordinator 模式下的 Worker 只有内部通信工具,与用户文件系统完全隔离。
2. 能力模型 (Capability Model)
权限不是通过检查“身份”来分配,而是通过持有不可伪造的“令牌”(即能力)来体现。Fork 子 Agent 持有的“令牌”就是父 Agent 渲染好的 system prompt 字节,它界定了子 Agent 的所有行为边界。
3. 隔离即安全
Git Worktree 隔离 提供了轻量级但极其有效的环境隔离。每个任务都在独立分支副本中运行,从根源上避免了状态污染和冲突。
4. 监督控制模式 (Supervisor Pattern)
Coordinator 模式本质上是经典的 Actor 模型和 Erlang/OTP 监督树理念的应用。Coordinator 作为 Supervisor,通过消息传递 (SyntheticOutput, SendMessageTool) 来管理和监控多个 Worker (Actor) 的生命周期,构成了一个健壮的后端与架构模式。
实战场景推演
理解了架构,我们来看看它在实际任务中如何发挥作用。
场景一:大型项目重构(如 Django 迁移到 FastAPI)
- 无 Harness:单个 AI 可能无序修改数百个文件,过程不透明,结果难以审查。
- Coordinator 模式:
Plan Agent(只读)制定详细的重构步骤和模块划分。Coordinator 将计划分解,创建多个 Worker,分别负责用户模块、路由模块、数据库模块的迁移。- 各
Worker 在独立的 Git Worktree 中并行工作,互不干扰。
Coordinator 汇总结果,自动检测合并冲突。- 开发者只需审查每个模块的最终 Pull Request,清晰可控。
场景二:批量代码审查(30个PR)
- 使用
Explore Agent 快速并行扫描所有 PR,定位关键代码变更和潜在模式。
- 对发现的高风险变更,启动
Verification Agent 进行破坏性测试(如注入异常数据)。
- 最终生成一份结构化的安全审查报告。
场景三:修复Bug并查找同类问题
- 在修复某个 Bug 后,立即
Fork 一个子 Agent。
- 子 Agent 继承完整的当前上下文(代码、报错信息),在独立分支上使用相同模式搜索代码库。
- 异步返回发现的多个同类问题,实现“修复一个,清扫一片”。
给开发者的启示
- 默认隔离:将隔离作为所有 AI 交互的默认前提。工具池、运行环境、代码上下文都应明确分离。
- 善用只读 Agent:
Explore、Plan、Verification 这三个只读 Agent 是“免费的保险”。在动手前先用 Plan 理清思路,用 Explore 了解现状,完成后用 Verification 进行验证。
- 渐进式采用:从简单的
Fork Subagent 开始,逐步过渡到使用内置专用 Agent,最后在复杂场景中尝试 Coordinator Mode。复杂度与自主性同步提升。
- 防御深度叠加:最稳固的安全来自多层次叠加。
Fork(能力模型) + Coordinator(监督控制) + INTERNAL_WORKER_TOOLS(能力限制)共同构成了一道既有灵活性(授权内自由行动)又有安全性(越界即可被终止)的防线。
Claude Code 的 Harness 工程展示了一条明确的路径:通过精心的系统设计,我们可以将强大的 AI 编码能力安全、可控地集成到真实的软件开发流程中。这不仅关乎安全,更关乎如何构建可靠、可协作的人机共生工作流。对于关注 人工智能 如何落地实践的开发者而言,其中蕴含的系统设计思想值得在 云栈社区 深入探讨和交流。
 发表于 2026-4-2 01:41:55
|
查看: 223|
回复: 0
发表于 2026-4-2 01:41:55
|
查看: 223|
回复: 0
